この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口

三部作を書き終えた翌週に、150万件の流出ニュースが飛び込んできた
先週、私はバイブコーディング安全論争の三部作を書き終えた。
バイブコーディングの170個の裏口。Lovable製アプリ10.3%にセキュリティ欠陥が見つかった件を、元・挫折エンジニアが本気で調べたを掘り下げた。Cursor CEOが「自社ツールは脆い基盤を作る」と認めた日。ゼロクリック脆弱性CurXecuteが突きつけた、バイブコーディングの次の問いを追いかけた。AIに書かせる前に決めろ。Forresterが示した”Secure Vibe Coding”3つの実装原則で、三部作の答え合わせをするで答え合わせをした。
「理論は整った。あとは実践だ」と締めくくったつもりだった。
ところが現実は、理論の先を走っていた。Wiz(ウィズ)のセキュリティ研究チームがブログ記事を公開した。AIエージェント向けSNS「Moltbook(モルトブック)」のデータベースが丸見えだった。流出した情報には、150万件のAPIキーが含まれている。
創業者自身が「1行もコードを書かずにvibe-codedした」と説明していたサービスだ。
同じ週、日本では初の”バイブコーディング検定”がスタートしていた。遊びが制度になり、被害が現実になった。バイブコーディングは「2.0」に入ったと私は感じている。
この記事では、三部作の続きとして「ノリから統制へ」の転換点を整理する。
Moltbook流出で見えた「バイブコーディング初の大規模被害」
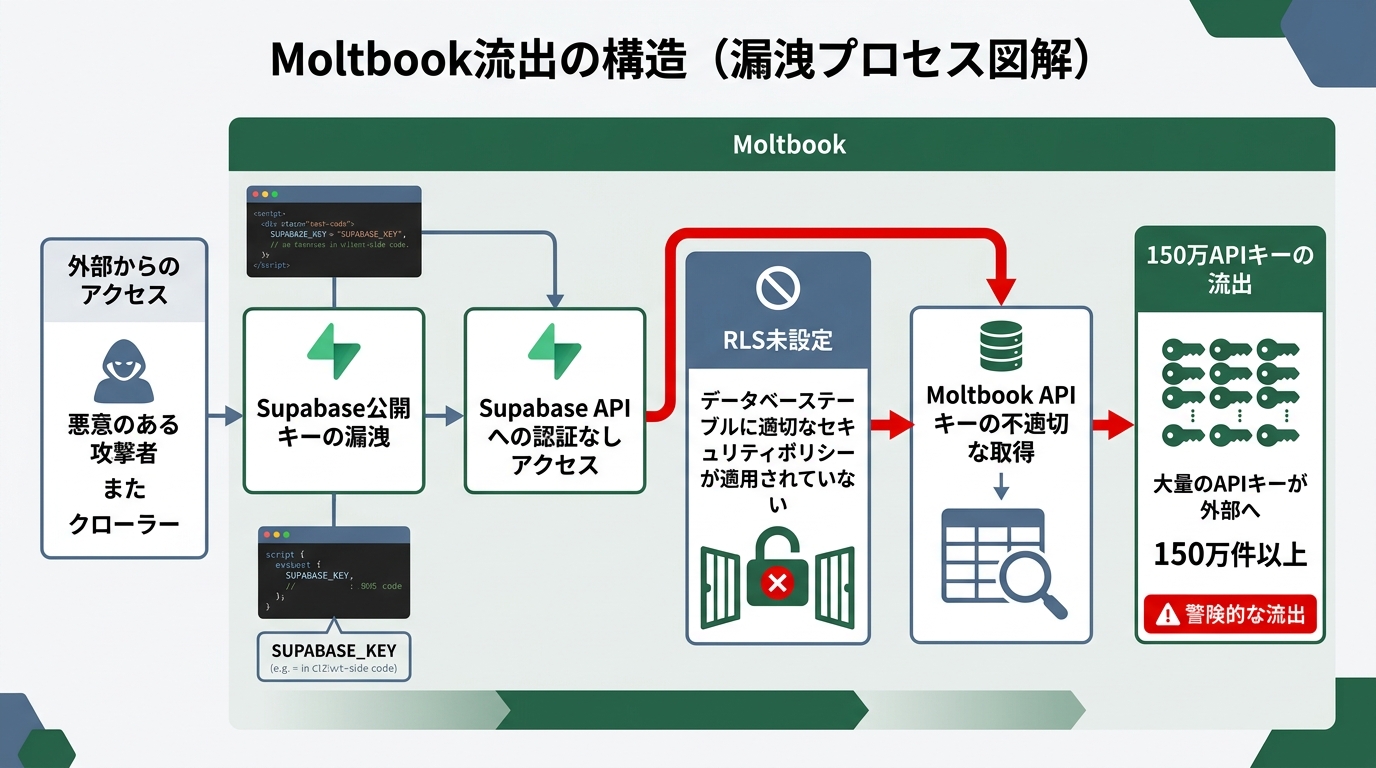
2026年2月、セキュリティ企業Wizが公式ブログで調査結果を公表した。
Moltbookは、AIエージェント同士が投稿しあうSNSだ。注目を集めていたサービスだった。バックエンドにはSupabase(スーパーベース)を使っている。Supabaseとは、データベースや認証機能をまとめて提供するクラウドサービスのこと。問題は、そのデータベースにアクセス制御が未設定だった点にある。
Wizの調査で判明した被害はこうだ。
- 35,000件のメールアドレスが外部から閲覧可能だった
- 150万件のAPIキーが露出していた
- 投稿データへの書き込み権限まで開いており、改ざんが可能な状態だった
原因はAIではない。RLS(Row Level Security)が未設定だったことが本質だ。RLSとは、データベースの行単位で「誰が何を見られるか」を制限する機能のこと。これが入っていなければ、公開キーさえ知っていれば誰でもデータを取得できる。
Reutersもこの件を報じている。ベンダーブログ内で完結する話ではなくなった。
ここで私が注目したいのは、「AIが悪いコードを書いた」のではないという点だ。安全なデフォルト設定を、人間が組まなかった。三部作で書いたForresterの原則「Spec Layer(仕様層)」が抜けていた典型例に見える。
私にはこう映る。「機能は動くけどセキュリティは後回し」は昔からある失敗パターンだ。ユーザーの声を何千回も聞いてきた経験で、嫌というほど知っている。AIがコードを書く時代になっても、この構造は変わっていなかった。
日本初「バイブコーディング検定」が始まった。遊びが制度になる日
Andrej Karpathy(アンドレイ・カルパシー)が“vibe coding”と名づけたのは2025年のことだ。あれから1年で、日本では検定制度が立ち上がった。
2026年、バイブコーディングの基礎知識や実践力を測る検定がスタートした。
「検定ができた」という事実は、2つのことを意味する。
1つ目は、バイブコーディングが一定の市場規模を持つスキルとして認められたこと。趣味や実験ではなく、履歴書に書ける能力として扱われ始めている。
2つ目は、「正しいやり方」と「危ないやり方」の線引きが制度化されたこと。検定があるということは、合格基準がある。「これはやってはいけない」という判断軸が公式に定まったということだ。
Forresterも2026年予測レポートを公開した(会員限定のため参照は各自で確認)。バイブコーディングは“vibe engineering”に進化するという整理だ。コードだけでなく、設計・テスト・運用を含むエンジニアリング全体にAIを組み込む段階に入っている。
Janet Worthington(ジャネット・ワーシントン)のForrester公式ブログも読み応えがある。Cursorを使った自身の体験から、3つのリスクを挙げた。入力サニタイズ不足、レート制限の欠如、平文APIキーの混入だ。「Secure Vibe Codingはパラドックスではなくパラダイムだ」。この表現が印象に残る。
私の三部作で「Spec先行で設計を固めてからAIに書かせる」と書いた。その内容が、制度として裏づけられ始めた感覚がある。「とりあえず動くもん作ろう」が私の哲学だ。ただ「動いた後の安全」は別の筋肉が要る。検定の誕生は、その筋肉を鍛える場所ができたということでもある。
GitHubが2026年3月だけでセキュリティ機能を3回更新した理由
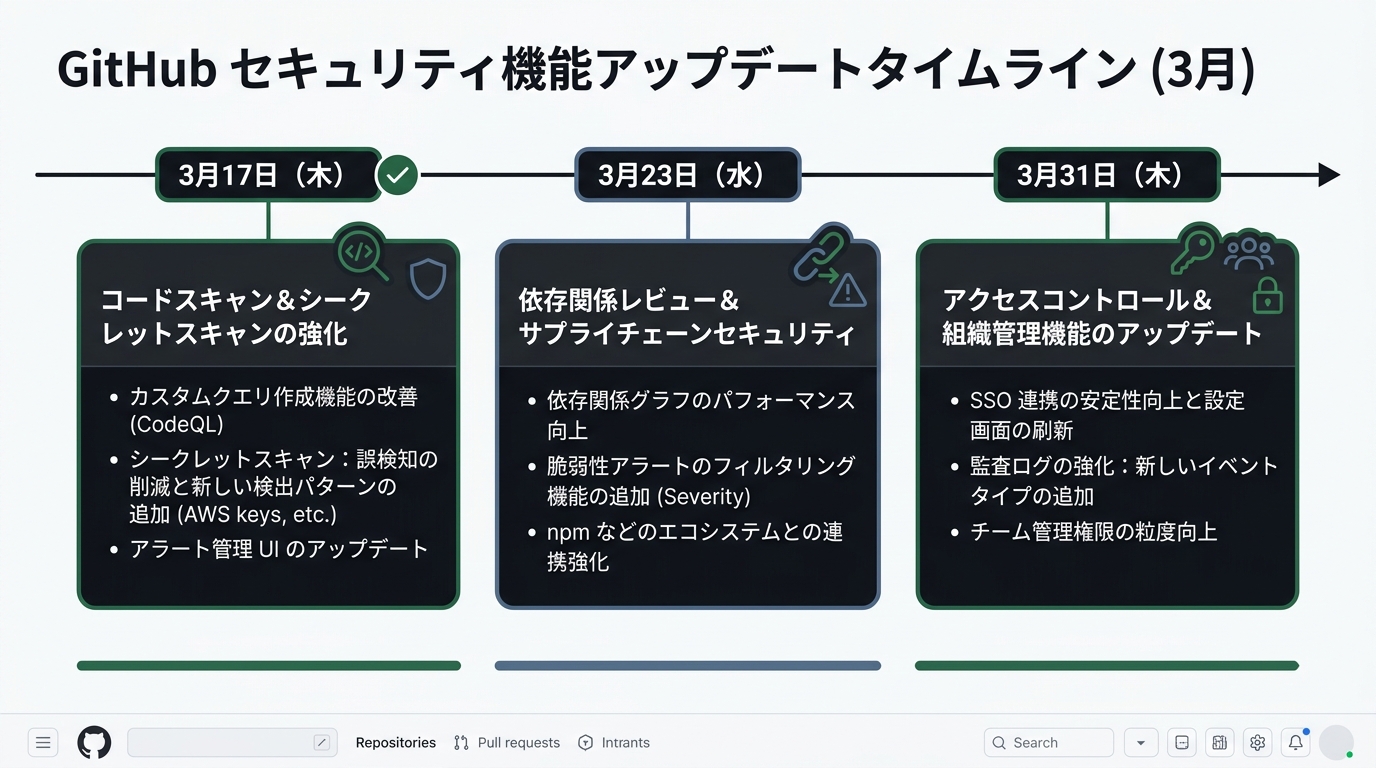
ツール側も急速に動いている。GitHubは3月だけで、3回のセキュリティ関連アップデートを実施した。
3月17日: GitHub MCP Server経由のシークレットスキャンがpublic preview(パブリックプレビュー)になった。
AIコーディングエージェントからcommit前・PR前にスキャンできる。Claude CodeやCursor経由でコードを書いている最中に、APIキーの混入をコミット前に検知できる仕組みだ。Moltbookの150万件流出を思い出してほしい。pre-commitスキャンがあれば、APIキーの露出は防げた可能性が高い。
3月23日: AI-powered detections(AI検知機能)の対象が拡張された。Shell、Bash、Dockerfile、Terraform(HCL)、PHPが加わった。CodeQL(コードキューエル)だけでは拾えなかった範囲を、AIで補完する設計だ。
3月31日: Secret Scanningに9種類の新しいシークレットが追加された。LangChain(ラングチェイン)、Salesforce(セールスフォース)、Figma(フィグマ)が対象だ。
1ヶ月で3回。プラットフォーム側が本気でゲートを張り始めたのがわかる。
もうひとつ見逃せないのがVeracode(ベラコード)のデータだ。2025年のGenAI Code Security Reportでは、100を超えるLLM(大規模言語モデル)を評価した。安全なコードは55%。残りの45%には既知の脆弱性が含まれていた。
「モデルが賢くなれば安全になる」という期待があった。2026年春のアップデートでも、この傾向は大きく改善していない。
NCSC(英国サイバーセキュリティセンター)も3月の公開文書で注目すべき整理をしている。「プロンプトインジェクションはSQLインジェクションではない」という指摘だ。
SQLインジェクションには「命令とデータの境界」がある。入力検証で防げる。一方でLLMには、命令とデータの硬い境界が存在しない。従来のセキュリティ対策のメタファーだけでは足りない。この警告は、バイブコーディングの安全設計で無視できないポイントだ。
「動くコードの45%に脆弱性」が意味する本当のこと

数字をもう少し掘り下げたい。
Stanford(スタンフォード)系の研究チームが公開したSVIBES(スバイブス)ベンチマークがある。SWE-Agent + Claude 4 Sonnet構成で検証した結果だ。機能テストの正解率は61%だった。ところが、そのうち安全だったのは10.5%にすぎない。
この数字が意味することは明確だ。「動くコード」と「安全なコード」は別物だということ。機能テストに合格しても、6本に1本しか安全基準をクリアしていない。
バイブコーディングの世界では「とりあえず動いた」が最初のゴールになりがちだ。私自身もそうだった。Cursorで書いて、Runして、動いた瞬間のあの高揚感。「うわ、動いた!」と声が出る。
とはいえ、動いた瞬間の興奮と、安全に運用できるかどうかは別の話だ。
三部作第3弾で紹介したConstitutional Spec-Driven Developmentのアプローチが参考になる。CWE(共通脆弱性タイプ)やMITRE(マイター)ベースの「憲法」を先に仕様へ埋め込む。この手法で、セキュリティ欠陥を73%削減したと報告されている。
動くコードを書いてから安全にするのではない。安全な仕様を先に定義してからコードを書く。この順序の逆転が、バイブコーディング2.0の核心だと感じている。
4月に公開されたVibeGuard(バイブガード)論文も興味深い。生成コードそのものではなく、3つの出荷前ゲートを提案している。成果物の衛生管理、パッケージングのズレ防止、ソースマップの露出防止だ。論点がコード品質からサプライチェーン衛生へと広がっている。
元・挫折エンジニアの私が「2.0」で変えた3つのワークフロー
理論の話が続いた。ここからは、私自身が三部作を書いた後に実際に変えたことを共有する。
1. Spec(仕様)を先に書く。コードは後
以前の私は、Cursorを開いて「こういうの作りたい」とプロンプトに打ち込んでいた。動くものが出てくる。楽しい。そのまま進める。
今は違う。まずMarkdownファイルに「この機能が満たすべき条件」を箇条書きで書く。入力値の範囲、エラ���時の挙動、アクセス権限の設計。5分で終わる作業だ。ところがこの5分で、後から修正に3時間かかるバグを防げる。
Forresterが言う“Spec Layer”の簡易版だ。前職で要件定義書を何百回も見てきた経験が、ここで活きている。
2. pre-commitフックでシークレットスキャンを自動化
GitHubが3月にリリースしたMCP Server経由のシークレットスキャン機能。これを知って、自分のローカル環境にもpre-commitフックを入れた。コードを保存する前に自動でチェックする仕組みのことだ。
# .pre-commit-config.yaml の設定例
# コミット前にシークレット(APIキーやパスワード)を検知する
repos:
- repo: https://github.com/gitleaks/gitleaks
rev: v8.22.0
hooks:
- id: gitleaks設定は5分で終わる。うっかりAPIキーをコミットするリスクがほぼゼロになる。Moltbookの件を知った後では、この5分を惜しむ理由がない。
3. AIに渡す権限を最小にする
NCSCのSecure AI System Development Guidelinesが参考になる。AIが外部システムやファイル更新を行う場合の3原則だ。最小権限、安全なデフォルト、危険機能のopt-in。
私が業務ツールを作るときも、Claude Codeに任せる範囲を明示的に絞るようにした。「このディレクトリだけ触っていい」「データベースへの書き込みは不可」と伝える。制約を先に渡すことで、生成コードも自然とスコープが狭くなる。
自由にやらせた方が楽だ。ただ、Moltbookの創業者も「自由にvibe-codedした」結果、RLSの設定を見落とした。自由と統制のバランスは、経験がないと難しい。
正直に言うと、最初はめんどくさかった。Spec書いてからコード、フック設定、権限制限。手順が増えると「ノリ」が削がれる気がした。ところが1週間続けてみると、むしろ安心感がある。何も考えずに動かしていた頃より、完成したものに自信が持てる。
CS出身の私は、セキュリティ事故後の対応コストを知っている。事前の5分の設定の何百倍にもなるからだ。「予防に5分、事故対応に50時間」。カスタマーサクセスの現場で嫌というほど学んだ。
バイブコーディング2.0は「書ける」の先にある
ここまでの話を整理する。
バイブコーディングは、3つの段階を経て「2.0」に入った。
- 制度化: 日本初の検定が始まった。Forresterは“vibe engineering”への進化を予測している。遊びが正式なスキルになった
- 実被害: Moltbookで150万APIキーが流出した。バイブコーディングで作ったサービスが、現実の被害を生んだ初の大規模事例になった
- 防御策の加速: GitHubは3月だけで3回のセキュリティ機能追加を行った。Veracodeは「AIコードの45%に脆弱性」と報告している。VibeGuardはサプライチェーン衛生という新しい論点を提起した
私が三部作で書いたのは「こうすれば安全になる」という理論だった。今回書いたのは「理論が足りなかった現実」と「動き始めたツール・制度・ワークフロー」のほうだ。
かつてコードから離れた私が、AIで復活した。その喜びは今も変わらない。「マジで神なんですよ、AIコーディング」と心から思っている。
ただ、神ツールを安全に使うには「ノリ」だけでは足りなくなった。Spec先行、権限最小化、pre-commitゲート。この3つは、今日から5分で始められる。
凄腕エンジニアが自分に宿る体験。それを安全に続けるための統制が、バイブコーディング2.0の本質だと思っている。

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。