「AIコーディング、良さそうだけど数字で見せろ」と言われたら。GitHub Copilot metrics GAで始める5指標ROI報告術
「Copilot入れてから、開発速くなったよね?」
この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口
「AIで速くなった気がする」は、もう通用しない
「Copilot(コパイロット)入れてから、開発速くなったよね?」
チームのSlackで、そんな会話が増えた。私もそう感じていた。補完が効く。テスト生成も助かる。
でも上長から返ってきたのは、こうだった。
「気がする、じゃなくて数字で見せてくれない?」
正直、ぐうの音も出なかった。CS出身の私でも、導入効果を数字で語るのは基本中の基本だ。 なのに「なんか速い」で止まっていた。
そんな状態を変えてくれるツールが出た。 2026年2月にGA(一般公開)されたGitHub Copilot(ギットハブコパイロット) metricsだ。
4月2日には旧APIが廃止される。移行のカウントダウンは、もう始まっている。
この記事では5つの指標を「上司への報告フォーマット」に噛み砕く。「55%速い」と「19%遅い」の矛盾データにも向き合う。
ハマりポイントも先に共有する。私がかけた時間をショートカットしてほしい。
所要時間: 約12分。コード読まなくても理解できる。
4月2日に何が起きるのか。レガシーAPI廃止の中身
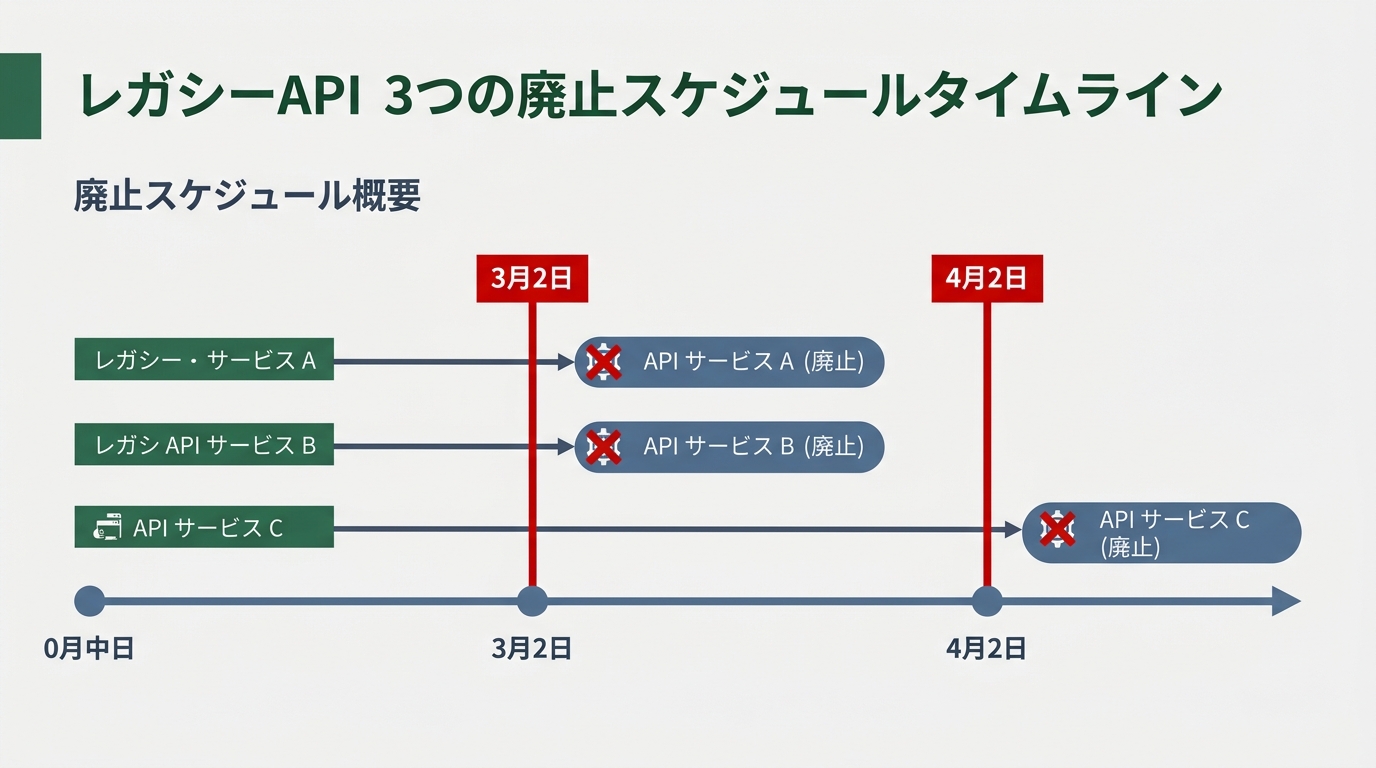
状況を整理する。2026年1月29日、GitHubが3つのレガシーAPIの廃止を告知した。
- Copilot Metrics API: 集計済みの利用統計。主にIDE操作のデータ
- User-level Feature Engagement Metrics API: ユーザーごとの機能利用状況。3月2日に先行廃止済み
- Direct Data Access API: コード補完のイベントログ。3月2日廃止済み
3つのうち2つはすでに使えない。残る1つが4月2日に消える。
「うちは関係ないかも」と思った方、確認してほしい。
MicrosoftがOSS(オープンソース、誰でも無料で使える形式)で公開しているダッシュボードがある。 copilot-metrics-dashboardだ。
これをフォークして社内利用しているチームは多い。レガシーAPIに依存しているので、4月2日でグラフが止まる。
移行先は新しいCopilot usage metrics APIだ。2月27日にGAされたやつ。
旧APIとの最大の違いは「エージェント利用」の追跡ができる点。 Agent Modeの利用も計測可能になった。旧APIにはなかった視点だ。
ハマりポイントを先に言っておく。旧APIと新APIではデータ構造が違う。エンドポイントのURLも異なる。
/copilot/usageが旧、/copilot/metricsが新だ。
単純なURL差し替えでは動かないケースがある。
公式ドキュメントで移行手順を確認してほしい。
5つの指標を「上司に見せる形」に変換する
新しいダッシュボードでは、5カテゴリで数値が取れる。それぞれを「上司に何を伝えるか」で翻訳した。
指標1: Adoption(導入浸透率)
ライセンス保有者のうち、何人が実際に使っているか。DAU(日次アクティブ率)まで見られる。
上司への変換: 「50ライセンスのうち38人が毎日使っています。稼働率76%です」
SaaS(月額課金型のクラウドサービス)の平均稼働率は約50%。 大幅に超えているなら、ROIラインはクリアだと説明できる。
Accentureの導入事例だと、導入開発者の67%が週5日以上使っている。「買ったけど使われてない」が起きにくいツール。
指標2: Code Generation(コード生成量)
AIが提案した行数、受け入れた行数、コミットされた行数。補完・Chat・Agentそれぞれで追跡できる。
上司への変換: 「Copilot提案コードの30%が採用されました。テスト生成で特に貢献しています」
GitHub社の公開データだと、開発者のコードの約46%がCopilot経由。 2022年の27%から伸びた。Javaでは61%に達する。
指標3: Agent Usage(エージェント利用)
これが新APIの目玉。ChatとAgent Modeの利用比率を追跡する。旧APIには存在しなかったデータだ。
上司への変換: 「Agent Mode利用が先月から3倍に増えました。次のフェーズとしてガイドライン整備を提案します」
指標4: PR Throughput(PR処理速度)
PR(プルリクエスト=コードの変更提案)の作成数、マージまでの中央値、レビュー活用率。 Copilot支援PRとそれ以外を比較できる。
上司への変換: 「Copilot支援PRのマージは平均4.2時間。非支援PRは6.8時間です」
差の2.6時間×チーム人数が月間の工数削減量になる。 Accenture事例ではPR数+8.69%、マージ率+11%を記録した。ビルド成功率は+84%。

指標5: Acceptance Rate(提案受入率)
Copilotの補完提案に対して、何%を受け入れたか。業界平均は約30%。
上司への変換: 「受入率が低いチームは設定に改善余地あり。高すぎるチームはレビュー不足の可能性があります」
この指標は「高ければいい」わけじゃない。異常に高い場合、AI提案を無批判に受け入れている可能性がある。
GitClearのレポートが参考になる。 AI支援コードのチャーン率(すぐ書き直される率)の増加が報告されている。品質とのバランスが大事だ。
「55%速い」と「19%遅い」。どっちが本当なのか
避けて通れない話をする。AIコーディングの生産性データには、有名な矛盾がある。
ベンダー側の主張: GitHub/Microsoftの実験では、タスク完了が55.8%速くなった。
独立研究の結果: AI安全性研究機関METRが2025年7月にRCT(ランダム化比較試験)を発表。 経験豊富な開発者の生産性は19%低下していた。
正反対の結果。どちらを信じるべきか。
答えは「どちらも正しい。ただし条件が違う」。
ベンダーの実験は孤立したタスクで測定された。関数を1つ書く、テストを生成する。こうした限定作業ではAI補完が強力に効く。
METRの実験は違った。16人の経験豊富なOSS開発者が対象だ。 自分が長年メンテしているリポジトリで、246個の実タスクに取り組んだ。
バグ修正・機能追加・リファクタリング。コードベースを熟知した開発者にとっては、AI出力の確認コストが節約分を上回った。

もっと面白いデータがある。METR実験の開発者は「自分は20%速くなった」と感じていた。実際は19%遅くなっていたのに。
体感と実測のギャップ。これが存在する。
「速くなった気がする」では報告にならない理由がここにある。metrics APIで実測すべき根拠はこれだ。
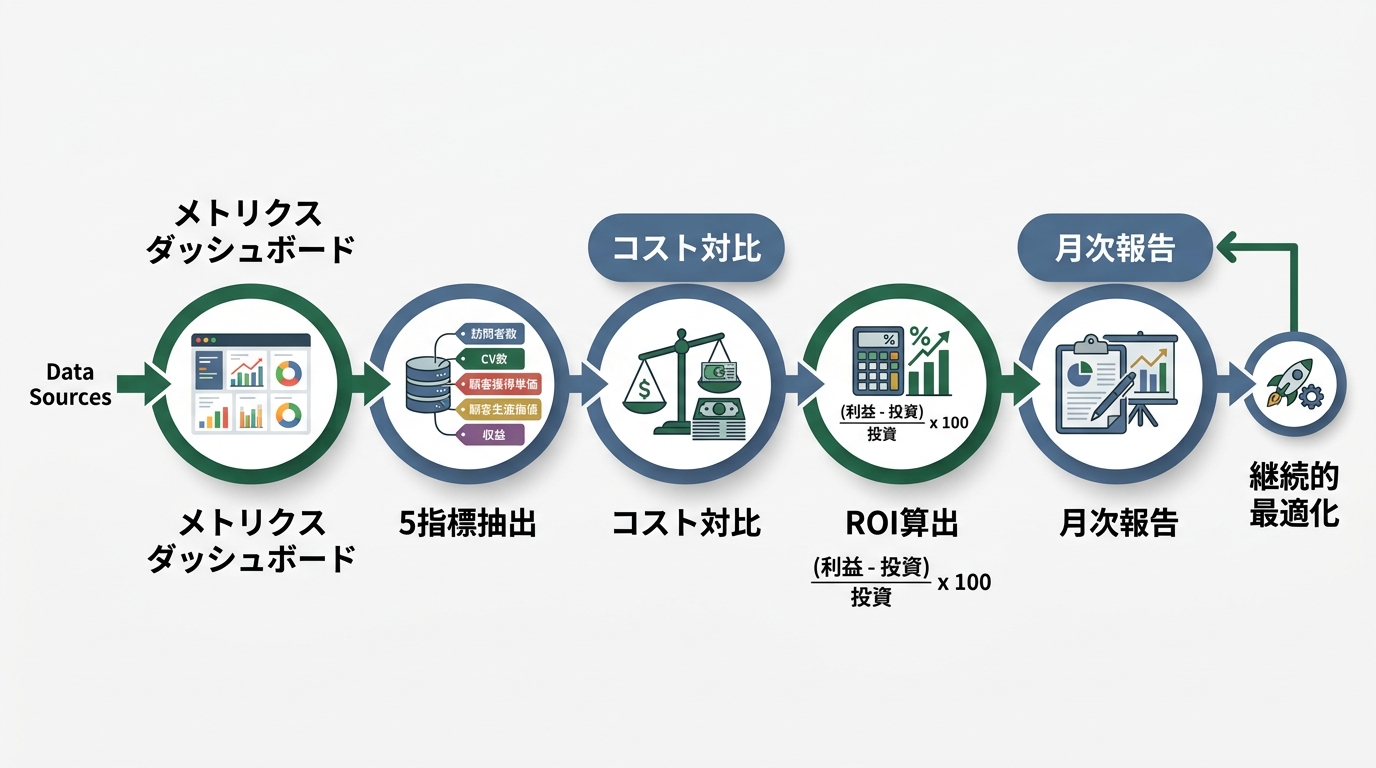
私が組んだROI報告テンプレート
ここからは実務の話。metricsデータを経営層が理解できる形に落とし込む。
# Copilot ROI 月次報告テンプレート
## 1. コスト
# Business席 $19/月 × チーム人数
# Enterprise席 $39/月 × チーム人数
monthly_cost = unit_price * team_size
## 2. 時間削減効果(PR Throughputから算出)
# Copilot支援PR平均マージ時間 vs 非支援PR平均マージ時間
# 差分 × 月間PR数 = 月間節約時間
time_saved_hours = (non_copilot_merge_hrs - copilot_merge_hrs) * monthly_pr_count
## 3. 人件費換算
# 節約時間 × エンジニア時給
value_generated = time_saved_hours * hourly_rate
## 4. ROI
# (人件費換算 - ライセンスコスト) / ライセンスコスト × 100
roi_percent = (value_generated - monthly_cost) / monthly_cost * 100ポイントは1つ。ダッシュボードから直接取れる数値だけで計算している。感覚値が一切入らない。
上長が「根拠は?」と聞いてきても、スクショを見せればいい。
CS出身だからわかる。社内稟議で最も嫌われるのは「定性評価のみ」の報告書だ。
「開発者が満足しています」は決裁権者に響かない。「月40時間の工数削減、年間約480万円相当」なら稟議が通る。
Accenture事例ではビルド成功率+84%を記録。 「手戻りの減少」を意味する数字で、間接効果としてROIに含められる。
Duolingoの事例も参考になる。 コードに不慣れな開発者の速度が+25%向上した。レビュー所要時間は中央値で67%短縮(9.6日→2.4日)。
オンボーディングコスト削減として計上できる数字だ。
「経営報告できる形にする」ための3つの注意点
数字が取れるようになると嬉しくなる。でも報告資料に落とす時、3つの落とし穴がある。
注意点1: ベースライン測定を先にやる
Copilot導入前の数値がないと比較ができない。「速くなった」と言いたければ「前はこうだった」が必要になる。
すでに全員に配布済みなら、一部チームで一時オフにする方法もある。ただし開発者の反発は覚悟してほしい。
注意点2: 受入率だけで判断しない
受入率30%は「70%が無駄」という意味ではない。提案を見て判断する行為がコードレビューの一種として機能する。
数字だけで「効率が悪い」と判断すると本質を見誤る。
注意点3: セキュリティコストを織り込む
AI生成コードには、人間のコードと異なるパターンの脆弱性リスクがある。
metricsの数値だけでROIを計算すると、セキュリティレビューの追加コストを見落とす。
ガバナンスなしだとイシュー件数が約1.7倍に増加した報告もある。
「速くなった分、レビューも増える」と理解しておくのが安全だ。
まとめ: 「数値で語る道具」は揃った
Copilot metricsのGAで、AIコーディングの効果測定は新フェーズに入った。 「できる人がやる」から「仕組みとして回す」への転換だ。
4月2日のレガシーAPI廃止は移行タスクであり、問い直しの契機でもある。「そもそも測定してましたか?」
振り返ると、Copilotを初めて触った時は「速い、すごい」で終わっていた。 CS時代に導入効果レポートを散々書いてきたのに、自分のツールになると甘くなる。
数字で語る習慣は、意識して守らないと消える。
今日の5指標を整理する。
- Adoption: ライセンスの稼働率。使われてないなら対策を打つ
- Code Generation: AIの貢献量。言語・タスク別の分析
- Agent Usage: Chat→Agentへの移行度
- PR Throughput: 最も直接的なROI変換ができる指標
- Acceptance Rate: 提案の質。高すぎても低すぎても注意
「55%速い」を鵜呑みにするのも、「19%遅い」で諦めるのも違う。自分のチームの数値を測って、自分のROIを計算する。
道具はもう揃っている。あとは、やるかどうかだけだ。
出典
- Copilot metrics is now generally available - GitHub Changelog
- Closing down notice of legacy Copilot metrics APIs - GitHub Changelog
- REST API endpoints for Copilot metrics - GitHub Docs
- Data available in Copilot usage metrics - GitHub Docs
- Research: Quantifying GitHub Copilot’s Impact with Accenture - GitHub Blog
- METR AI Developer Productivity Study
- METR study on arXiv

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。