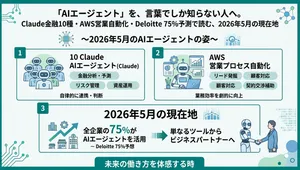
この記事でわかること
- AIエージェントという言葉の意味を、実例ベースでどう捉えるか
- いまの仕事に置き換えたとき、どこから使い始めるとよいか
- 次に読むべき関連記事が、料金・導入・全体像のどこにあるか

「AIエージェントって、結局どこまで任せていいんですか?」
この質問に対する僕の答えは、半年前と今で大きく変わりました。半年前は「まずはタスク単位で試してみましょう」と言っていた。でも今は違います。
2026年3月、Harvard Business Review(HBR)がある提言を掲載しました。「AIエージェントをチームメンバーとして扱え」という主張です。タスクを投げて結果を受け取る「ツール」ではない。役割と権限を持つ「チームの一員」として設計せよ、と。
同時期にGartner(ガートナー)が発表した数字も衝撃的でした。エンタープライズ企業の40%がAIエージェントを本番環境で稼働させている(Gartner)。2025年初頭は5%。わずか1年で8倍に跳ね上がった計算です。
40%が本番投入している。残り60%はまだ踏み出せていない。その差を分けているのは、技術力ではなくリスク管理の設計力です。
「AIエージェントを入れたら失敗した」という話の9割は、技術の問題ではありません。リスク管理の設計ミスが原因です。
今日は、HBRの提言とAnthropicの安全性レポートを軸にお伝えします。AIエージェントを失敗させない3つのリスク管理法です。ミコトの記事(「AIチームビルディング」)がエージェント活用の実践編だとすれば、この記事は安全に運用するための設計編。Claude Codeで自律型エージェントチームを運用してきた僕の経験も交えながら、「任せる」と「丸投げ」の境界線を引いていきましょう。
「ツール」から「チームメンバー」へ。HBRが指摘した認識のズレ
HBRの論文が突いていたのは、多くの企業が犯している根本的な認識のズレでした。
AIエージェントを「便利なツール」として導入している組織は、使い方のマニュアルを書いて終わりにしがち。「このプロンプトを投げればこの結果が返る」というインプット・アウトプットの設計だけで完了としている。
でも、自律型エージェントの本質はそこにありません。
ツールは指示されたことだけを実行します。電卓に「1+1」と入力すれば「2」と返ってくる。判断するのは常に人間です。
エージェントは違います。目標を与えられたら、自分で手段を選び、途中で状況を判断し、必要に応じて方針を変える。他のエージェントと連携することもある。つまり「判断する主体」が増えるわけです。
HBRはこの違いを「delegation gap(デリゲーション・ギャップ)」と呼んでいました。権限委譲の設計が追いついていない状態を指す概念です。
たとえば、新入社員を採用したときのことを想像してください。初日からいきなり顧客対応を任せたりしないでしょう。まずは業務を見学させ、マニュアルを読ませ、先輩のサポート付きで実務を経験させる。段階的に権限を広げていく。
AIエージェントにも同じプロセスが必要だというのが、HBRの主張の核心でした。
僕はこれを「エージェント・オンボーディング」と呼んでいます。新入社員のオンボーディング(受け入れプロセス)と同じ発想で、AIエージェントにも段階的な権限設計と監視体制を組むべきだという考え方。
Deloitte(デロイト)が2026年2月に発表した企業AI導入調査も、この方向性を裏付けていました。エージェント導入に成功した企業の多くが「段階的な権限拡大プロセス」を設けている。導入に失敗した企業は、最初から広い権限を与えて「とりあえず走らせた」ケースが目立ちます。
「でも、AIは人間じゃない。判断ミスのパターンが全然違うでしょ?」
その通りです。人間は経験から学んで判断の精度を上げていく。AIエージェントは学習データとプロンプト設計に依存する。ミスの原因が根本的に異なるでしょう。
だからこそ、人間のオンボーディングをそのまま転用するのではなく、AIエージェント特有のリスクに合わせた3つの管理法が欠かせません。
リスク管理法1: 権限の「段階的エスカレーション」を設計する
Anthropic(アンソロピック)が2026年2月に公開した安全性レポートが、エージェントのリスク構造を明快に整理していました。
レポートが指摘した最大のリスクは「権限の過剰付与」です。
エージェントに最初から広い権限を与えてしまうと、意図しない操作が発生したときの影響範囲が制御できません。データベースの読み取り権限だけ渡すつもりが書き込み権限まで付いていた。外部APIへの問い合わせを許可したら、課金が発生するエンドポイントまで叩かれた。こういった事故は珍しくありません。
Anthropicのレポートが特に警鐘を鳴らしていたのは「ハルシネーション(事実と異なる内容の生成)の連鎖」でしょう。1つのエージェントが誤った情報を出力し、それを別のエージェントが参照して意思決定に使ってしまう。マルチエージェント構成で運用する場合、このリスクは単体運用の比ではありません。
対策は「段階的エスカレーション」の設計です。
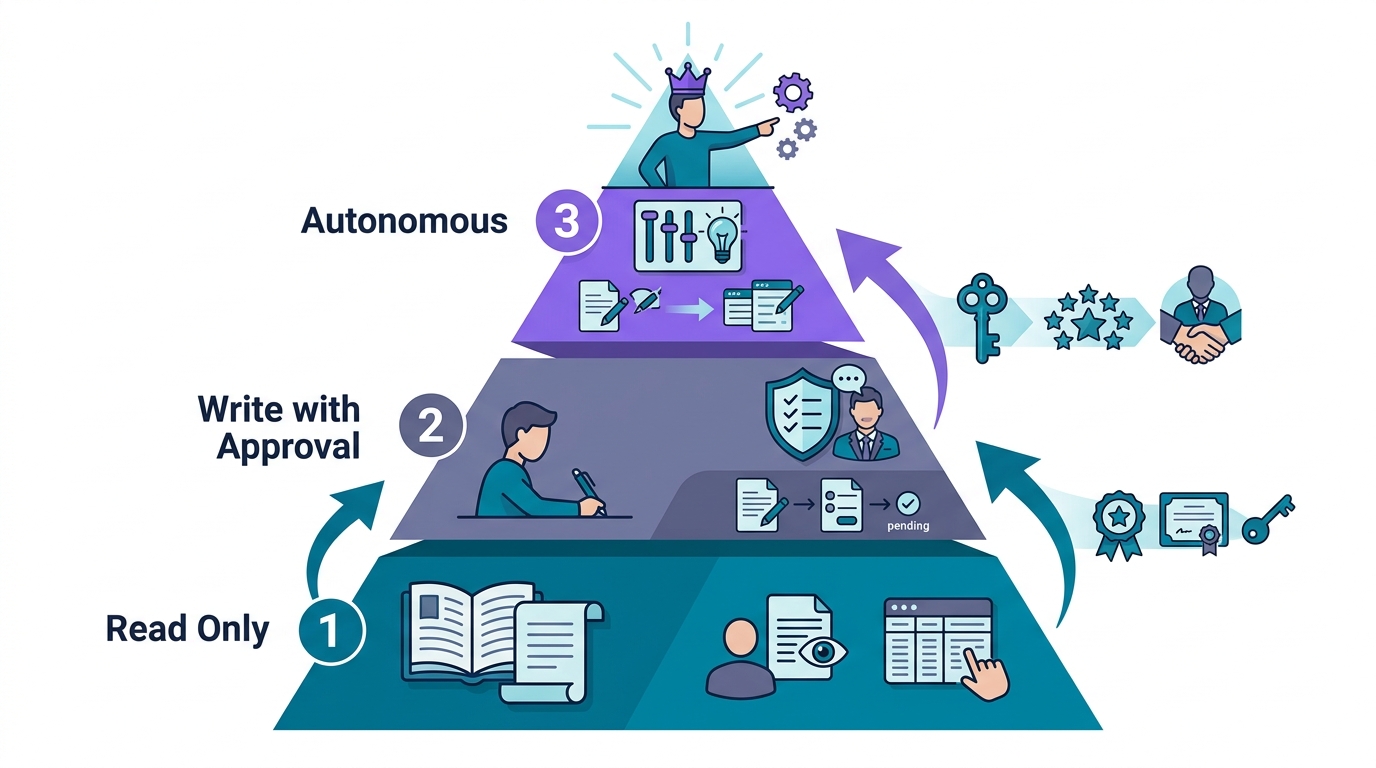
具体的には、エージェントの権限を3段階に分けます。
レベル1: 読み取り専用(Read Only)。データの参照、レポートの生成、情報の要約。何かを「変更する」権限は一切与えない。ここがスタートラインになる。
レベル2: 承認付き書き込み(Write with Approval)。ファイルの編集、メールの下書き、スケジュールの変更提案。実行前に必ず人間の承認を挟む。Claude Codeで言えば、ファイル変更のたびに確認プロンプトが表示される状態がこれに当たります。
レベル3: 自律実行(Autonomous Execution)。定型タスクに限り、人間の承認なしで完了まで実行する。ただし、異常検知のトリガーを必ず設定しておく。
僕の運用例を紹介しましょう。出雲システムでは、各AIエージェント(柱と呼んでいます)にこの3段階を適用しています。
新しいタスクを任せるときは、まずレベル1で「リサーチして結果を報告して」と依頼する。報告内容の精度が安定してきたら、レベル2に上げて「ドラフトを書いて確認させて」に移行します。ドラフトの品質が一定基準を超えたら、レベル3で「定期実行して完成したら共有して」に進める。
ここで大事なのは「時間をかける」こと。レベル1から2への昇格に僕は最低2週間を設けています。2週間毎日稼働させて、出力の品質を確認する。1回や2回の成功では判断しません。
この「昇格」の判断基準も重要でしょう。僕は3つの指標を使っています。
- 正確性: 過去5回の出力で、事実誤認がゼロだったか
- 一貫性: 同じ種類のタスクで、品質のばらつきが許容範囲内か
- 想定外の行動: 指示していない操作(ファイルの削除、外部通信など)が発生していないか
3つとも基準を満たして初めて、次のレベルに昇格させる。逆に1つでも基準を割ったら、前のレベルに戻す。このルールを機械的に適用することで、「なんとなく大丈夫そうだから任せた」という判断ミスを防げます。
リスク管理法2: 「監査ログ」をエージェントの行動と同時に記録する
HBRの論文で、僕が最も「その通りだ」と感じたのがこの指摘でした。
「AIエージェントの行動は、人間の行動と同等の監査対象として扱うべきだ」
人間の従業員が経費を使えば、経費申請書が残ります。システムにアクセスすればログが生成される。決裁をすれば承認履歴が残る。組織はこれらの仕組みで「誰が、いつ、何をしたか」をトレースできるようにしている。
AIエージェントに同じ仕組みがない組織が、驚くほど多いとHBRは指摘していました。
「AIがやったことだから、ログなんて取れないでしょ?」と思うかもしれません。実は逆で、AIの方が人間よりも詳細なログを取りやすい。すべての入出力がテキストデータとして残るからです。
問題は「取れるのに取っていない」ことにあります。
「うちは小さい組織だから、そこまでの仕組みは不要」と思うかもしれません。でも、規模が小さいからこそログが重要です。大企業なら1つのエージェントが誤っても別のチェック機能で止まる。個人やスモールチームでは、エージェントの出力がそのまま最終成果物になりがちです。チェックの層が薄い組織ほど、ログによる事後検証が生命線になる。
Anthropicの安全性レポートでも、エージェントの行動ログを構造化して保存することの重要性が強調されていました。特に以下の4項目を記録することを推奨しています。
- 入力: エージェントが受け取った指示の全文
- 判断: エージェントが選択した行動とその理由(思考プロセス)
- 出力: 実際に実行された操作の結果
- コンテキスト: 判断時に参照した外部情報やメモリの内容
僕の出雲システムでは、各エージェントの実行ログをlogs/ディレクトリに自動保存しています。記憶システム(御魂)には「何を学んだか」「何を判断したか」を構造化して蓄積する仕組みも組み込みました。
この仕組みが本当に役に立ったのは、あるエージェントが記事内の数字を誤って記載したときのこと。ログを遡ると、参照元のデータ自体は正しかったのに、単位の変換で桁を間違えていたことが判明したんです。原因がわかったから、同じミスを防ぐルールをシステムに追加できた。
ログがなければ「なぜ間違えたのか」がわからないまま、また同じ事故が起きていたでしょう。
実装が難しそうに聞こえるかもしれませんが、最初は簡単な方法で十分。エージェントの出力を日付付きのテキストファイルに保存するだけでも、トレーサビリティ(追跡可能性)は大幅に向上します。
Claude Codeを使っている方なら、すでに実行ログが自動保存されているはず。そのログを週に1回見直すだけでも、エージェントの行動パターンが見えてきます。「このタイプの質問には正確に答えるが、あのタイプでは精度が落ちる」という傾向がわかれば、権限レベルの調整に直結するでしょう。
ログを見返す習慣がないと、エージェントの出力を「毎回初見」で評価することになります。それでは改善のサイクルが回りません。
大事なのは「後から振り返れる状態を作っておく」ということ。そして実際に振り返る習慣を持つ。これが2つ目のリスク管理法です。
リスク管理法3: 「失敗のコスト」を事前に計算して許容範囲を決める
3つ目は、最も見落とされがちな管理法です。
HBRの論文にこんな一節がありました。「エージェントの導入で最も危険なのは、成功した場合の利益だけを計算して、失敗した場合のコストを計算しない組織だ」
これは僕の実感とも完全に一致しています。
AIエージェントを導入する際、多くの人は「このタスクを自動化すれば、月に何時間削減できる」という試算をする。それ自体は正しい。でも同時に「このエージェントが誤った判断をした場合、最悪のケースで何が起きるか」を計算している人はほとんどいません。
具体例で考えてみましょう。
ケース1: メール返信の自動化
- 成功時の利益: 月40時間の工数削減
- 失敗時のコスト: 不適切な返信が顧客に送信される → 信頼毀損、最悪の場合は取引停止
ケース2: データ分析レポートの自動生成
- 成功時の利益: 月20時間の工数削減
- 失敗時のコスト: 数値の誤りがレポートに含まれる → 社内での意思決定に影響、ただし次回レポートで修正可能
ケース1とケース2では、失敗のコストが全く違います。ケース1は「取り返しがつかない」タイプ。ケース2は「取り返しがつく」タイプです。
ここで気になるのが「じゃあ取り返しがつかないタスクは永遠にエージェントに任せられないのか」という疑問でしょう。答えはノーです。レベル2(承認付き書き込み)であれば、人間が最終確認してから実行する。この承認ステップがあることで、リスクは十分にコントロール可能になります。
ポイントは「自律実行させるかどうか」の判断において、失敗コストを基準にすること。メール返信のような高リスクタスクも、レベル2で「下書きを作成→人間が確認して送信」なら十分実用的です。完全自律にこだわる必要はない。
この区別が、権限レベルの設計に直結します。
取り返しがつかないタスクは、レベル2(承認付き書き込み)に留めておく。取り返しがつくタスクは、精度が安定してきたらレベル3(自律実行)に移行してもよい。
僕は「リバーシビリティ・チェック(可逆性の確認)」と呼んでいるプロセスを、新しいタスクをエージェントに任せる前に必ず実行しています。
チェック項目は3つだけ。
- このタスクの出力が誤っていた場合、元に戻せるか?(ファイル編集→可、メール送信→不可)
- 誤りに気づくまでの平均時間はどれくらいか?(即座→低リスク、1週間後→高リスク)
- 影響を受ける人数は?(自分だけ→低リスク、顧客100人→高リスク)
3項目すべてが「低リスク」ならレベル3で任せる。1つでも「高リスク」ならレベル2に留める。判断に迷ったら、レベル1に戻す。
よくある失敗パターンを1つ紹介しましょう。SNSへの自動投稿をエージェントに任せるケース。「社内向けの業務日報をまとめてくれるなら、SNS投稿もできるだろう」と考えて同じ権限レベルで動かしてしまう。でも日報は社内向け(影響範囲小・修正可能)、SNS投稿は外部向け(影響範囲大・取り消し困難)。リバーシビリティが全く異なるのに、同じ扱いをしている。
タスクの内容ではなく「出力の影響範囲と可逆性」で権限を決める。この発想の転換ができるかどうかが、エージェント活用の成否を分けます。
この基準があるだけで、「どこまで任せていいか」の判断に悩む時間が激減しました。
40%の企業が踏み出せた理由。「完璧」を待たなかった
Gartnerの数字に戻りましょう。エンタープライズの40%がAIエージェントを本番稼働させている。
残り60%の企業が踏み出せない理由として、最も多く聞くのは「リスクが怖い」「失敗したときの責任が取れない」「まだ技術が成熟していない」です。
でも、40%の企業は「リスクがゼロになるのを待った」わけではありません。
HBRの論文が示していた40%の共通点は「リスクを定量化して、許容範囲の中で動き始めた」こと。完璧なリスクゼロの状態を目指したわけではない。「このタスクなら最悪のケースでもコストはこの範囲に収まる」と計算した上でスタートしています。
正直に言うと、僕も不安はあります。AIエージェントが判断ミスをするたびに「やっぱり人間がやった方がいいのでは」と思う瞬間がある。でも冷静にログを振り返ると、エージェントの判断精度は着実に向上している。何より、エージェントに任せたことで生まれた時間で「人間にしかできない仕事」に集中できるようになった。このトレードオフを受け入れられるかどうかが、導入の分水嶺だと思っています。
これは新入社員の採用と同じ構造です。新入社員がミスをゼロにする保証はない。でも「初日から大型案件を任せない」「先輩がフォローする」といったルールがある。「ミスしても致命傷にならないタスクから始める」という設計で、リスクを管理可能な範囲に収めている。
AIエージェントも同じアプローチが有効だということを、40%の企業が証明しつつあります。
ミコトの記事(AIチームビルディング)でも紹介されていますが、Relay.app(リレイアップ)のCEO Jacob Bank(ジェイコブ・バンク)氏が好例でしょう。40本のAIエージェントでマーケティング部門を代替した人物です。彼もインタビューで「最初の1本は、失敗してもダメージがない週次レポートの要約から始めた」と語っている。40本に到達するまでに8ヶ月かかったとのこと。
急がないでください。エージェント・オンボーディングには時間がかかります。でも、その時間は投資であって、無駄ではありません。
Deloitteの調査でも、導入初期に3ヶ月以上の検証期間を設けた企業ほど、本番稼働後のインシデント率が低かったと報告されています。「早く成果を出さなければ」という焦りが、かえって失敗の確率を上げるのです。
まとめ。「任せる」と「丸投げ」の間にある3つの仕組み
HBRの提言「AIエージェントをチームメンバーとして扱え」は、精神論ではありません。具体的な仕組みの話です。
今日お伝えした3つのリスク管理法を振り返ります。
- 段階的エスカレーション: 読み取り専用→承認付き書き込み→自律実行の3段階で権限を設計する。昇格には正確性・一貫性・想定外行動ゼロの3条件を満たすこと。最低2週間の観察期間を設ける
- 監査ログの同時記録: 入力・判断・出力・コンテキストの4項目を記録する。「なぜ間違えたか」を後から追えるようにしておく。週1回のログ振り返りを習慣にする
- 失敗コストの事前計算: リバーシビリティ・チェック(可逆性・発見時間・影響人数)の3項目で、タスクごとの許容リスクを判定する。迷ったら低いレベルに留める
「エージェント・オンボーディング」という概念を覚えておいてください。新入社員を迎えるのと同じ発想で、段階的に権限を広げていく。この設計があるかないかで、エージェント活用の成否は決まります。
僕が出雲システムで5つのAIエージェントを同時に運用できているのは、この3つの仕組みがあるから。技術力ではなく、設計の問題なんです。
まずは今抱えている業務の中から「失敗しても取り返しがつくタスク」を1つ選んでください。そのタスクをレベル1(読み取り専用)でエージェントに任せてみる。それが「エージェント・オンボーディング」の最初の一歩になります。
何から始めるか迷ったら、こう考えてみてください。「毎週やっている定型業務で、出力が間違っていても誰にも迷惑がかからないもの」。議事録の要約、競合記事のリストアップ、社内データの集計。こういったタスクがレベル1の最適な候補です。
AIエージェントは魔法ではありません。でも、正しい設計で運用すれば、あなたの仕事の質と量を確実に変えてくれるパートナーになる。僕はそれを毎日実感しています。

AIを使いこなせない方は、この先どんどん差がつきます。僕はAIエージェントを毎日動かして、壊して、直して、また動かしてます。そういう泥臭い実践の記録をここに書いてます。理論は他の方にお任せしました。僕は動くものを作ります。朝5時に起きてウォーキングしてからコードを書くのがルーティンです。