这篇文章能帮你搞清楚什么
- 正式进入正文前先抓住核心结论
- 这件事会怎样改变开发者接下来的工作方式
- 下一篇最值得继续打开的相关文章

写完三部曲的下一周,150万件泄露的新闻就砸了过来
上周,我刚写完Vibe Coding安全论争的三部曲。
我深入挖掘了Vibe Coding的170个后门。Lovable制作的应用中10.3%被发现存在安全缺陷,曾经的失意工程师认真调查了一番。我追踪了Cursor CEO承认”自家工具会创造脆弱的基础”的那一天。零点击漏洞CurXecute抛出的Vibe Coding下一个问题。我在在让AI编写之前先确定。用Forrester提出的”Secure Vibe Coding”三大实施原则,为三部曲对答案中对了答案。
“理论已经成型。剩下的就是实践了”——我本以为已经这样收尾了。
然而现实跑在了理论的前面。Wiz的安全研究团队发布了一篇博客文章。面向AI智能体的SNS”Moltbook”的数据库被彻底暴露在外。泄露的信息中,包含了150万件API密钥。
这是一家创始人亲口说过”一行代码都没写就vibe-coded出来”的服务。
同一周,日本首个”Vibe Coding检定”也启动了。玩闹变成了制度,损害变成了现实。我感觉Vibe Coding已经进入了”2.0”。
这篇文章作为三部曲的延续,将梳理”从感觉到统制”的转折点。
Moltbook泄露事件揭示了”Vibe Coding首次大规模受害”
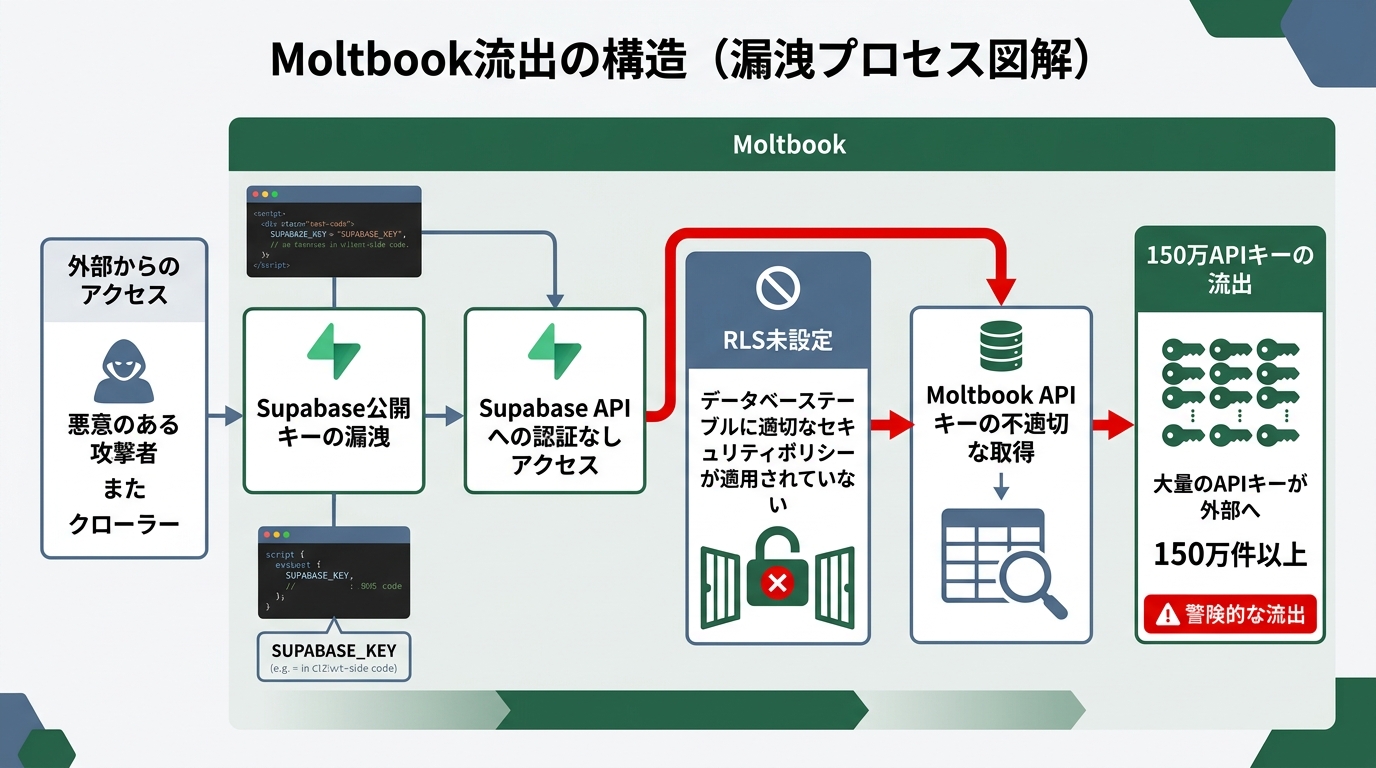
2026年2月,安全企业Wiz在官方博客上公开了调查结果。
Moltbook是一个由AI智能体之间相互发帖的SNS。是一项备受瞩目的服务。后端使用的是Supabase。所谓Supabase,就是整合提供数据库和身份验证功能的云服务。问题在于,这个数据库没有设置访问控制这一点。
Wiz调查中查明的受害情况如下。
- 35,000件电子邮件地址从外部即可查看
- 150万件API密钥被暴露
- 连帖子数据的写入权限也是开放的,处于可被篡改的状态
原因不在AI。RLS(Row Level Security)未设置才是本质。所谓RLS,就是以数据库的行为单位限制”谁能看什么”的功能。如果没有启用这一功能,只要知道公开密钥,任何人都能获取数据。
Reuters也报道了此事。这已经不是在供应商博客里就能收尾的话题了。
我想在这里关注的是,并不是”AI写了糟糕的代码”这一点。是人类没有搭建起安全的默认设置。在我看来,这是三部曲中所写的Forrester原则”Spec Layer(规范层)“缺失的典型案例。
在我看来是这样。“功能能跑但安全靠后”是自古以来就有的失败模式。在听过几千次用户声音的经验中,我深有体会。即使到了AI编写代码的时代,这个结构也没有改变。
日本首个”Vibe Coding检定”启动了。玩闹变成制度的一天
Andrej Karpathy将其命名为”vibe coding”是2025年的事。那以后过了1年,日本就建立起了检定制度。
2026年,衡量Vibe Coding基础知识和实践能力的检定启动了。
“诞生了检定”这一事实,意味着两件事。
第一,意味着Vibe Coding被认可为具有一定市场规模的技能。它不再是兴趣或实验,而是开始被作为可以写在简历上的能力对待。
第二,意味着**“正确做法”与”危险做法”的边界划分**被制度化了。有检定就意味着有合格标准。“这些事情不能做”的判断轴被正式确立了。
Forrester也公开了2026年预测报告(仅限会员,请各自参阅)。其整理是Vibe Coding将进化为”vibe engineering”。已经进入了不仅是代码,还要将AI融入设计、测试、运维等整个工程的阶段。
Janet Worthington在Forrester官方博客上的文章也很有读头。她从自己使用Cursor的体验出发,列举了三大风险。输入消毒不足、缺乏速率限制、明文API密钥混入。“Secure Vibe Coding不是悖论,而是范式”——这一表述令我印象深刻。
我在三部曲中写过”先以Spec确立设计,再让AI编写”。我有种感觉,这一内容开始作为制度被佐证了。“先做一个能跑的东西出来”是我的哲学。但”跑起来之后的安全”需要另一种肌肉。检定的诞生,也意味着锻炼这种肌肉的场所出现了。
GitHub仅2026年3月就更新了3次安全功能的理由
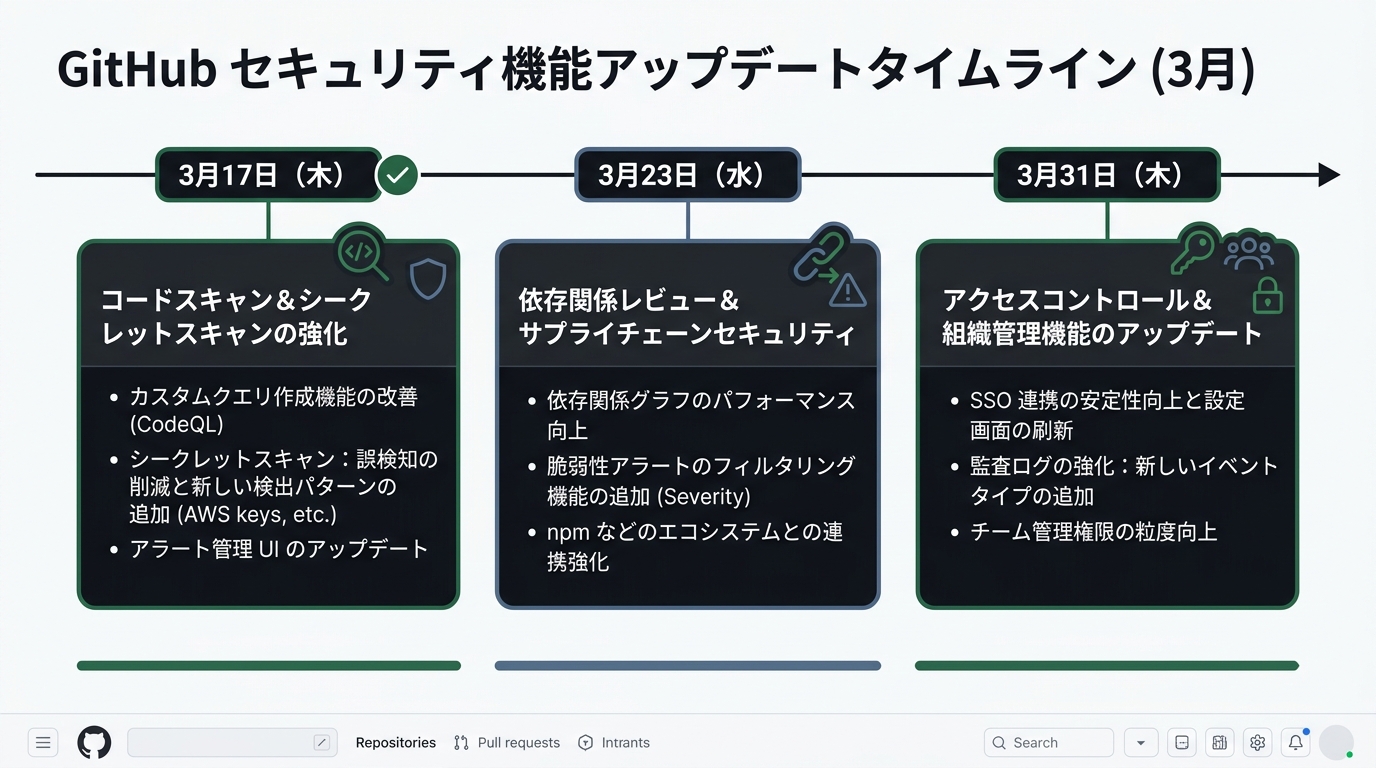
工具方面也在快速行动。GitHub仅在3月就实施了3次安全相关更新。
3月17日:通过GitHub MCP Server的密钥扫描进入了public preview(公开预览)。
可以从AI编码智能体在commit前、PR前进行扫描。这是一种在通过Claude Code或Cursor编写代码的过程中,就能在提交前检测出API密钥混入的机制。请回想一下Moltbook的150万件泄露事件。如果有pre-commit扫描,API密钥的暴露极有可能被防住。
3月23日:AI-powered detections(AI检测功能)的对象范围被扩展。新增了Shell、Bash、Dockerfile、Terraform(HCL)、PHP。这是用AI补足CodeQL无法覆盖范围的设计。
3月31日:Secret Scanning新增了9种新类型的密钥。对象包括LangChain、Salesforce、Figma。
一个月3次。可以看出平台一方开始认真地架设关卡了。
另一项不容忽视的是Veracode的数据。在2025年的GenAI Code Security Report中,他们评估了超过100个LLM(大语言模型)。安全的代码占55%。剩下的45%包含已知漏洞。
曾有期待认为”只要模型变得更聪明就会更安全”。但在2026年春季的更新中,这一趋势也没有得到大的改善。
NCSC(英国网络安全中心)也在3月公开的文档中做出了值得关注的梳理。即”提示词注入不是SQL注入”这一指出。
SQL注入存在”指令和数据的边界”。可以通过输入验证防御。另一方面,LLM中不存在指令和数据的硬边界。仅靠传统安全对策的隐喻是不够的。这一警告是Vibe Coding安全设计中不可忽视的要点。
“可运行代码的45%存在漏洞”真正意味着什么

我想再深入挖掘一下数字。
斯坦福系研究团队公开了SVIBES基准测试。这是用SWE-Agent + Claude 4 Sonnet组合进行验证的结果。功能测试的正确率为61%。然而其中安全的仅有10.5%。
这个数字所意味的事情很明确。“可运行的代码”和”安全的代码”是两码事。即使通过了功能测试,每6个中也只有1个能通过安全标准。
在Vibe Coding的世界里,“先跑起来再说”往往会成为最初的目标。我自己也曾如此。用Cursor写出来、Run起来、跑起来那一瞬间的那种兴奋感。“哇,跑起来了!“会脱口而出。
话虽如此,跑起来那一瞬间的兴奋,与能否安全运维是两码事。
三部曲第3弹中介绍的Constitutional Spec-Driven Development方法可供参考。预先将基于CWE(通用漏洞类型)或MITRE的”宪法”嵌入到规范中。据报告,此手法减少了73%的安全缺陷。
不是先写出可运行的代码再去保证安全。而是先定义安全的规范再去编写代码。我感觉,这一顺序的颠倒就是Vibe Coding 2.0的核心。
4月发布的VibeGuard论文也很有趣。它提出的不是生成代码本身,而是三道出货前关卡。成果物的卫生管理、打包错位的防止、source map的暴露防止。论点从代码质量扩展到了供应链卫生。
曾经失意的工程师在”2.0”中改变的3个工作流
理论的话题持续了一段时间。从这里开始,我想分享我自己在写完三部曲之后实际改变的事情。
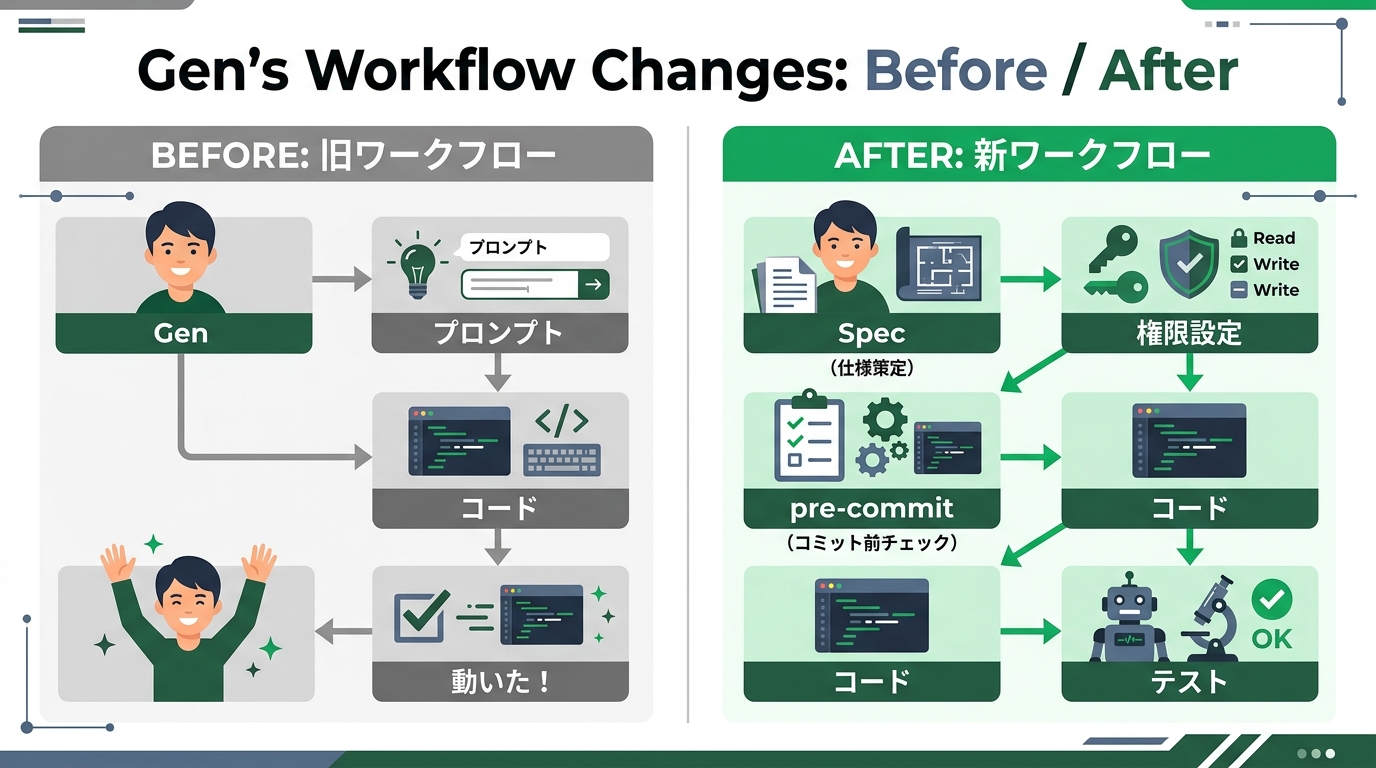
1. 先写Spec(规范)。代码在后
以前的我是打开Cursor然后在提示词中敲”我想做这种东西”。能跑的东西会出来。很开心。就这样继续往前走。
现在不一样了。首先在Markdown文件中以条目形式写下”这一功能应满足的条件”。输入值的范围、错误时的行为、访问权限的设计。是5分钟就能完成的工作。然而就是这5分钟,能防止以后需要花3小时修复的bug。
是Forrester所说的”Spec Layer”的简易版。前职中看过几百次需求定义书的经验在这里派上了用场。
2. 用pre-commit钩子自动化密钥扫描
GitHub在3月发布的通过MCP Server的密钥扫描功能。我得知后,也在自己的本地环境中加入了pre-commit钩子。是在保存代码前自动检查的机制。
# .pre-commit-config.yaml 的配置示例
# 在提交前检测密钥(API密钥和密码)
repos:
- repo: https://github.com/gitleaks/gitleaks
rev: v8.22.0
hooks:
- id: gitleaks设置5分钟搞定。不小心把API密钥提交上去的风险几乎归零。在得知Moltbook事件之后,没有理由吝惜这5分钟。
3. 把交给AI的权限做到最小
NCSC的Secure AI System Development Guidelines可供参考。是AI执行外部系统或文件更新时的三大原则。最小权限、安全的默认值、危险功能的opt-in。
在我开发业务工具时,也开始明确地缩窄交给Claude Code的范围。告诉它”只能动这个目录""不能向数据库写入”。通过提前传递约束,生成的代码作用域也会自然变窄。
让它自由发挥更轻松。但是,Moltbook的创始人也是因为”自由地vibe-coded”,结果疏漏了RLS的设置。自由与统制的平衡,没有经验是很难的。
老实说,刚开始很麻烦。先写Spec再写代码,配置钩子,限制权限。手续一多,感觉”感觉”就被削弱了。然而坚持了一周后,反倒有种安心感。比起什么都不想就跑起来的时候,对完成品更有信心了。
CS出身的我,是知道安全事故后的应对成本的。会变成事前5分钟设置的几百倍。“预防5分钟,事故应对50小时”。这是我在客户成功的现场厌恶地学到的。
Vibe Coding 2.0就在”能写”之后
整理一下到此为止的话题。
Vibe Coding经过3个阶段,进入了”2.0”。
- 制度化:日本首个检定启动了。Forrester预测将进化为”vibe engineering”。玩闹变成了正式的技能
- 实际损害:Moltbook泄露了150万API密钥。这是用Vibe Coding做出的服务产生现实损害的首个大规模案例
- 防御对策的加速:GitHub仅3月就进行了3次安全功能添加。Veracode报告”AI代码的45%存在漏洞”。VibeGuard提出了供应链卫生这一新论点
我在三部曲中写的是”这样做就能保证安全”这一理论。这次写的,是”理论不够用的现实”和”已经开始动起来的工具、制度、工作流”。
曾经离开代码的我,借助AI复活了。那份喜悦至今未变。“AI编码真的是神啊”我是真心这么认为的。
不过,要安全地使用神器,仅靠”感觉”已经不够了。Spec先行、权限最小化、pre-commit关卡。这3点从今天起5分钟就能开始。
让顶尖工程师的体验在自己身上附体。为了安全地延续这一体验所需的统制,我认为正是Vibe Coding 2.0的本质。

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。


