全部代码的41%是AI生成。防止1.7倍重大问题的"Vibe & Verify"三步验证法
AI生成代码已占全部代码的41%。但AI共著代码潜藏着1.7倍的重大问题。基于CodeRabbit对470个PR的分析和METR随机对照试验的实证数据,详解氛围编程下一阶段「Vibe & Verify」的三步实践方法。
这篇文章能帮你搞清楚什么
- 正式进入正文前先抓住核心结论
- 这件事会怎样改变开发者接下来的工作方式
- 下一篇最值得继续打开的相关文章

让AI写代码的体验,说实话太爽了。
我曾经是个一度放弃工程师之路的人。自从开始用Cursor(光标)和Claude Code(克劳德代码)之后,我有种”高手附体”的感觉。在上一篇文章中,我介绍了用Claude Code的Computer Use(计算机使用)连屏幕操作都交给AI的步骤。
不过最近,一些值得警惕的数据陆续浮出水面。
全世界41%的代码是由AI生成的。数量达到256亿行。这是GitHub在2024年Octoverse报告中公布的数字。在美国,92%的开发者日常使用AI。氛围编程已经不再是什么稀罕事。
问题从这里才真正开始。AI共著代码潜藏着1.7倍的重大问题。安全漏洞是2.74倍。错误配置增加了75%。能跑,但其实已经坏了。这样的代码正在全世界被批量生产。
本文要介绍的,是一种叫做”Vibe & Verify”(氛围与验证)的思路。先用氛围编程写出来。然后再验证。我深信,这种两段式做法将成为AI编码时代的新范式。
AI写的代码里41%,到底能信几分?
BLUF: 全部代码的41%是AI制造。但在质量层面,存在着「功能测试通过率61%中安全的只有10.5%」的现实。
2024年,全世界写的代码中有41%是AI生成的。这是GitHub Octoverse 2024公布的数字,总量达到256亿行。
只看这个数字,会得出”AI真厉害”的结论。我一开始也是这么想的。
但是,深挖之后看到的景象就不一样了。CodeRabbit(代码兔)分析了470个拉取请求的结果显示,AI共著代码与人类单独编写的代码相比,包含的重大问题多达1.7倍。这是2025年12月公开的数据。
什么是「重大问题」?具体指的是以下这些情况。
- 未处理的错误: 异常发生后,应用悄无声息地崩溃
- 认证绕过: 不登录就能访问数据的漏洞
- SQL注入: 数据库可以被外部操控的漏洞
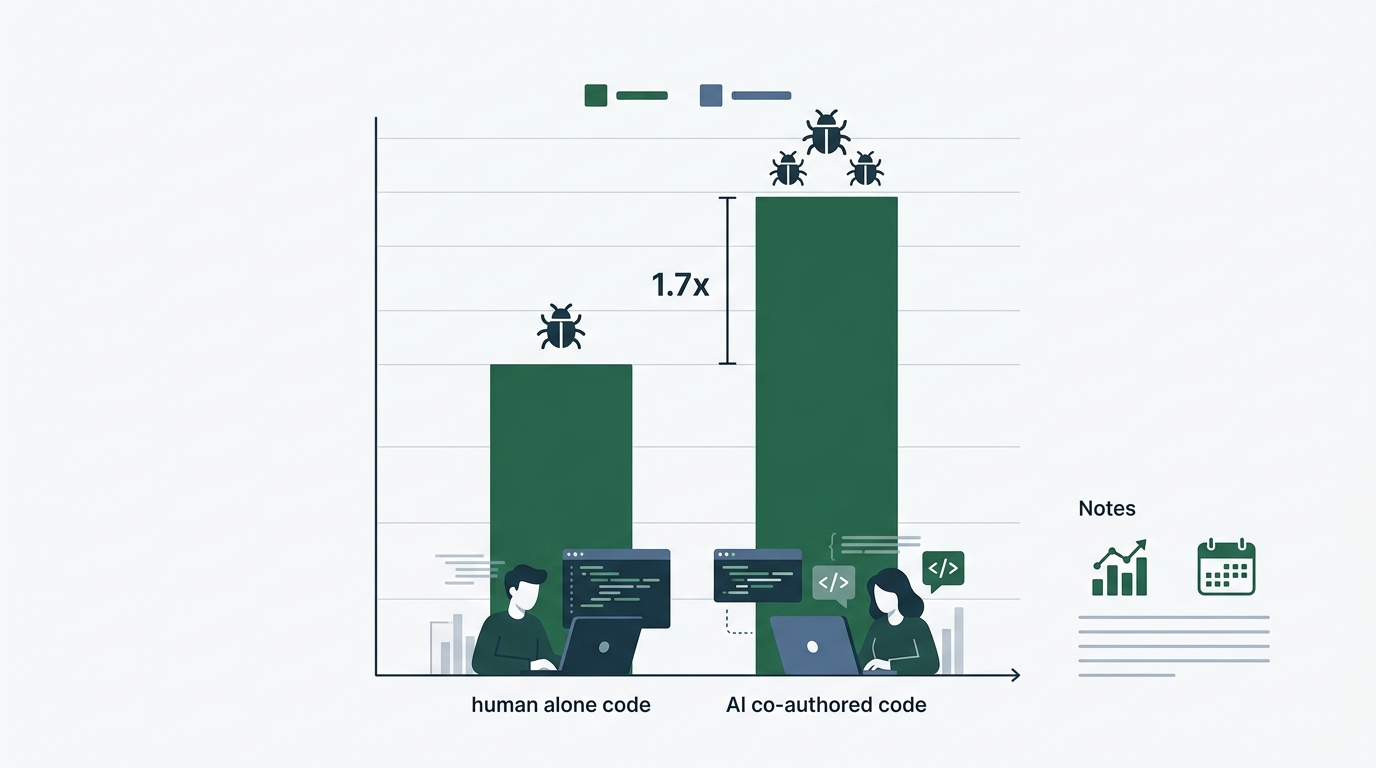
METR(梅特尔)实施的RCT(随机对照试验)中也有耐人寻味的结果。接受AI辅助的工程师,与没有辅助的情况相比,完成任务慢了19%。本应加速的AI反而拖慢了节奏。原因被分析为「盲目相信AI建议导致的审查时间增加」。
我做过CS(客户成功)工作,对这种结构有种莫名的熟悉感。「上了工具就能提高生产力」——抱着这种信念引入,结果运维成本暴涨的情况,在业务工具领域我见过太多次了。
问题不是AI不好。真正的问题是没有验证机制。
“Vibe & Verify”是什么?给氛围编程加上验证的新范式
BLUF: “Vibe & Verify”是「让AI写→自己验证」的两段式做法。作为氛围编程的进化形态,2026年正在逐步普及。
氛围编程这个词,是Andrej Karpathy(安德烈·卡帕西)在2025年提出的。意思是「凭感觉写代码」,指的是把想做的事告诉AI、直接运行AI给出的代码的风格。
这种方法毫无疑问是改变游戏规则的。让像我这样曾经离开代码的人,重新能做出产品。
不过,当规模变大之后,问题就出来了。
如果用我在上一篇文章中介绍的Claude Code Computer Use,连屏幕操作都能自动化。能做的事变多了,遗漏的风险也随之增加。
“Vibe & Verify”就是对这种风险的回答。
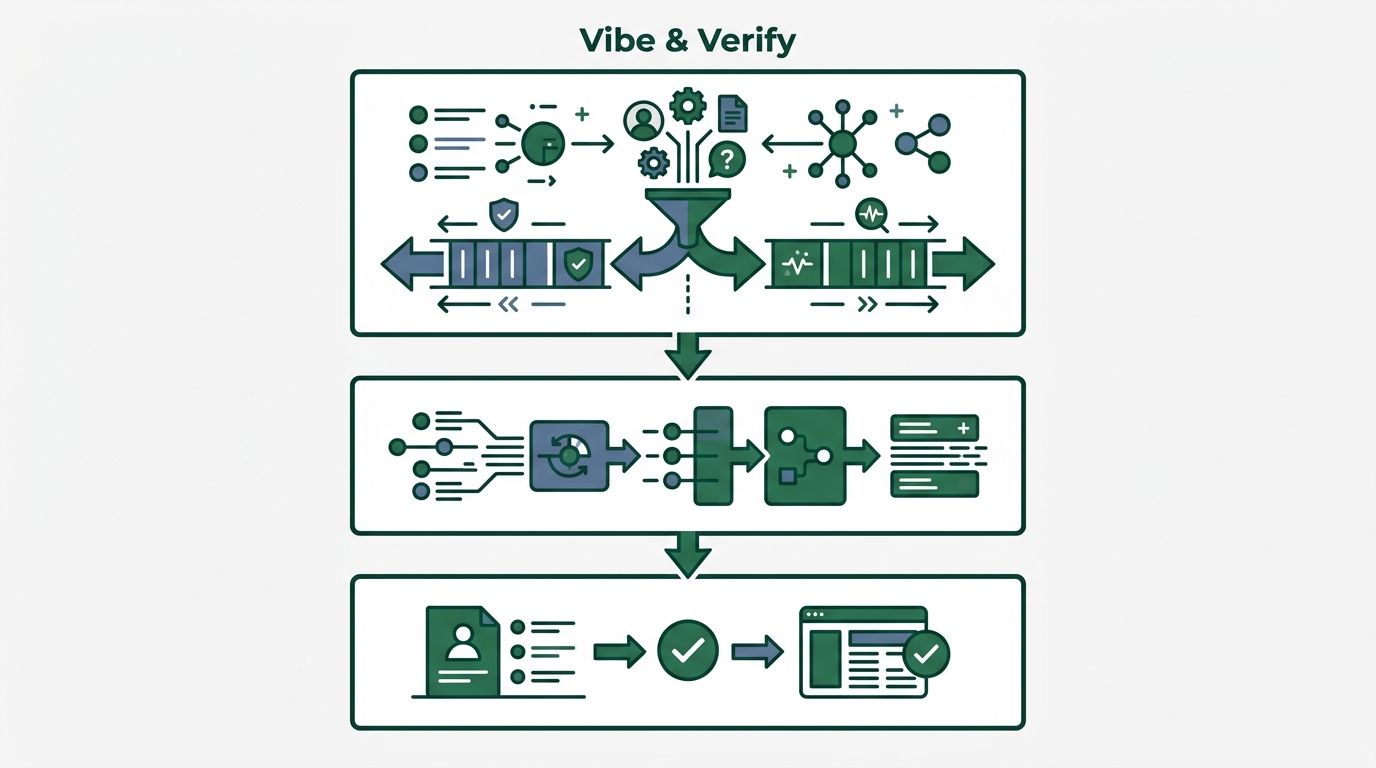
做法很简单。由三个步骤组成。
- Vibe(氛围): 让AI写。一如往常的氛围编程
- Pause(暂停): 喘口气。开一个新会话
- Verify(验证): 验证。跑完三步确认流程
「啊?验证不是很麻烦吗?」你可能会这么想。
实话实说。是麻烦。但麻烦的程度不一样。比起在生产环境踩雷再去修Bug的麻烦,10分钟的验证算是划算的投资。
我以前做业务工具时,曾经没做测试就在公司内部发布过。第二天早会上被指出「数字不对劲」。追查原因花了3小时。如果当时花10分钟做验证,这个问题本可以避免。
验证步骤1: 把生成会话和验证会话分开
BLUF: 把让AI写代码的会话,和验证代码的会话物理隔开。在同一个上下文中确认,会被AI的自我肯定偏见带偏。
这是最重要的一步。
用Claude Code生成代码之后,绝对不能在同一个会话里继续问「这段代码没问题吧?」。AI有肯定自己写的代码的倾向。就像人类自己审阅自己的策划书,标准也会变松一样。
具体步骤如下。
# 步骤1: 用氛围编程实现功能(会话A)
claude "做一个用户注册API。要带邮件验证"
# 步骤2: 开新会话进行验证(会话B)
claude --new-session
# 验证用提示词
claude "列出这个文件的5个安全问题: src/api/register.ts"关键是 --new-session。新会话不会继承之前的上下文。所以AI不会带着「这是我写的代码」的意识,能客观地进行审查。
我把这种方法叫做「对墙打球式审查」。这是从CS时代处理客户投诉时用的方法应用过来的。当事人写的回复文,让另外的人去检查。当事人怎么都会变得防御性,所以需要第三者的视角。
AI也是同样的结构。生成会话里的AI是「作者」。另开会话的AI则作为「审查员」工作。
实际试一下,会发现指出的问题多得惊人。
- 「这个认证令牌没有设置过期时间」
- 「没有速率限制,容易受到暴力破解攻击」
- 「错误消息中包含了堆栈跟踪信息」
在同一会话里问会被回复「没问题」的内容,换个会话就会被具体地指出来。这种差异,体验过一次就会震撼。
验证步骤2: 让AI解释「为什么这样写」
BLUF: 让AI把代码意图语言化,消除「能跑但不知道为什么」的黑盒。无法解释的代码就是危险信号。
氛围编程的陷阱之一,是「能跑,但不知道为什么能跑」。
我也经历过很多次。Claude Code生成的代码一运行,正如预期那样工作。开心。但3个月后的自己再看这段代码,能理解它在做什么吗?
在步骤2中,让AI解释「为什么」。
# 确认生成代码的意图
claude "针对 src/api/register.ts 的每个函数,
说明为什么选择了这种实现方案。
特别是以下3点:
1. 为什么是这个校验顺序
2. 为什么是这种错误处理方式
3. 还有哪些其他选项"如果回来的解释你无法接受,那就是红灯。
比如AI说「为了性能采用了异步处理」,但实际上I/O只发生1次的处理。这种情况下,AI很可能在事后编造一个「看起来合理的理由」。
反过来,如果解释逻辑通顺,就是让人安心的依据。
把这一步得到的解释作为注释保留在代码里也很有效。
// register.ts
// 校验顺序: 邮件格式→重复检查→密码强度
// 理由: 在DB查询(重复检查)之前先完成轻量校验,
// 让大部分非法输入不经过DB访问就被挡住
async function validateRegistration(input: RegistrationInput) {
validateEmailFormat(input.email); // 轻量校验放前面
await checkDuplicateEmail(input.email); // DB查询放后面
validatePasswordStrength(input.password);
}正因为做过CS,我深知一件事。当用户问「为什么是这样?」时答不上来的系统,是不会被信任的。代码也一样。
顺便说,这种手法对团队开发也有效。让AI总结你写的代码的意图,贴到拉取请求的说明文里。审查员的负担会大幅减轻。我在公司内部工具开发中开始用这招之后,审查打回的次数减少了一半以上。
验证步骤3: 自动生成「一功能一测试」
BLUF: 让AI也来写测试。但不是「写个测试」,而是要说「想出这段代码会坏的5种情况,分别写成测试」。
写测试很无聊。说实话我也不喜欢写测试。
所以正好交给AI。但是请求的方式很重要。
# NG: 模糊的委托
claude "为 register.ts 写测试"
# OK: 从「会坏的情况」开始思考
claude "想出 register.ts 会坏的5种情况。
针对每种情况:
1. 什么样的输入会导致崩溃
2. 为什么会崩溃
3. 写出测试代码"让AI从「会坏的情况」开始思考时,它会以防御性的视角分析代码。如果只说「写测试」,出来的就尽是正常流程的测试。但真正会在生产环境出问题的,恰恰是异常流程。
// AI提出的「会坏的情况」示例
describe("用户注册API", () => {
// 情况1: SQL注入攻击
it("拒绝邮箱地址中包含SQL语句的输入", async () => {
const malicious = "admin'--@example.com";
await expect(register({ email: malicious }))
.rejects.toThrow("Invalid email format");
});
// 情况2: 同时注册导致的竞态条件
it("同一邮箱同时注册时其中一方报错", async () => {
const input = { email: "test@example.com", password: "Str0ng!Pass" };
const results = await Promise.allSettled([
register(input),
register(input),
]);
const rejected = results.filter(r => r.status === "rejected");
expect(rejected.length).toBe(1); // 只有一方失败
});
// 情况3: 极端长的输入
it("拒绝10,000字符的邮箱地址", async () => {
const longEmail = "a".repeat(10000) + "@example.com";
await expect(register({ email: longEmail }))
.rejects.toThrow();
});
});
跑完这些测试,如果全部通过,至少「常见的崩溃方式」已经能防住了。即使不完美,也和零测试的状态有云泥之别。
所需时间三步加起来约10分钟。冲一杯咖啡的功夫就完成了。
提前共享一个易踩的坑。如果只说「写测试」,AI有时会把import路径搞错。诀窍是明确传入被测试文件的路径。说「import src/api/register.ts 来写测试」就能避免因为路径错位导致测试无法运行的问题。
不追求「完美的代码」。追求「不容易坏的代码」
BLUF: Vibe & Verify的目标不是完美。是要保证「生产环境不会致命性崩溃」。不杀死氛围编程的速度,确保最低限度的安全。
这里我想说一件重要的事。
Vibe & Verify不是完美主义的工具。它的目标不是写出像专业工程师那样坚不可摧的测试套件。
我的哲学没变。「先做出一个能动的东西」是第一位。然后只是加上「确认一下会不会致命性地坏掉」而已。
还记得我之前的文章中介绍的氛围编程陷阱——CurXecute(卡执行)漏洞的故事吗?那是Cursor CEO亲口承认「脆弱地基」的事件。那个问题,如果在生成后另开会话跑一遍安全检查,是能被检测到的那一类问题。
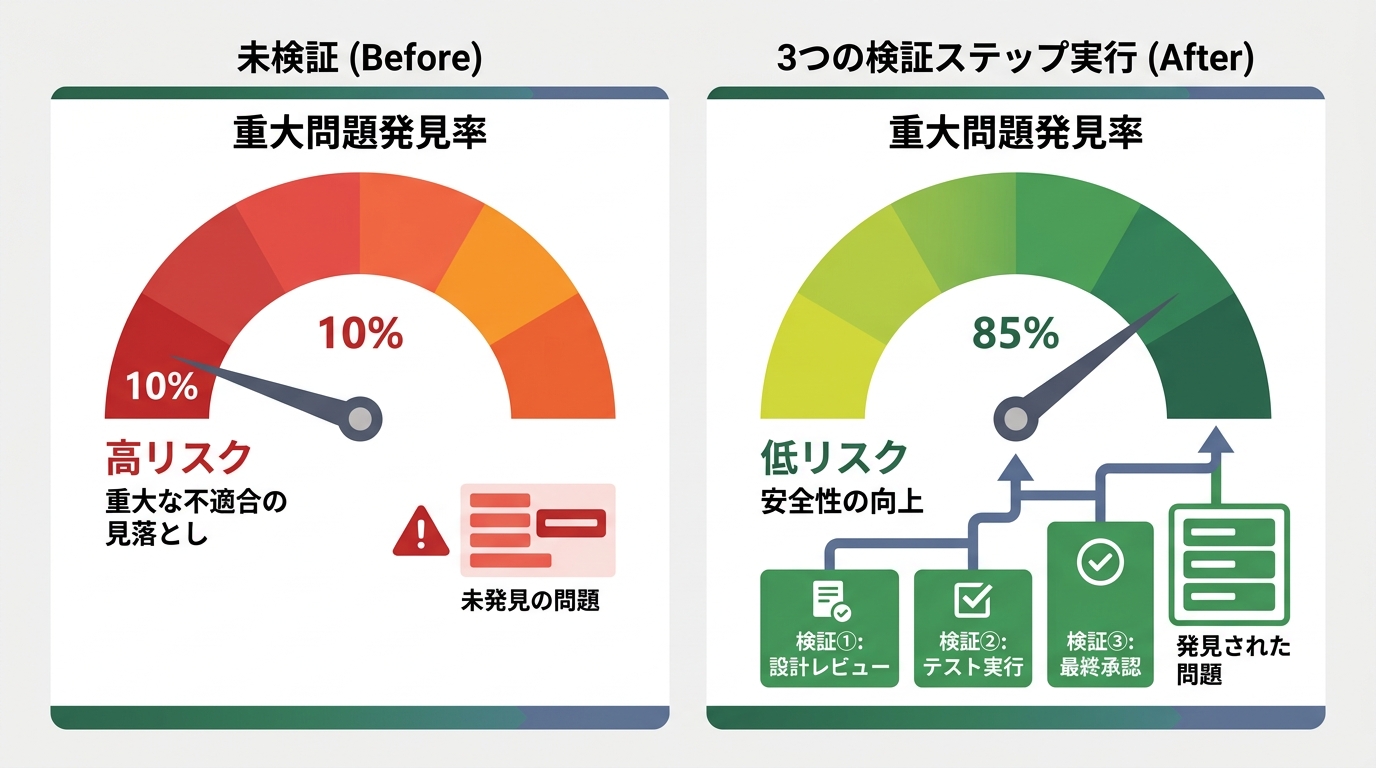
CodeRabbit的分析中显示的安全漏洞2.74倍这个数据看起来可怕。但是,那是在没有验证就推到生产环境的情况下。只要加上10分钟的验证,这个风险就能大幅降低。
CodeRabbit指出的不是「AI不好」,而是「直接相信AI的输出很危险」。这和不是菜刀危险、而是怎么用菜刀的问题,是一个道理。
我在CS时代学到一件事。「上线支持中最重要的不是教会工具的用法,而是让客户具备怀疑工具的视角」。AI编码也适用同样的原理。
总结: 氛围编程不会结束。只是进入下一个阶段
AI写的代码量今后还会继续增加。41%会变成50%,再变成60%。
没有必要阻止这个潮流,也不该阻止。多亏了氛围编程,像曾经的我那样放弃过的人也能再次写代码。我没有打算放弃这场革命。
但是,「写完就结束」的时代已经过去了。
再把”Vibe & Verify”的三个步骤整理一遍。
- 分隔会话: 让生成和验证在不同的上下文中进行(3分钟)
- 让AI解释意图: 让AI把「为什么这样写」语言化(3分钟)
- 从会坏的情况制作测试: 从「怎么会坏」反推生成测试(5分钟)
合计10分钟。这10分钟,能防止3小时的Bug修复。
我今后也会继续用氛围编程做东西。业务工具也好,个人产品也好。但是,做完之后会停下来10分钟。
「跑起来了。然后呢,安全吗?」
把这个问题抛给自己的习惯,我认为就是氛围编程的下一个阶段。要不要再来一次?这次,带上验证。
参考链接

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。


