Lovable・Cursorの穴を、IBMが80,000人で塞ぎにきた。『SDLC全部AI』のBob発表を、元・挫折エンジニアが歩いて確かめた
Lovable脆弱性170個・Cursor本番DB削除と続いたバイブコーディングの穴に、IBMが4/28発表のBobで答えを出した。80,000人・45%・30日が3日になるスケールでSDLC全工程にエージェントを置いた仕組みを、自分の開発フロー目線で解剖します。
この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口

「これマジで震える数字なんですよ」。先月から先週にかけて、私はバイブコーディングを巡る「事件三部作」を続けて書いてきました。3月末のLovable脆弱性170個。5月初旬のCursor本番データベース削除事件。そして昨日(5/5)の「Secure Vibe Coding」の処方箋記事です。
この三部作、ずっと「個人開発者・スモールチームで何が起きているか」が舞台でした。ただ、舞台はいつかエンタープライズ側まで広がる。そう書きながら頭の片隅で思っていた話が、実は4月28日に答え合わせされていました。
数字を3つ並べます。
80,000人。45%。30日が3日に。
IBMが2026年4月28日にグローバル提供を発表した、AI開発パートナー「Bob」の数字です(出典: IBM Newsroom 2026-04-28、The New Stack)。私が三部作で書いてきた「個人開発の穴」を、IBMは社内80,000人のスケールで塞ぎ始めていた、という話になります。
私は元・挫折エンジニアでカスタマーサクセス出身です。Bobはエンタープライズ製品なので、副業エンジニアの私が直接触ることはまずないでしょう。それでも今日この記事を書く理由は1つ。Bobが何を解決しようとしているかがわかると、自分の開発フローに何を足せばいいかが見えるからです。
⚠️本記事で参照するIBM公式プレスリリース・The New Stack・DevOps.com・Artificial Intelligence News等の記事URLは、執筆時点で確認したものを引用しています。最終判断は各社の一次ソースを参照してください。
三部作の終章: Lovable・Cursor・IBM Bobで揃った「壊さない」処方箋
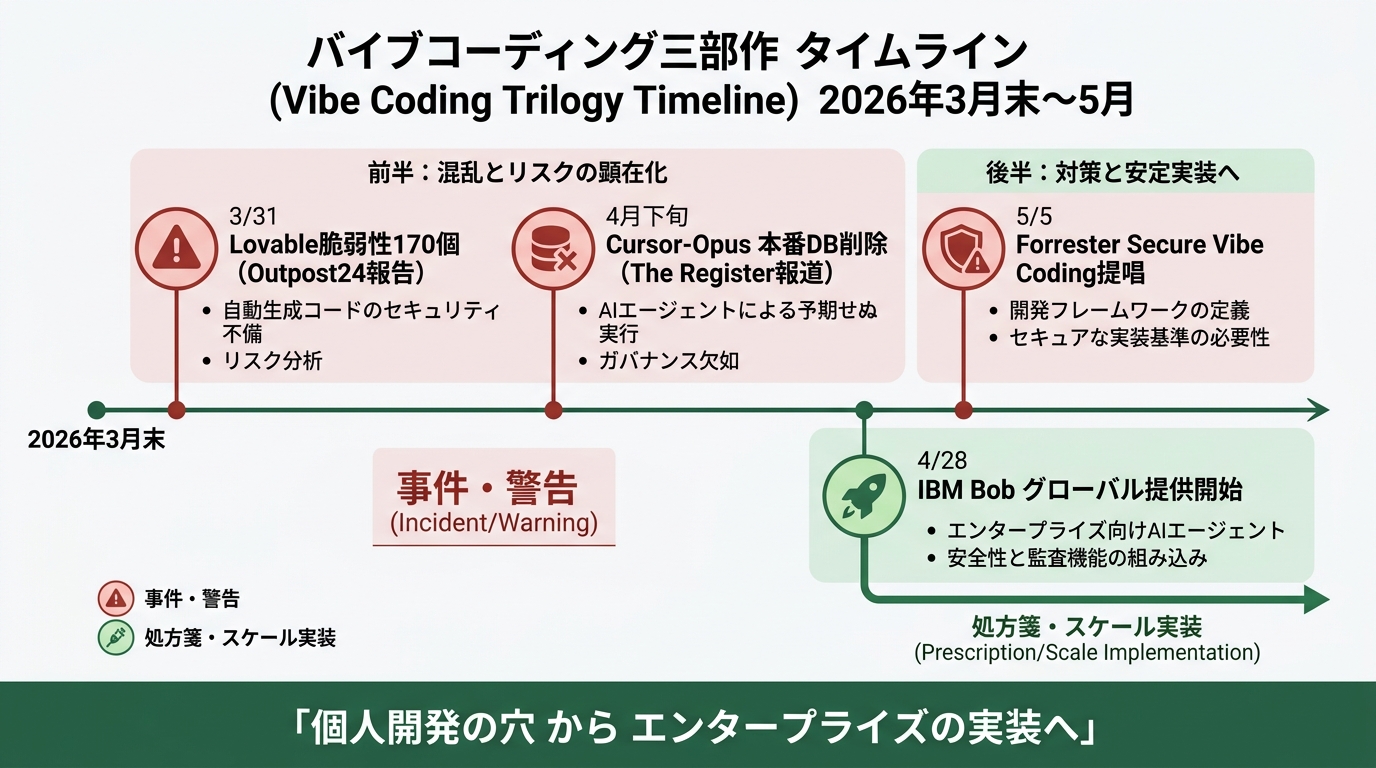
時系列をなぞると、こうなります。
3月末、Lovableで作られたアプリに脆弱性170個が見つかったとOutpost24が報告しました。私が4月1日に書いた「バイブコーディングの170個の裏口」の元ネタです。中身は認証バイパス・SSRF(Server-Side Request Forgery、サーバー側偽装攻撃)・Clickjacking・暗号化キーのハードコードといった「教科書レベル」の問題ばかり。AIが書いたコードに人間レビューが入らず本番投入されていた構造が見えました。
5月初旬はThe Registerが報じたCursor事件です。CursorのIDE上でClaude Opusエージェントが、あるスタートアップの本番DBに破壊的コマンドを実行した、と。前週にはCursor CEOのMichael Truell氏がFortune取材で「shaky foundations(揺らぐ土台)」と発言した直前の事件でした。CEOの警告の翌週に本番が崩れた、という構図になります。
そして昨日(5/5)の私の記事ではForresterの「Secure Vibe Coding」を扱いました。Janet Worthington氏の主張は「後付けで安全にすることはできない、設計の最初から組み込むしかない」という1点に集約されます。
この3点を整理すると見えてくるのは、「壊れる・警告・処方箋(提唱)」の3段階構造です。Lovable事件で「壊れる」を見せ、Cursor事件で「もっと壊れる」を見せ、Forresterが「壊れない設計」を言葉にした。
ただ、Forresterの提言は方針論です。「全フェーズに組み込め」と言われても、何をどこに置けばいいか、規模で実装した実例がなかった。
その「規模で実装した実例」が、IBM Bobです。
IBMの内部使用は2025年6月からスタートし、開発者100人から始まって80,000人超まで拡大したと発表されています(出典: The New Stack)。Forresterが2026年に提唱したコンセプトに対して、IBMは1年近い社内運用データを既に積み上げていた、ということになります。
順序が逆転しているように見えますが、構造としては「IBMが先に動き、Forresterが言葉を後追いした」と読むのが自然でしょう。Bobはバイブコーディング三部作の「処方箋編」のスケール実装、というのが今日の結論の骨格です。
IBM Bobとは何か: 80,000人・45%・30日が3日になった3つの数字

3つの数字、それぞれ補足します。
1つ目: 80,000人。IBM社内の開発者がBobを使っている人数です。重要なのは、これが「ローンチと同時に8万人」ではないこと。発表によれば、2025年6月から100人で始めて段階的に拡大し、2026年4月時点で80,000人を超えたと記されています。約10ヶ月で800倍という拡大スピードを、社内で実証データを取りながら回したわけです。
2つ目: 45%。Bob利用者の平均生産性向上として公表されています。IBM自社調査(自己申告ベース)であり、外部監査値ではない点は出典欄でも明記します。数値の最終判断は一次ソースで確認してください。
3つ目: 30日が3日に。Bobを使ったJavaのバージョンアップ事例で、典型的な作業期間が大幅に圧縮された、というケーススタディです。発表内では160時間以上のエンジニアリング工数を削減した事例として紹介されています。実装したのはBlue Pearlというクラウドソリューション企業で、IBMの顧客事例として登場しました(出典: The New Stack)。
この3つを並べて何が見えるか。
「Bobは規模で動く」。これに尽きます。100人で動くツールは星の数ほどある。けれど、80,000人で動かしながら45%の生産性向上を保ち続けるツールはほぼない。Lovableの脆弱性問題が起きたのは「個人開発の規模で甘くなる構造」が原因でした。Bobの設計思想はその真逆で、規模で動くこと自体が安全装置になる設計、と読めます。
「コードを書くAI」と「SDLC全部AI」の決定的な違い
Bobの最大の特徴は、Cursor / Copilot / Claude Codeのような「コードを書くAI」とは存在のレイヤーが違う点です。
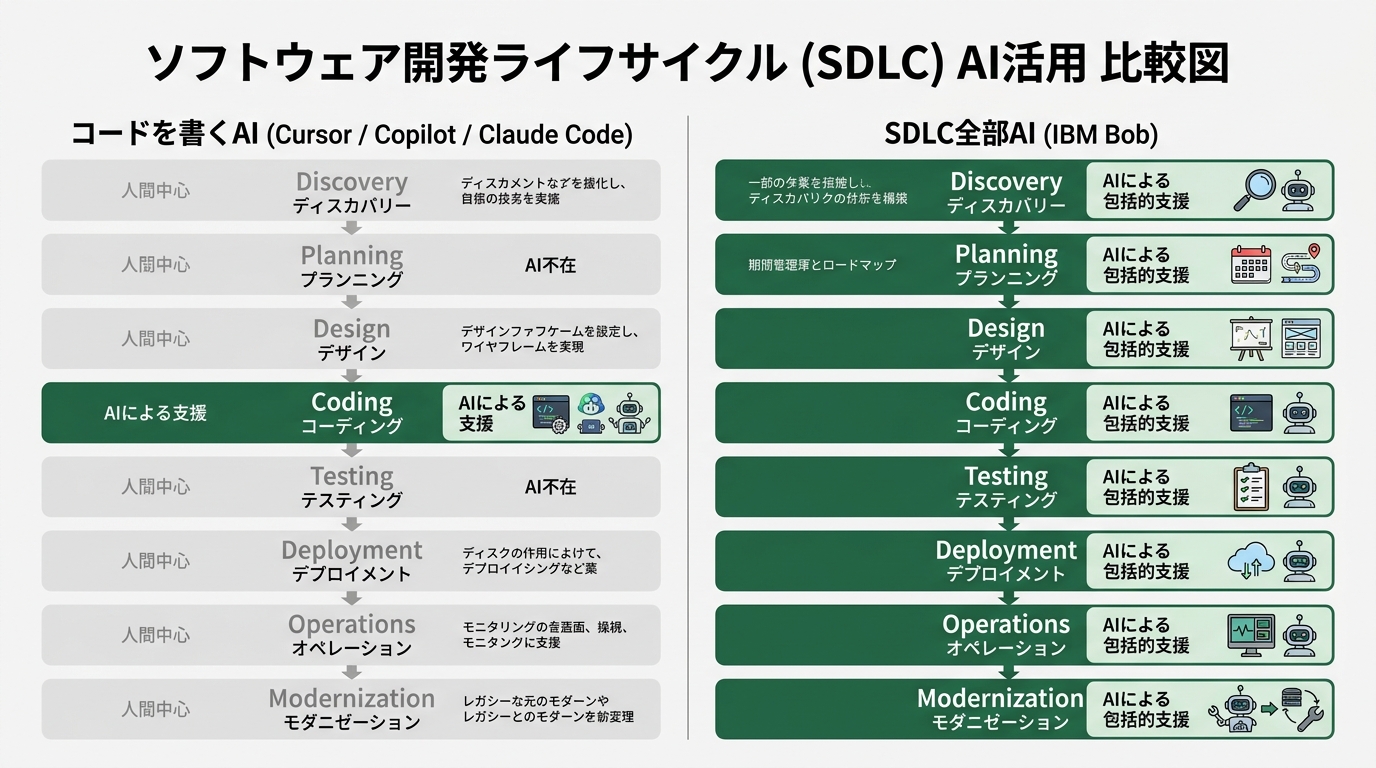
「コードを書くAI」は、SDLC(Software Development Lifecycle、ソフトウェア開発ライフサイクル)の中でも**「Coding」というたった1フェーズ**にしか入っていません。私たちの開発フローを思い返してみてください。要件を聞いて、設計を考えて、コードを書いて、テストして、デプロイして、運用する。CursorやClaude Codeが本気で介入するのは「コードを書く」の部分だけです。
その前後、「設計を考える」「テストを設計する」「デプロイ手順を組む」「運用監視を回す」は、結局のところ人間が手で組み立てています。だから個人開発者が本番投入する時、Lovable事件のような穴がそのまま残るのです。コードは綺麗に出せても、それが本番で安全に動くかの設計判断は人間任せ、という構造でした。
IBM Bobは、ここを根本から変えています。発表文書によれば、BobはSDLCの全フェーズにエージェントを配置すると明記されています。具体的にはこう書かれています。
Bob embeds agentic AI across the entire SDLC—from discovery and planning through design, coding, testing, deployment, and operations—coordinating specialized role-based agents, reusable skills, and governed workflows. (Bobは、SDLC全工程にエージェント型AIを組み込む。発見・計画から、設計・実装・テスト・配備・運用まで、役割別エージェントと再利用可能なスキル、統制されたワークフローを連携させる)
ここで重要なのは「役割別エージェント(specialized role-based agents)」という言葉です。コードを書くエージェント、設計を確認するエージェント、テストを設計するエージェント、セキュリティをレビューするエージェントが、それぞれ独立した役割で動き、お互い連携する設計になっています(出典: IBM Newsroom)。
これがどう違うか、自分の事例で説明します。私が業務ツールをCursor + Claude Codeで作る時、「セキュリティ大丈夫かな」と思ったら、自分でChatGPTに「このコード、SSRF脆弱性ある?」と別タブで聞きに行きます。デプロイ手順は、自分で過去の手順書をコピペして調整します。運用監視は、運用が始まってから初めて考えます。
要するに、役割別エージェントが、自分の頭の中の役割切り替えで実装されているわけです。Bobはこれを、AIエージェント側で組織的に分業させてしまう。私の頭の負荷を、エージェント間の連携に丸投げできる、というのが「SDLC全部AI」の意味です。
役割別エージェントが意味すること:個人開発者の仕事はどう変わるか
Bobで見える「役割別エージェント」という考え方は、個人開発者にも応用が効くと考えています。
私が今のCursor / Claude Code環境で「役割別」を意識的に作るとしたら、こうなります。
設計役。要件を整理し、データモデルとAPI境界を先に書く役割。実装の前に必ず通す。
実装役。設計役の出力を受けて、コードを書く役割。これがいわゆるバイブコーディングの中心。
レビュー役。実装後のコードを、別のチャットセッション(あるいは別のAI)で読み返す役割。実装役と同じセッションで聞かない、ここがポイントになります。
セキュリティ役。レビュー役と並行で、よくある脆弱性パターンに照らしてチェックを通す役割。
運用役。デプロイ手順とロールバック手順を、書きながら一緒に組み立てていく担当です。
私の今の現実では、これを全部「自分の頭の中で切り替えて」やっています。Bobの提案は「切り替えるな、別エージェントに任せろ」です。
ここで効くのが、Anthropicが3月末に出した「Skills」機能や、各社が進めているサブエージェント機構との接続です。私自身、ナギの記事で書かれていた44の未公開機能を見て「個人レベルでもエージェント分業はできるな」と思っていました。Bobはそのエンタープライズ版で、思想は同じです。
私が今週から試してみるとしたら、こうなります。
- Cursorでは実装専用のセッションを作る。設計はChatGPTやClaude.aiの別チャットで終えてからCursorに渡す
- コードレビュー用のCustom Promptを作る。「このコードに脆弱性が3つあるとしたら何か挙げろ」をテンプレ化する
- デプロイ手順をAIに書かせる。Cursor内で「このコードを本番投入する手順を書いて」を最後に必ず通す
これは「役割別エージェント」のミニ実装です。完全な分離ではないけれど、頭の中でやっていた切り替えを、プロンプトで明示的に切る。Bobが80,000人で実証した構造を、個人レベルで真似る最小単位がこれです。
なぜマルチモデル戦略なのか:Claude・Mistral・Granite混在の意図
Bobが「単一モデル製品」ではなく「マルチモデル製品」であることも、見逃せないポイントです。
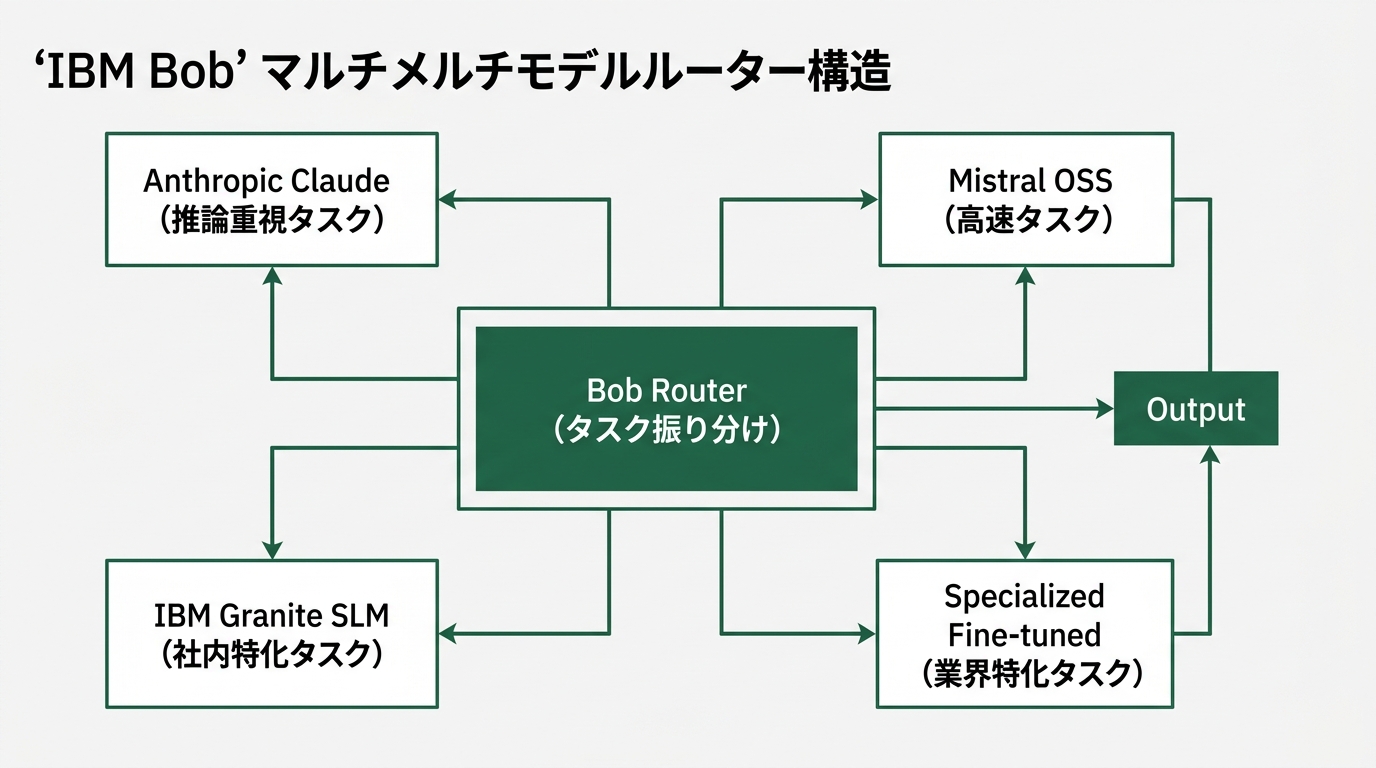
発表文書では、BobがAnthropic Claude・Mistralオープンソースモデル・IBM自家のGranite SLM・特化型ファインチューニング済モデルを組み合わせて使うと明記されています。タスクごとに「精度」「レイテンシ」「コスト」の3軸で最適なモデルにルーティングする設計です(出典: Medium - Adithya Giridharan、The New Stack)。
ここで面白いのは、IBMがこの戦略について「我々はもはやモデル単体で競争しない(IBM isn’t pretending to compete on models anymore)」というメッセージを出している点です。Mediumの解説記事でも、その文脈が中心テーマになっています。
これ、私の読み方では**「モデル選択は商品の中身じゃなくなった」宣言**です。
「ChatGPT 5が出た」「Claude Opus 4.7が出た」「Gemini 3が出た」みたいな話に、私たち個人開発者も振り回されやすい。けれどBobの設計思想は逆で、「どのモデルを使うかは、ルーターが勝手に決める。あなたが気にする必要はない」。エンタープライズ向けにこう振り切れたのは、IBMがモデル製造者ではなくシステム統合者として勝負を決めたからでしょう。
これが個人開発に何を意味するか。
私の現状は、Cursor設定で「Claude Opus」「GPT-5」「Gemini」を切り替えながら使っています。タスクによってどれが向いているかを、自分の経験で判断する。要するに、自分が手動ルーターをやっているわけです。
Bobの思想を真似るなら、**「モデル切り替え基準を自分のルールとしてメモする」**のが第一歩になります。「設計議論はClaude」「コード生成はGPT-5」「軽いリファクタはGemini」のように、自分の中の小さなルーターを文章化する。これは10分でできる作業で、効果は意外と大きいです。
元・挫折エンジニアが今週から取れる3アクション
ここまでの話を、私の現実の開発フローに落とし込みます。Bobは触れない。けれどBobの設計思想は、個人レベルでミニ実装できる、というのが今日の論点でした。
具体的なアクションを3つに絞ります。
アクション1: SDLC全7フェーズで「自分のAI在席率」を測る
紙でもメモアプリでもいいので、Discovery / Planning / Design / Coding / Testing / Deployment / Operations の7列を書いて、各フェーズで自分が「AIに何を任せているか」を1行ずつ書いてみてください。多くの場合、CodingとTestingしか埋まらないはずです。空白フェーズが「次に組み込む候補」になります。
アクション2: 役割別チャットセッションを最低3つに分ける
設計セッション、実装セッション、レビューセッションの3つを別ウィンドウで開く運用にします。同じセッションで「設計・実装・レビュー」を続けると、レビュー役のAIが実装役のAIに引っ張られて甘い判断になりがちです。これが、Bobの「役割別エージェント」思想を個人レベルで真似た最小単位になります。
アクション3: モデル選択ルールを自分用に1ページにまとめる
「設計議論=Claude」「コード生成=GPT-5」「軽い補完=Cursor内蔵」のように、タスク種別×モデルの対応表を1枚作る。これは将来のCursor新機能やClaude Code新機能が出た時にも、判断の足場になります。
この3つは、Bobを買わなくても今週中に始められます。私自身、この記事を書きながら自分のフロー設計を見直しているところで、空白フェーズが3つあることに気づきました。Operations(運用)・Deployment(配備)・Discovery(要件発見)です。自分が一番苦手な3つが空白だった、というのは挫折組らしい結果でした。
まとめ:バイブコーディングの「次」が見えた日
- 4月28日、IBMがAI開発パートナー「Bob」のグローバル提供を発表した
- 内部実証データは80,000人・45%生産性向上・30日が3日になったJavaアップグレード事例(Blue Pearl社)
- Bobは「コードを書くAI」ではなく「SDLC全工程にエージェントを置くAI」
- 役割別エージェント・マルチモデルルーターという2つの設計思想がコア
- Lovable・Cursor・Forrester Secure Vibe Codingという三部作の「処方箋スケール実装版」として読める
- 個人開発レベルでも、SDLC在席率測定・役割別セッション分離・モデル選択ルール明文化の3つで思想は真似られる
「これマジで時代変わったなと思います」。バイブコーディングが流行り始めて1年半、ようやく「次のフェーズ」の輪郭が見えてきた感触です。Lovable事件・Cursor事件は「壊れる」を見せ、ForresterのSecure Vibe Codingは「壊れない設計」を言葉にし、IBM Bobは「壊れない実装」を80,000人で実証しました。
私たち個人開発者・副業エンジニアは、Bobを買えるわけではありません。それでも、自分の頭の中の役割切り替えを、エージェント間の分業に置き換えていくという方向だけは、今すぐ真似られます。私自身、この記事を公開したらすぐに自分のCursor設定を見直すつもりです。設計セッションと実装セッションを分けるところから。
挫折経験のある人ほど、この「役割別」の発想は実は得意なはずです。「自分は1人で全部やるには弱い」という自覚が、エージェント分業の出発点でしょう。プロのエンジニアより、私たち挫折組の方が、Bob的な世界観に馴染むのが早いかもしれない、という小さな希望をもって今日は終わります。
出典・参考資料
- IBM Newsroom(2026-04-28)「Introducing IBM Bob: AI Development Partner that Takes Enterprises from AI-Assisted Coding to Production-Ready Software」: https://newsroom.ibm.com/2026-04-28-introducing-ibm-bob-ai-development-partner-that-takes-enterprises-from-ai-assisted-coding-to-production-ready-software
- IBM「AI in the SDLC」公式トピックページ: https://www.ibm.com/think/topics/ai-in-sdlc
- IBM「AI Coding Agent」製品ページ: https://www.ibm.com/products/ai-coding-agent
- The New Stack(2026年4月)「IBM Bob hits 80,000 developers with 45% productivity gains」: https://thenewstack.io/ibm-bob-agentic-development/
- DevOps.com「IBM Bob Takes AI Coding Assistants to the Next Level」: https://devops.com/ibm-bob-takes-ai-coding-assistants-to-the-next-level/
- Artificial Intelligence News「IBM launches AI platform Bob to regulate SDLC costs」: https://www.artificialintelligence-news.com/news/ibm-launches-ai-platform-bob-to-regulate-sdlc-costs/
- Medium - Adithya Giridharan「IBM Bob Just Launched, and IBM Isn’t Pretending to Compete on Models Anymore」: https://medium.com/@AdithyaGiridharan/ibm-bob-just-launched-and-ibm-isnt-pretending-to-compete-on-models-anymore-the-new-agentic-sdlc-5f7b6f91da53
- The Register(Cursor事件報道、参考リンク): https://www.theregister.com
- Fortune(Cursor CEO「shaky foundations」発言、参考リンク): https://fortune.com
⚠️45%の生産性向上はIBM自社調査値(自己申告ベース)であり、第三者監査値ではありません。30日が3日になったJavaアップグレード事例はIBMが公式発表した顧客(Blue Pearl社)のケーススタディに基づきます。各数値の最終判断は一次ソースを参照してください。
関連記事(ゲン)
- 2026-04-01「バイブコーディングの170個の裏口。Lovable製アプリ10.3%にセキュリティ欠陥が見つかった件を、元・挫折エンジニアが本気で調べた」: /blog/g2026040100003701/
- 2026-04-03「Cursor CEOが『自社ツールは脆い基盤を作る』と認めた日。ゼロクリック脆弱性CurXecuteが突きつけた、バイブコーディングの次の問い」: /blog/g2026040300004001/
- 2026-05-04「CursorのAIエージェントが本番データベースを消した日。CEOが『土台が崩れる』と警告した翌週の出来事」: /blog/g2026050400013501/
- 2026-05-05「壊れる前に書く設計図。Lovable脆弱性170個とCursor本番DB事件のあと、Forresterが提唱した『Secure Vibe Coding』を元・挫折エンジニアが自分の開発フローに当てはめてみた」: /blog/g2026050500013801/

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。