DeepSeek V4とKimiが世界トップ2を獲った週、中国は5カ年計画で「AI Plus」を国策化した。元・挫折エンジニアが日本の個人開発者の地図を1枚書き直した話
中国の第15次五カ年計画が新興産業群の産出額目標として「2030年に10兆元超」を掲げた。同じ週、DeepSeek V4とMoonshot AI(Kimi)のモデルが開発者プラットフォームで上位圏に浮上した。日本の個人開発者として、私はこの2つを切り離さずに読んだ。
この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口

中国の国家発展改革委員会(NDRC)の主任、鄭柵潔(Zheng Shanjie)が3月に記者会見で1つの数字を出した。日本でいう内閣府と経済産業省を合わせたような中央省庁のトップが、こう言った。
「2030年までに中国のAI関連産業を10兆元(約1.45兆ドル=約220兆円)規模に拡大する」(People’s Daily 2026-03-06、Internet Archive保存版)。
これは第14期全国人民代表大会の第4回会議に合わせた発表だった。2026〜2030年の「第15次五カ年計画」の柱の1本に据えられている。
CCTVはこの数字を「次世代IT・AI・バイオ・宇宙・新エネルギーなど6つの新興支柱産業」の合算産出額目標として報じている(CCTV 2026-03-06)。AI産業だけを切り出した数字ではなく、新興産業群の総量として理解するのが正確だ。本記事では「AI関連産業を中心とした成長目標」として扱う。
私は最初、この数字を見たときに「ふーん、また大きな数字を出したな」と思った。中国政府の数値目標はだいたい大きい。そういう前提で読み流すクセがついている。
でも翌日、別のニュースが流れてきた。
DeepSeekが「V4」を発表した。同じ週、Moonshot AI(Kimi)も新モデルをリリースする。両方ともオープンソース。世界の開発者が集まるOpenRouterで、この2社のモデルが使用量の上位圏に入る動きが報告された(Fortune 2026-04-24、Internet Archive保存版)。
ここで私はようやく気がついた。「政策の10兆元」と「先週のDeepSeek V4」は別ニュースじゃない。1つの動きの上下の層だ。
私は元・挫折エンジニアだ。プロのエンジニアには敵わないと思って一度コードから離れて、AIで戻ってきた人間。だから普段は「自分の業務を楽にする小さなツール」を作っている。中国の国家戦略なんて、自分には関係ないと思っていた。
でも今回ばかりは関係なくない。私が来週Cursor Composer 2に流すバックエンドモデルが、Kimi系(同じく中国製)の可能性は十分ある。私が今日触ったオープンソースモデルが、来月「中国国策10兆元」の一部としてカウントされる未来も普通にあり得る。地図が重なってしまった。
この記事でやるのは3つ。①中国5カ年計画の公式数値と外部分析値を全部並べる。②なぜそれが日本の個人開発者の足元に降りてくるのか。③「飲み込まれない側」に立つために今週から変える3チェック。読み終わったら、自分の開発スタックを1回見直す材料が手元に残る。そういう記事にする。
中国5カ年計画の重要数値を、まず全部並べる
意見の前に事実だけ並べる。これがハマりポイントを減らすコツ。
まず1つ目の公式数値。AI関連産業10兆元(約1.45兆ドル)。2030年達成目標。鄭柵潔NDRC主任が2026年3月6日に記者会見で発表した(Xinhua 2026-03-06英語版、Internet Archive保存版)。
10兆元とは、日本円でおよそ220兆円。日本のGDPがおよそ600兆円なので、その3分の1強の規模を「AI関連新興産業群」というセクター全体で作る計画になる。
2つ目。「Intelligent Economy(智能経済)」というキーワード。中国の李強首相が2026年3月の政府活動報告で初めて使った(China Daily 2026-03-06、Internet Archive保存版)。
これは単に「AIの売上を増やす」という話ではない。「経済全体の動かし方をAI前提に組み直す」というスローガンに変わったということ。日本でいう「Society 5.0」よりも具体的で、産業ごとの数値目標がぶら下がる構造になっている。
3つ目の公式数値。サービス産業全体は2030年までに100兆元(約14兆ドル=約2,100兆円)規模を目指す。AIとスマートコーディングツールがその中心に据えられている(Caixin Global 2026-04-22、Internet Archive保存版)。
加えて外部分析の参考値も一つ押さえておく。The Diplomatは「AI Plus」の展開速度から、「中国は経済の9割をAIで覆うことを目標にしている」と分析した。外部アナリストが逆算した試算だ(The Diplomat 2026-03、Internet Archive保存版)。
90%という数字は中国政府の公式文書ではなく、外部分析が試算した参考値だ。「全産業の9割」という表現がメディアに乗った事実は重い。市場の期待値が変わる。だが公式の2数値(10兆元・100兆元)と同列に扱うと誤読を招くため、参考値として読んでほしい。
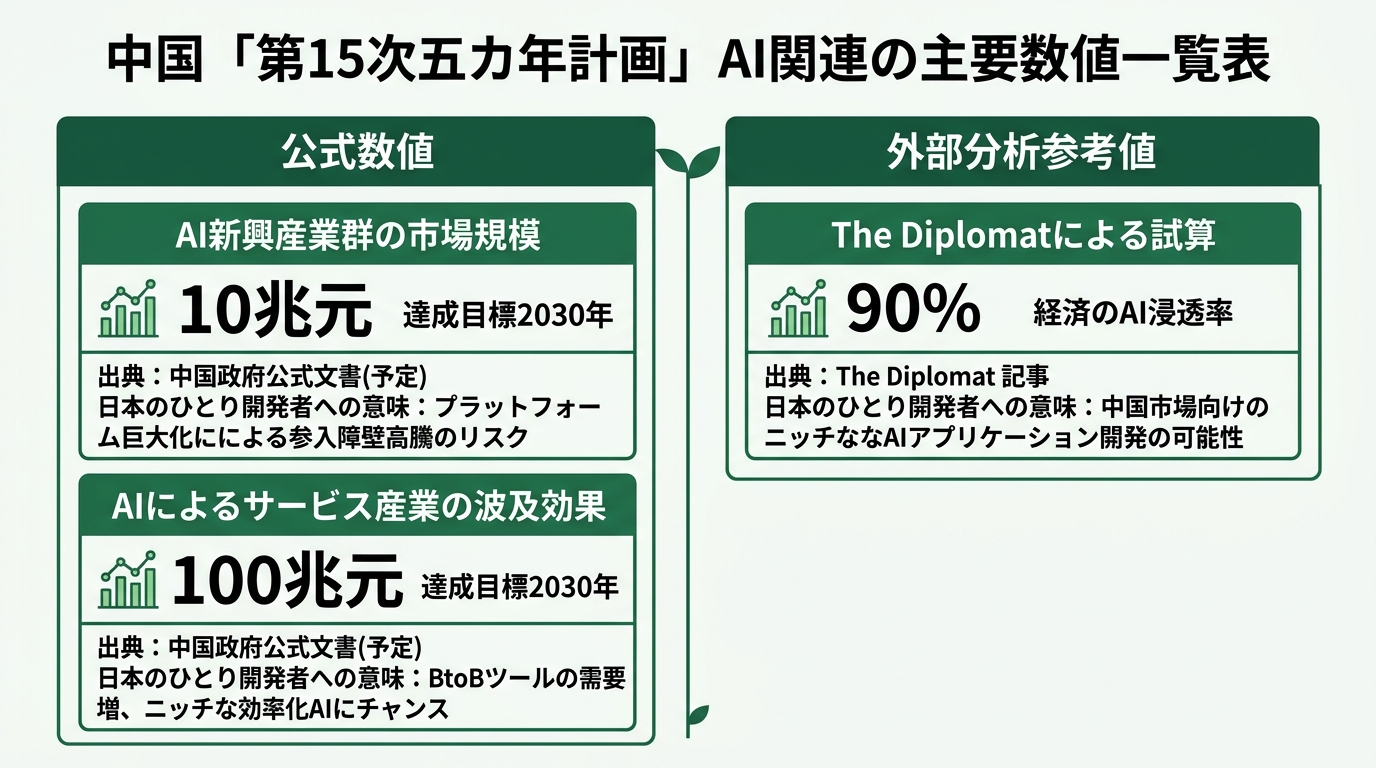
つまり2つの公式数値(10兆元・100兆元)と外部分析の試算(90%)は連動して読める。AI産業10兆元を作って、経済の9割(外部試算)にAIを染み込ませて、サービス産業100兆元の中心にAIとコーディングツールを置く。3本の数字を独立で読まずに、重ねて読む。これが「なぜ中国がオープンソースモデルにここまで賭けるか」を理解する入口になる。
ここまで並べると、私のような個人開発者は「で、私のCursorとClaude Codeに何が起きるの?」と思う。同感。次のセクションでそこに降りる。
DeepSeek V4とMoonshot AI(Kimi)が「上位圏」に入った週、何が起きたのか
事実から。
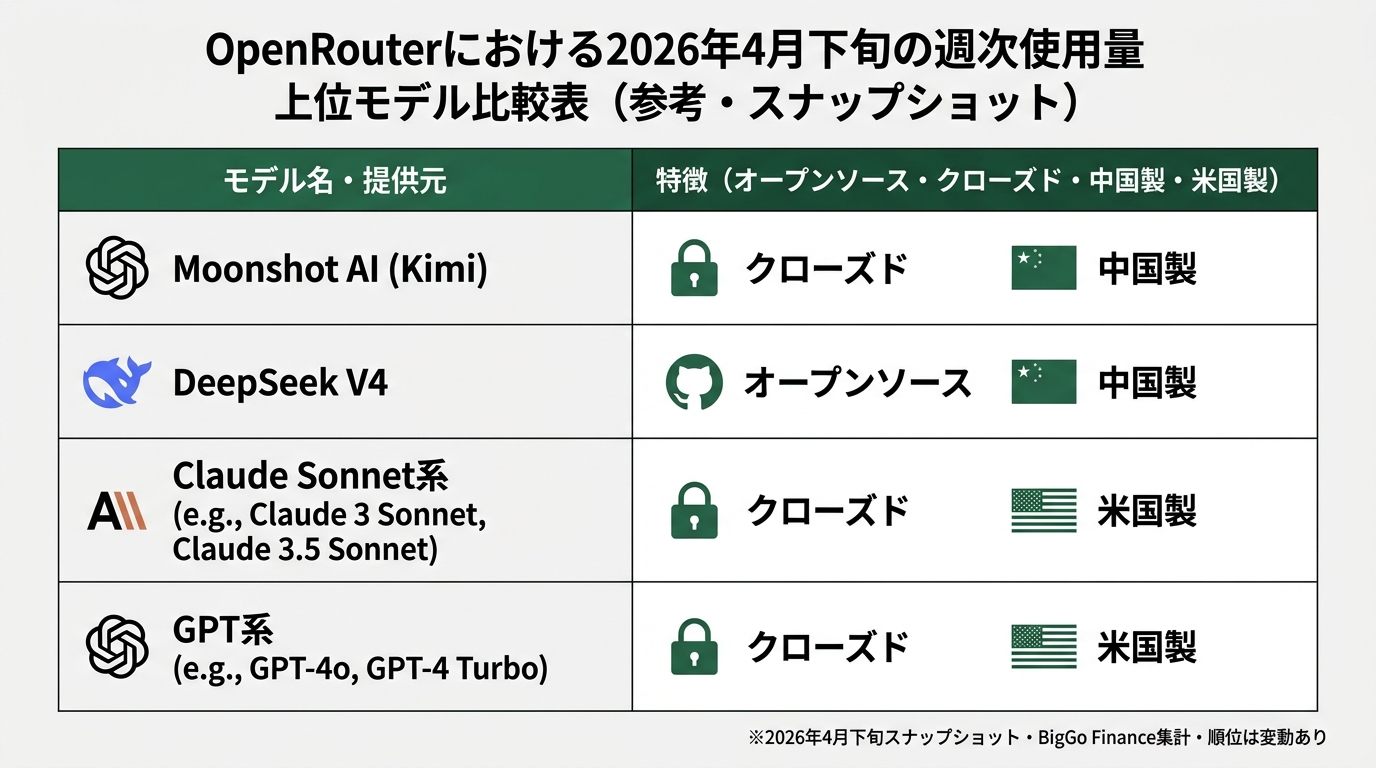
2026年4月24日、DeepSeekが「V4」モデルを発表した。Huaweiの国産AIチップとの統合が深まり、推論コストは前世代比でさらに低い水準だ。同じ週、Moonshot AI(Kimi)も大型モデルをリリース。両方ともオープンソース、つまり誰でもダウンロードして自社サーバで動かせる(CNN Business 2026-04-24、Internet Archive保存版)。
世界の開発者がモデルを呼び出すルーティングプラットフォームに「OpenRouter(オープンルーター)」というサービスがある。Anthropic、OpenAI、Google、Meta、その他あらゆる企業のモデルがここで横並びになり、開発者がコスト・性能で選べる。このOpenRouter上で、DeepSeekとMoonshot AI(Kimi)のモデルが上位圏に浮上したことが報告された(BigGo Finance 2026年4月、Internet Archive保存版)。
なお、DeepSeek V4のweekly rankingsへの本格的な浸透はリリース直後であり、後続の週で上位の顔ぶれが変動する可能性もある。本データは2026年4月下旬時点のスナップショットとして読んでほしい。
これがどれくらい注目すべき動きか説明する。
2025年4月、OpenRouterの上位はAnthropic Claude・OpenAI GPT-4o・Google Geminiが占めていた。中国製モデルの席は「話題ではあるが本番採用は少ない」あたり。それが1年でDeepSeekとKimiが上位圏に並ぶ状況になった。
そしてここから先が重要。DeepSeek V4はMoonshot AIが先に検証した「Muonオプティマイザ」(学習を速くする計算手法)を採用した。逆に以前のKimi K2は、DeepSeekが先に作った「MLA」を取り込んでいた。MLAとはMulti-head Latent Attentionの略で、メモリを節約する注意機構のことだ(BigGo Finance 技術レビュー、Internet Archive保存版)。
平たく言うと、中国のオープンソースAI企業同士が「お互いの良いとこ取り」を繰り返している。米国の企業は基本的に技術を公開しない。中国の企業は公開して、お互いに使い合っている。これがオープンソースのスケール感を加速させた。
MIT Technology Reviewは「中国のオープンソースAIモデルは、ダウンロード数で米国モデルを抜いた」と報じた(MIT Technology Review 2026-02-12、Internet Archive保存版)。総数で抜いた。これはポイント。
ここで「政策の10兆元」と「DeepSeek V4・Kimiの使用量急増」が同じ線でつながる。政策が「AI Plus」「経済のAI浸透」を掲げて、その一階下でオープンソース連合が技術を出し合い、その下のレイヤーで個人開発者が無料で使える。3階建ての構造で回り出した。
私のような日本のひとり開発者は、その3階目を毎日触っている側だ。今この瞬間、業務ツールのバックエンドに何のモデルを呼び出しているか、選択肢のリストが2026年4月時点で確実に変わった。
中国AIエコシステムを「3層」で見る——日本の個人開発者の参入レイヤーはどこか
ここから設計の話。私が中国AIニュースをパニックで読まずに済むようになったのは、エコシステムを「3層」で分けて見るようになってからだ。
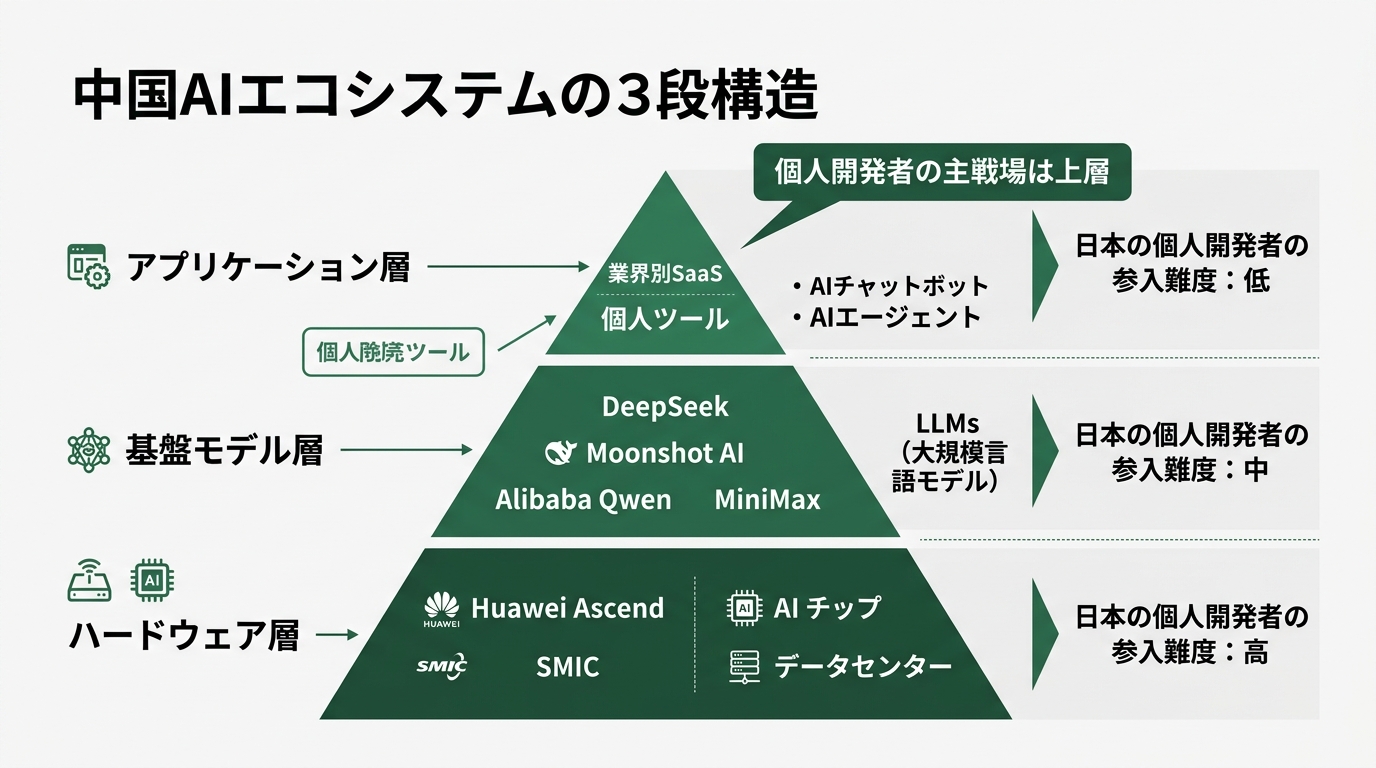
第1層は「ハードウェア層」。Huawei Ascendチップ、SMICの製造プロセス、データセンター。中国政府の補助金と国策が直接効くレイヤー。日本の個人開発者が参入する余地はゼロ。これは事実。Huaweiのチップを個人で買えるかというと、原則として中国国内向け。製造業に関わる仕事をしていない限り、関係ない世界。
第2層は「基盤モデル層」。DeepSeek、Moonshot AI(Kimi)、Alibaba Qwen、MiniMax、Knowledge Atlas、その他。1モデル作るのに数百億円かかる。個人開発者が「自分でこのレイヤーのモデルを作る」のは現実的じゃない。ただし「使う」のは別。オープンソースなので、ダウンロードすれば自分のサーバで動かしてもいいし、OpenRouter経由でAPI呼び出しでも構わない。Hugging Faceで検証だけ走らせる選択肢もある。
ここまでで2層。私のような個人開発者の参入余地はほぼない。問題は3層目。
第3層は「アプリケーション層」。これは中国国内市場が異常に大きいので、中国国内向けアプリは中国企業が圧倒的に強い。でも「世界の業務課題をAIで解く小さなツール」というレイヤーは、まだ国境を持たずに開いている。Moonshot AIの記事構成生成、DeepSeekのコード生成、Qwenの翻訳、これらを組み合わせた業務ツールは、地理的優位性なしに作れる。
私が普段作る業務ツールは、第3層のアプリケーション層だ。問い合わせ分類Bot、契約書ドラフト生成スクリプト、Slackメンション集計ダッシュボード。こういったCSや社内業務を補助するものがそれにあたる。ここはまだ「先に作った人」が勝つレイヤー。
で、ここで日本の個人開発者にとって大きいニュースが2つある。
1つ目。第2層のオープンソースモデルが世界の上位圏に入ったことで、第3層のコストが下がる。私が1ヶ月前、自分のSlack Botを動かすのにOpenAI APIで月額40ドルくらい払っていた。同じものをDeepSeek V4経由で動かしたら、おそらく月額5〜10ドルに下がる(試算、実測前)。これは「同じツールを10倍の頻度で使える」を意味する。
2つ目。ナギの4/19記事が報じた通り、Kimi K2.5ベースのモデルがCursor Composer 2の中核に採用された。中国製モデルは「中国だけのもの」という枠を超えてしまった。世界の開発ツールの中に普通に組み込まれ、私たちが意識せずに使う場面が増えた。
ここで「中国の国策に飲み込まれているのでは?」という疑問が当然出てくる。私もそう感じた。次のセクションでそこに踏み込む。
それでも私が「中国AI産業に飲み込まれない」と思える3つの理由
正直に話す。「日本の個人開発者として中国AIに依存しすぎていいのか」は、私自身まだ答えが揺れている問い。だから断言ではなく「私の現在の整理」として読んでほしい。
第1の理由。アプリケーション層は「業務理解の深さ」で勝つレイヤー。
DeepSeekやKimiは「世界中の汎用知識」で学習している。でも私が作るSlack Botは「私の会社の問い合わせ分類」でファインチューニングする。私が作る業務ツールは「私の部署の人がどこで詰まるか」をユーザーインタビューで吸い上げて作る。この「現場の業務理解」は、中国のオープンソースモデルがどれだけ強くなっても、私のスキルを直接置き換えない。
私は元CSだ。サポートで何千件もチケットを見てきた。「ここでユーザーは諦める」「ここで返信が来なくなる」のパターンが体に入っている。この情報は、論文にもMIT Tech Reviewにも載らない。私のローカルな業務知識。これがアプリケーション層での個人開発者の最大の防御壁になる。
第2の理由。オープンソースモデルは「使われる側」の競争。
中国がオープンソースを国策で推す理由は、米国の閉じたモデルへの対抗策として「世界のデファクト」を取りに行くため。これは「中国にとってDeepSeekやKimiが世界中で使われたほうが得」という構造。だから私たちは「使う側」として歓迎されている。レイヤーごとの戦略の違いを理解しておけば、感情的に振り回されずに済む。
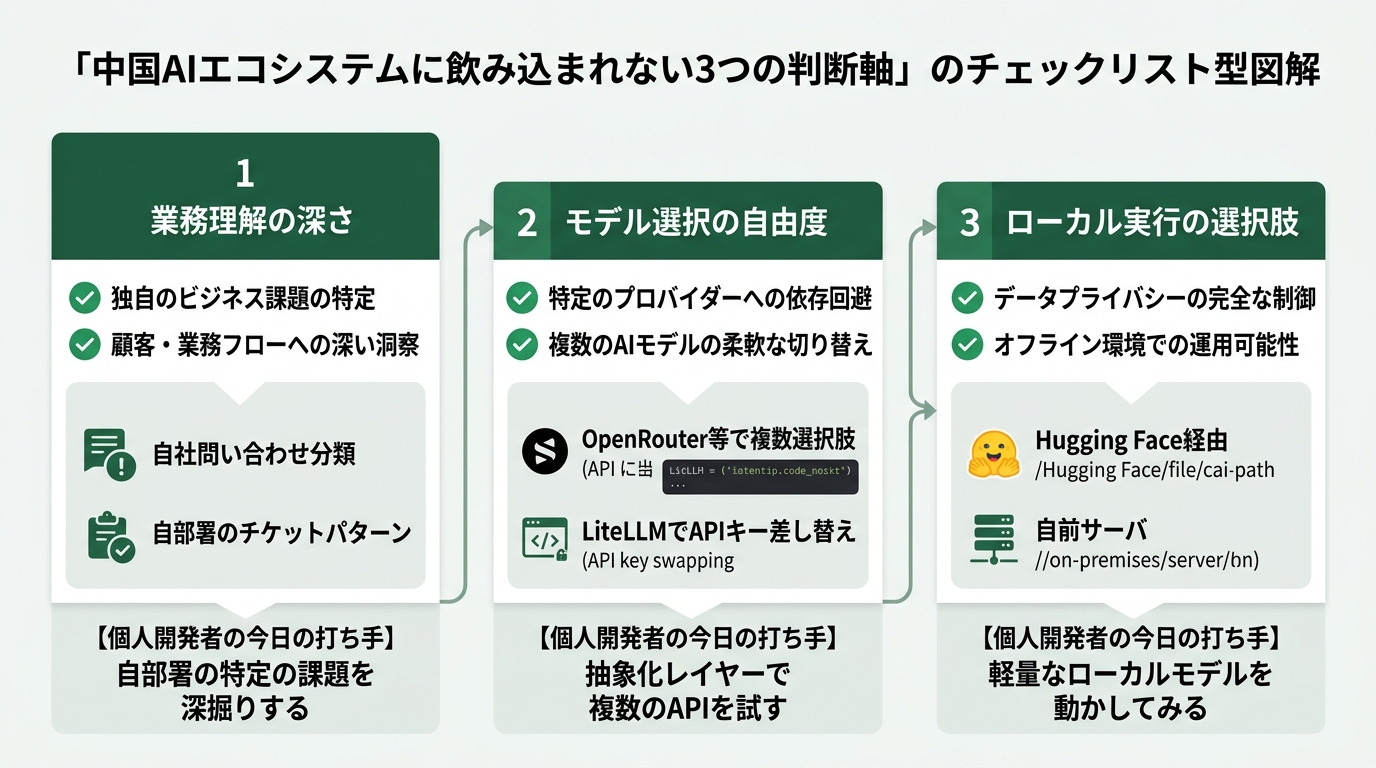
第3の理由。「複数モデルを並列で使う」が個人開発者の標準になりつつある。
OpenRouterの存在自体が証明している。1つのモデルに依存せず、タスクごとに最適なモデルを呼び分ける。コード生成はClaude、長文要約はMoonshot AI(Kimi)、安価なテキスト分類はDeepSeek、画像はGoogle Imagen、というふうに。これが個人開発者の「中国AI依存リスクの分散」の実装。
私は今、自分の業務ツールに「LiteLLM」というルーティングライブラリを噛ませて、モデルをいつでも切り替えられる構成にしている。Hugging Face上で各モデルが廃止されるリスク、APIの値上げ、政治的な利用制限——どれが起きても、設定ファイル1行の書き換えで別モデルに切り替えられる。これがアプリ層に立つ個人開発者の「飲み込まれない設計」だ。
ただし、ここで気をつけたい点が1つある。中国製オープンソースモデルを業務利用するときの「データ送信先」は要確認。OpenRouter経由で呼び出すと、どこのサーバに自分の入力テキストが送られるか、ルーティング先によって変わる。社外秘・個人情報を扱うツールでは、ローカル実行(自分のサーバで動かす)か、信頼できるホスティング先を選ぶ必要がある。これは中国製・米国製を問わず同じ話だが、特に意識して設計したほうがいい。
元・挫折エンジニアの「今日からの3チェック」
ここまでの整理を、今日触れる業務ツールに落とす。私が実際に今週から変えた3つのチェック項目を共有する。
第1チェック。「自分の業務ツール、モデルロックインしていないか?」
私は半年前まで、業務ツールのコードに「OpenAI API」を直書きしていた。この瞬間からモデルを切り替えるには、コードを10箇所書き換える必要がある。これがロックイン。
対策としてLiteLLMやLangchainのモデル抽象化レイヤーを噛ませる。これだけで「APIキーと環境変数の差し替え」でモデルを切り替えられるようになる。Cursor Composer 2でも、Claude CodeのCustomコマンドでも、設定ファイルで切り替えられる構成を意識する。これがロックイン回避の最初の一歩。
ちなみに私は最初これをやらずに、3時間かけてOpenAIのコードをClaude SDKに書き換えた経験がある。「ここハマりますよ」と先に言っておきます。
第2チェック。「自分のツール、コスト試算をモデル別にできているか?」
業務ツールを作るとき、私は「月額いくらで運用できるか」を計算する。1リクエストあたりのトークン数(入力+出力)×単価。これを今、4つのモデルで試算するクセをつけた。OpenAI GPT-4o、Claude Sonnet系、DeepSeek V4、Moonshot AI(Kimi)。同じワークロードを流して、月額コストを比較。
DeepSeek V4の単価は2026年4月時点で、米国系モデルの数分の1(Fortune 2026-04-24)。ただし精度・レスポンス速度・データ送信先の3点で米国系と差が出る場合がある。「とりあえず一番安いやつ」ではなく「自分のユースケースに必要な品質を満たす最安」を見つける。これが個人開発者のコスト設計力。
第3チェック。「自分の業務知識、モデルが届かないところに溜めているか?」
これが一番大きい。中国AIエコシステムが進化しても、私が現場で吸い上げた業務知識は、私だけが持っている資産だ。「ここでユーザーが詰まる」「この問い合わせのパターンは月末に増える」「営業部のこの人にメンション飛ばすと止まる」。こういった知識はどんなモデルにも載らない。
この資産を、AIに食わせるためのドキュメントとして残す。Slackの過去ログ、問い合わせ対応のスクリプト、ユーザーインタビューのメモ。私はこれをNotionに「業務知識バンク」として溜めている。新しいモデルが出るたびに、このバンクを食わせ直して、自分専用のRAG(Retrieval-Augmented Generation、検索拡張生成)を組み直す。これが個人開発者の「中国AIに置き換わらない自分」の作り方。
ナギが先週書いた「研修だけ症候群を抜けて自分の業務にAIを使う流れ」と通じる発想。受け身で外のモデルを使うのではなく、自分の業務知識を主体に据えて、モデルは交換可能な道具として扱う。
まとめ——中国の動きは「脅威」ではなく「地図書き換えのトリガー」
最後にまとめる。
中国の第15次五カ年計画は、AI新興産業群10兆元・サービス業100兆元の2つの公式数値を打ち出した。外部分析も「経済の9割をAIで覆う」方向性を読み取り、世界のAIの地殻変動は加速している。同じ週に出たDeepSeek V4とMoonshot AI(Kimi)のOpenRouter上位圏浮上は、その地殻変動の表面に出た現象だ。
日本の個人開発者にとって、これは脅威じゃない。地図の書き換えのトリガー。「中国のニュースだ、関係ない」と読み飛ばすのではなく、「自分の開発スタックの選択肢が確実に変わった」と読む。
私の今日の3アクションをもう一度書く。①モデル抽象化レイヤーを業務ツールに噛ませる(LiteLLMやLangchainで)。②4モデル(OpenAI・Claude・DeepSeek・Moonshot AI)でコスト試算するクセをつける。③自分の業務知識を「モデルが届かないところ」に溜める(Notionや社内ドキュメントで)。
これは「中国AIに飲み込まれない側」に立つための、私のような個人開発者の最低限の設計判断。プロのAI企業がやることと比べたら小さい。でも私たちは「自分の業務を楽にするコードなら書ける」側の人間。その小さなコードの積み重ねで、毎日の仕事が3時間軽くなる。それが個人開発者の勝ち筋だと、元・挫折エンジニアの私は思っています。
中国の動きを最後にもう一度読む。10兆元・100兆元。この2つの公式数値を覚えておくと、来月以降に出てくる中国AIニュースが「点」ではなく「線」で見える。「ああ、5カ年計画のあの目標に向かう動きか」と。情報を地図で読めるようになると、振り回されずに済む。それだけでも、今週この記事を読んだ価値があると、私は信じています。

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。