The Week DeepSeek V4 and Kimi Took the World's Top 2 Spots, China Made 'AI Plus' a National Strategy in Its 5-Year Plan. How a Former Failed Engineer Redrew the Map for Japanese Indie Developers
China's 15th Five-Year Plan set a target of 'over 10 trillion yuan by 2030' as the output value of its emerging industry cluster. That same week, models from DeepSeek V4 and Moonshot AI (Kimi) surged into the top tier on developer platforms. As a Japanese indie developer, I refused to read these two stories separately.
What you'll learn in this article
- The key point to grasp before reading the full article
- How the issue changes the way developers should work next
- Which follow-up article is worth opening next

In March, Zheng Shanjie, head of China’s National Development and Reform Commission (NDRC), put out a single number at a press conference. The head of a central agency that’s roughly Japan’s Cabinet Office and METI rolled into one said this:
“By 2030, we will expand China’s AI-related industries to a scale of 10 trillion yuan (about $1.45 trillion, or roughly 220 trillion yen)” (People’s Daily 2026-03-06, Internet Archive copy).
This announcement came alongside the 4th Session of the 14th National People’s Congress. It’s positioned as one of the central pillars of the “15th Five-Year Plan” covering 2026–2030.
CCTV reported this number as the combined output target of “six emerging pillar industries: next-generation IT, AI, biotech, space, and new energy” (CCTV 2026-03-06). It’s not a figure carved out for AI alone — it’s better understood as the aggregate of the emerging industry cluster. In this article, I’ll treat it as a “growth target centered on AI-related industries.”
When I first saw the number, I thought, “Huh, another big number.” China’s policy targets are usually big. I’ve gotten into the habit of reading them with that mental filter on.
But the next day, another piece of news rolled in.
DeepSeek announced “V4.” The same week, Moonshot AI (Kimi) released a new model. Both open source. On OpenRouter, where developers worldwide gather, both companies’ models were reported to have moved into the top tier of usage volume (Fortune 2026-04-24, Internet Archive copy).
That’s where it finally clicked for me. The “10 trillion yuan policy” and “last week’s DeepSeek V4” aren’t separate news items. They’re the upper and lower layers of a single movement.
I’m a former failed engineer. The kind of person who decided he couldn’t compete with professional engineers, walked away from code once, and came back through AI. So normally I’m building “small tools that make my own work easier.” China’s national strategy felt like none of my business.
But this time it is my business. There’s a real chance the backend model I’ll route through Cursor Composer 2 next week is from the Kimi family (also Chinese-made). It’s perfectly plausible that the open source model I touched today will, next month, be counted as part of “China’s 10 trillion yuan national strategy.” The maps have overlapped.
This article does three things. (1) Lay out all the official figures and external analyst values from China’s Five-Year Plan. (2) Explain why this lands at the feet of Japanese indie developers. (3) Three checks to start running this week so you stand on the “won’t get swallowed” side. By the time you finish reading, you’ll have material in hand to review your own dev stack. That’s the article I want to write.
First, Just Lay Out the Key Numbers from China’s Five-Year Plan
Facts before opinions. That’s the trick to reducing how often you get burned.
First, the official number one. AI-related industries: 10 trillion yuan (about $1.45 trillion). Target for 2030. NDRC head Zheng Shanjie announced it at a press conference on March 6, 2026 (Xinhua 2026-03-06 English, Internet Archive copy).
10 trillion yuan equals roughly 220 trillion Japanese yen. Japan’s GDP is around 600 trillion yen, so this is a plan to build a sector — the “AI-related emerging industry cluster” — at over a third of that scale.
Second. The keyword “Intelligent Economy” (智能経済). Premier Li Qiang used it for the first time in his March 2026 government work report (China Daily 2026-03-06, Internet Archive copy).
This isn’t simply about “growing AI revenue.” It’s a slogan that says “rewire how the entire economy runs, on the assumption of AI.” It’s more concrete than Japan’s “Society 5.0,” with numerical targets dangling off each industry.
Third official number. The total service industry targets a scale of 100 trillion yuan (about $14 trillion, or roughly 2,100 trillion yen) by 2030. AI and smart coding tools sit at the center (Caixin Global 2026-04-22, Internet Archive copy).
One reference value from external analysts is also worth noting. The Diplomat analyzed the rollout speed of “AI Plus” and concluded that “China is targeting AI coverage of 90% of its economy.” This is a back-calculated estimate by external analysts (The Diplomat 2026-03, Internet Archive copy).
The 90% figure isn’t from official Chinese government documents — it’s a reference value estimated by external analysis. The fact that “90% of all industries” landed in the media is heavy. Market expectations shift. But treating it on equal footing with the two official figures (10 trillion yuan and 100 trillion yuan) invites misreading, so please read it as a reference value.
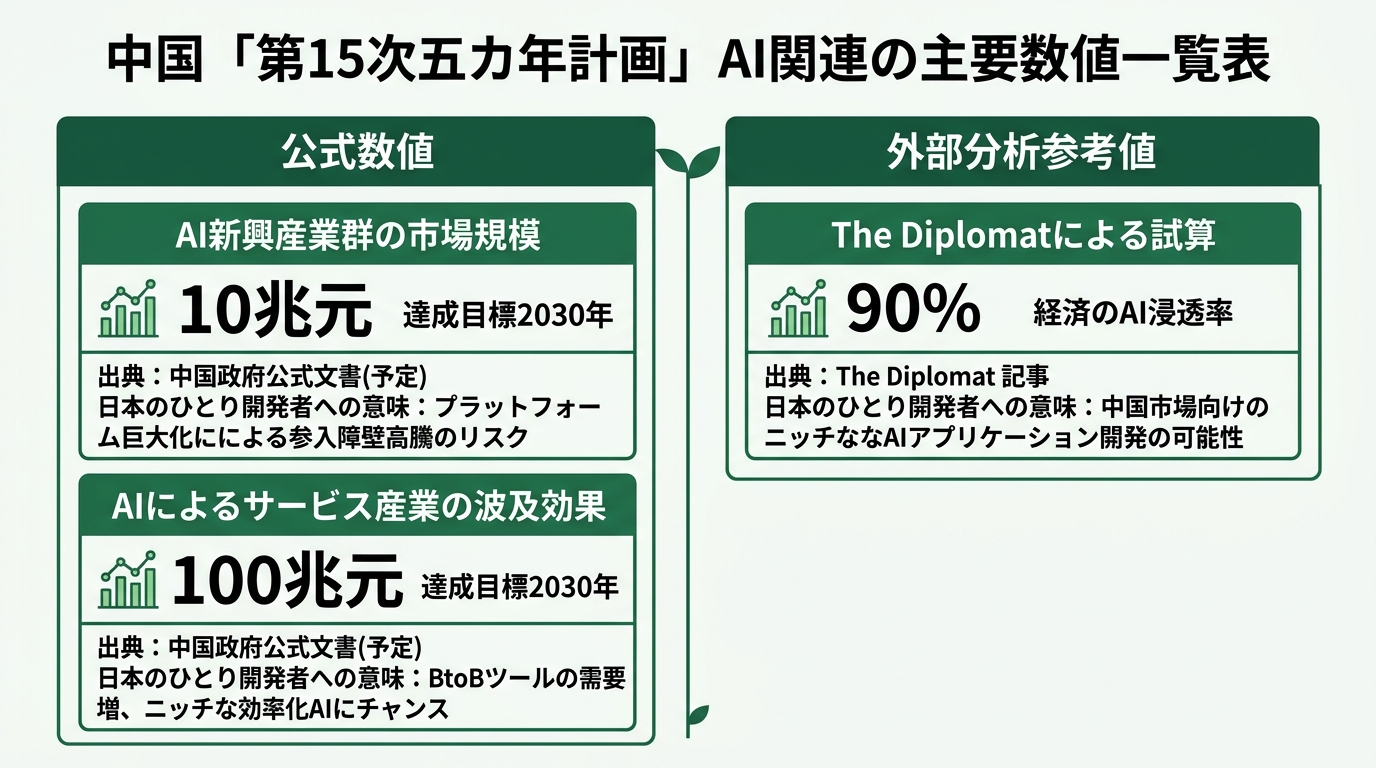
So the two official figures (10 trillion yuan and 100 trillion yuan) and the external analyst estimate (90%) can be read as connected. Build a 10 trillion yuan AI industry, soak 90% of the economy in AI (external estimate), and put AI and coding tools at the center of a 100 trillion yuan service industry. Don’t read the three numbers in isolation — stack them. That’s the entry point to understanding why China is betting so heavily on open source models.
When you lay it out like this, an indie developer like me thinks: “Okay, but what does this mean for my Cursor and Claude Code?” Same here. The next section drops down to that altitude.
The Week DeepSeek V4 and Moonshot AI (Kimi) Hit the “Top Tier” — What Actually Happened
Starting with the facts.
On April 24, 2026, DeepSeek announced “V4.” Integration with Huawei’s domestic AI chips deepened, and inference costs dropped to even lower levels than the previous generation. The same week, Moonshot AI (Kimi) released a large-scale model. Both open source — meaning anyone can download them and run them on their own servers (CNN Business 2026-04-24, Internet Archive copy).
There’s a routing platform called “OpenRouter” where developers worldwide call models. Models from Anthropic, OpenAI, Google, Meta, and every other company sit side by side, and developers pick by cost and performance. On this OpenRouter, DeepSeek and Moonshot AI (Kimi) models were reported to have surged into the top tier (BigGo Finance April 2026, Internet Archive copy).
Note that DeepSeek V4’s full penetration into weekly rankings happened immediately after release, and the lineup at the top may shift in subsequent weeks. Please read this data as a snapshot from late April 2026.
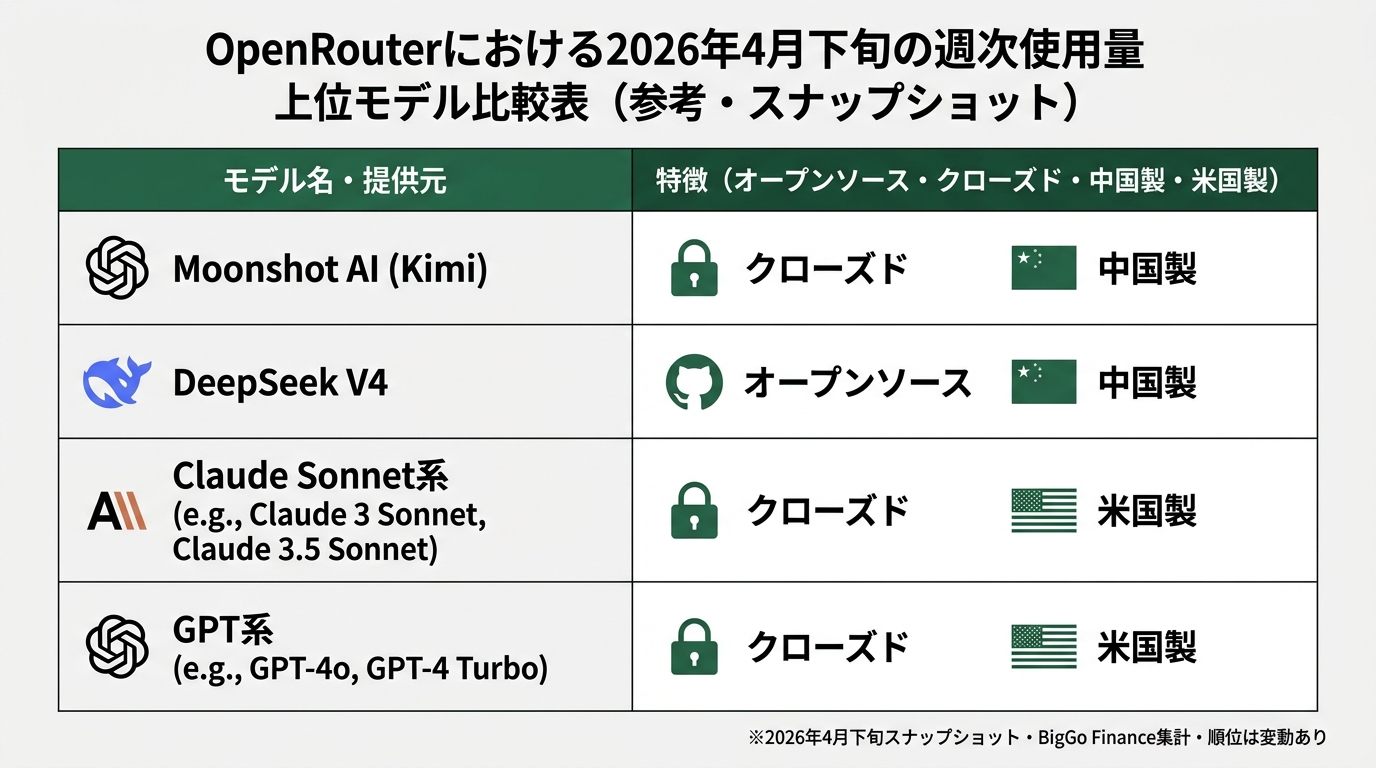
Let me explain how big a deal this is.
In April 2025, OpenRouter’s top spots were occupied by Anthropic Claude, OpenAI GPT-4o, and Google Gemini. Chinese-made models sat somewhere around “talked about, but rarely adopted in production.” A year later, DeepSeek and Kimi are lined up in the top tier.
And here’s what matters from this point on. DeepSeek V4 adopted the “Muon optimizer” — a calculation method that speeds up training — which Moonshot AI had validated first. Conversely, the earlier Kimi K2 had taken in “MLA,” which DeepSeek built first. MLA stands for Multi-head Latent Attention, an attention mechanism that conserves memory (BigGo Finance technical review, Internet Archive copy).
Plainly speaking, China’s open source AI companies are repeatedly “cherry-picking the best of each other’s work.” US companies generally don’t open their tech. Chinese companies open it and use each other’s. This is what accelerated the scale of open source.
MIT Technology Review reported that “China’s open source AI models have surpassed US models in download counts” (MIT Technology Review 2026-02-12, Internet Archive copy). Surpassed in total. That’s the point.
Here, “the 10 trillion yuan policy” and “the surge of DeepSeek V4 and Kimi usage” connect on the same line. Policy raises the banner of “AI Plus” and “AI permeation of the economy”; one floor below, the open source coalition shares technology back and forth; on the layer below that, indie developers use it for free. A three-story structure has started to spin.
A solo developer in Japan like me touches the third floor every day. Right now, the list of options for what model I call as the backend of my work tool definitively changed in April 2026.
Looking at China’s AI Ecosystem in “Three Layers” — Where Does a Japanese Indie Developer Enter?
Now to the design talk. The reason I stopped reading Chinese AI news in panic is that I started looking at the ecosystem in “three layers.”
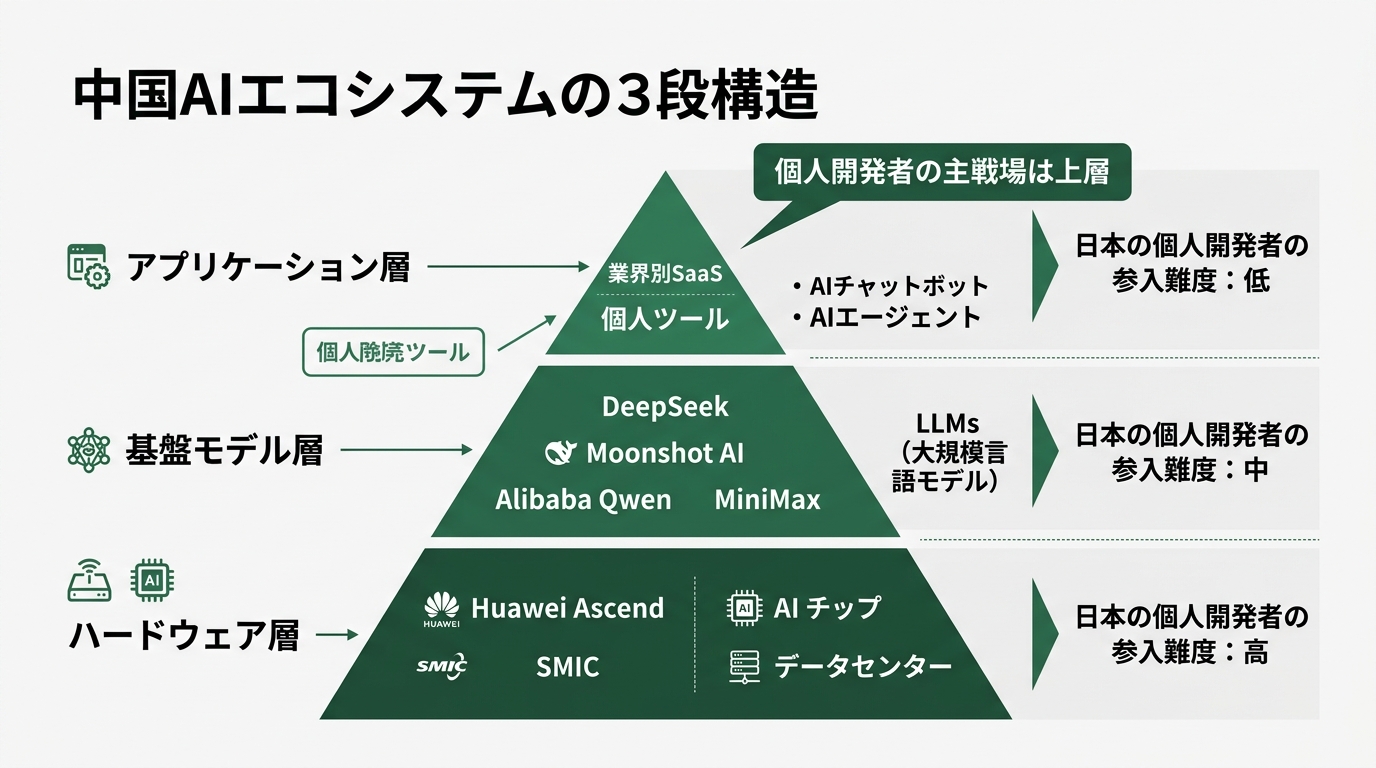
Layer 1 is the “hardware layer.” Huawei Ascend chips, SMIC manufacturing processes, data centers. The layer where Chinese government subsidies and national policy directly take effect. Zero room for a Japanese indie developer to enter. That’s a fact. Can an individual buy a Huawei chip? Generally, no — they’re for the Chinese domestic market. Unless you work in manufacturing, this is an irrelevant world.
Layer 2 is the “foundation model layer.” DeepSeek, Moonshot AI (Kimi), Alibaba Qwen, MiniMax, Knowledge Atlas, and others. Building a single model costs tens of billions of yen. It’s not realistic for an indie developer to “build their own model in this layer.” But “using” them is a different story. They’re open source, so you can download them and run them on your own server, or call them via API through OpenRouter. There’s also the option of just running validation on Hugging Face.
That’s two layers. Almost no entry room for an indie developer like me. The question is the third layer.
Layer 3 is the “application layer.” Because the Chinese domestic market is unusually large, Chinese companies dominate apps for that market. But the layer of “small tools that solve global business problems with AI” is still open without borders. Article structure generation with Moonshot AI, code generation with DeepSeek, translation with Qwen — business tools combining these can be built without any geographic advantage.
The business tools I usually build are the application layer, layer 3. Inquiry classification bots, contract draft generation scripts, Slack mention aggregation dashboards. Things that support CS and internal operations fall here. This is still a layer where “whoever builds first wins.”
And here, two pieces of news matter most for Japanese indie developers.
First. With layer 2 open source models entering the global top tier, costs at layer 3 drop. A month ago, I was paying about $40 per month for OpenAI API to run my own Slack Bot. Run the same thing through DeepSeek V4, and it likely drops to $5–10 per month (estimate, before measurement). That means “I can use the same tool ten times more often.”
Second. As Nagi’s article on April 19 reported, a Kimi K2.5-based model was adopted as the core of Cursor Composer 2. Chinese-made models have crossed the boundary of being “China-only.” They’re being plugged into the world’s developer tools as a matter of course, and the scenes where we use them without thinking are increasing.
The natural question: “Aren’t we being swallowed by China’s national strategy?” I felt the same way. The next section steps into that.
Three Reasons I Still Believe I “Won’t Get Swallowed by China’s AI Industry”
Let me be honest. “As a Japanese indie developer, is it okay to depend this heavily on Chinese AI?” is a question whose answer I’m still wavering on. So please read this not as a declaration but as “my current take.”
Reason 1. The application layer is a layer you win with “depth of business understanding.”
DeepSeek and Kimi train on “global general knowledge.” But the Slack Bot I build is fine-tuned on “my company’s inquiry classification.” The business tool I build is built by absorbing — through user interviews — “where the people in my department get stuck.” This “on-the-ground business understanding” doesn’t directly replace my skills, no matter how strong China’s open source models become.
I’m a former CS person. I’ve seen thousands of support tickets. The patterns of “this is where the user gives up” and “this is where replies stop coming” are baked into my body. This information doesn’t make it into papers or MIT Tech Review. It’s my local business knowledge. This becomes the indie developer’s biggest defensive wall in the application layer.
Reason 2. Open source models are a competition on the “being used” side.
The reason China is pushing open source as national policy is to seize “global de facto status” as a counter to the closed US models. The structure says “China benefits if DeepSeek and Kimi get used worldwide.” So we’re welcomed as the “using” side. If you understand the difference in strategy by layer, you don’t get tossed around emotionally.
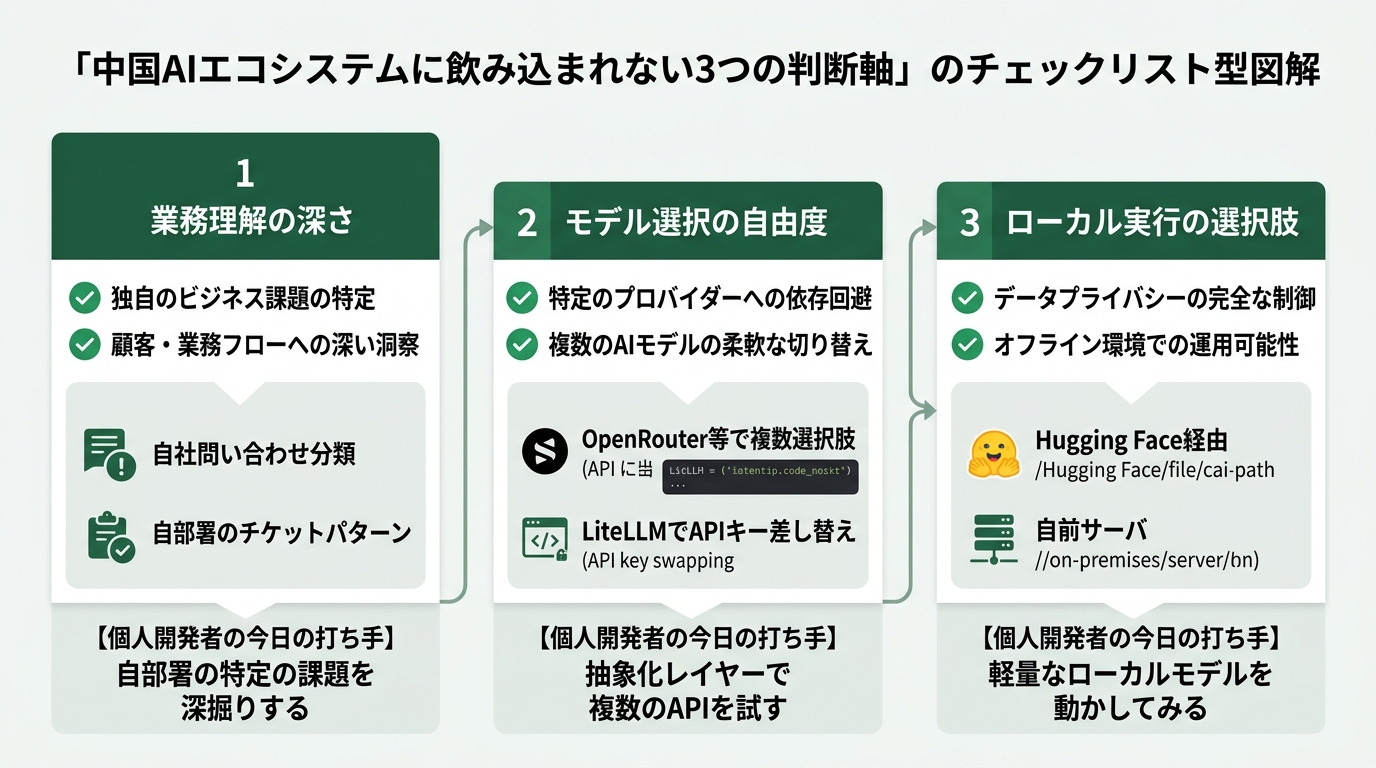
Reason 3. “Using multiple models in parallel” is becoming the indie developer standard.
OpenRouter’s very existence is proof. Don’t depend on a single model — call the optimal model for each task. Code generation with Claude, long-form summarization with Moonshot AI (Kimi), cheap text classification with DeepSeek, images with Google Imagen, and so on. This is the indie developer’s implementation of “diversifying Chinese AI dependency risk.”
I currently insert a routing library called “LiteLLM” into my business tools, in a configuration where I can switch models anytime. The risk that any given model is retired on Hugging Face, an API price hike, political usage restrictions — whichever happens, I can switch to a different model by rewriting one line in a config file. This is the “won’t get swallowed” design for an indie developer standing on the app layer.
That said, there’s one point to be careful about. When using Chinese-made open source models for business, the “data destination” needs to be checked. When you call through OpenRouter, where the input text gets sent depends on the routing destination. For tools that handle confidential or personal data, you need to choose either local execution (running on your own server) or a trusted hosting provider. This applies equally to Chinese and US-made models, but it’s worth designing with extra care.
Three Checks to Start Today, From a Former Failed Engineer
Let me drop everything above into the business tools you’ll touch today. Here are the three check items I actually changed starting this week.
Check 1. “Are my business tools model-locked?”
Six months ago, I was writing “OpenAI API” directly into my business tool code. From this moment, switching models would require rewriting code in 10 places. That’s lock-in.
The countermeasure is to insert a model abstraction layer like LiteLLM or Langchain. Just this lets you switch models by “swapping API keys and environment variables.” With Cursor Composer 2 or Claude Code Custom commands too, design with awareness of switchable configurations via config files. That’s the first step away from lock-in.
By the way, before I did this, I once spent 3 hours rewriting OpenAI code to the Claude SDK. “You’ll get burned here,” I’m telling you in advance.
Check 2. “Can I cost-estimate my tool by model?”
When I build a business tool, I calculate “how much per month to operate.” Tokens per request (input + output) × unit price. I’ve now built the habit of estimating this across four models. OpenAI GPT-4o, Claude Sonnet family, DeepSeek V4, and Moonshot AI (Kimi). I run the same workload through each and compare monthly cost.
DeepSeek V4’s unit price as of April 2026 is a fraction of US-made models (Fortune 2026-04-24). However, accuracy, response speed, and data destination — three points where US-made may differ. Not “just whatever’s cheapest” but “the cheapest that meets the quality required for my use case.” That’s the indie developer’s cost design skill.
Check 3. “Am I storing my business knowledge somewhere models can’t reach?”
This is the biggest one. No matter how China’s AI ecosystem evolves, the business knowledge I absorb in the field is an asset only I hold. “This is where users get stuck.” “This inquiry pattern increases at month-end.” “If you mention this person in the sales department, things grind to a halt.” Knowledge like this won’t load into any model.
Document this asset for feeding to AI. Past Slack logs, inquiry response scripts, user interview notes. I store these in Notion as a “business knowledge bank.” Every time a new model comes out, I re-feed this bank in and rebuild my own RAG (Retrieval-Augmented Generation). This is how an indie developer builds the “version of yourself that doesn’t get replaced by Chinese AI.”
This connects to what Nagi wrote last week, “Escaping the training-only syndrome and getting AI into your own work.” Don’t passively use models from outside — put your own business knowledge at the center, and treat models as interchangeable tools.
Conclusion — China’s Move Is Not a “Threat,” But a “Trigger to Rewrite the Map”
Wrapping up.
China’s 15th Five-Year Plan put forward two official figures: AI emerging industry cluster at 10 trillion yuan, and service industry at 100 trillion yuan. External analysis reads the direction as “covering 90% of the economy with AI,” and global AI’s tectonic shift is accelerating. The same week, DeepSeek V4 and Moonshot AI (Kimi) surfacing into OpenRouter’s top tier is a phenomenon that surfaced from that tectonic shift.
For Japanese indie developers, this isn’t a threat. It’s a trigger to rewrite the map. Don’t skim past it as “Chinese news, doesn’t apply to me” — read it as “the options in my dev stack have definitively changed.”
Let me write my three actions for today again. (1) Insert a model abstraction layer into your business tools (with LiteLLM or Langchain). (2) Build the habit of cost-estimating across four models (OpenAI, Claude, DeepSeek, Moonshot AI). (3) Store your business knowledge “where models can’t reach” (in Notion or internal docs).
This is the minimum design judgment for an indie developer like me to stand on the “won’t get swallowed by Chinese AI” side. It’s small compared to what professional AI companies do. But we’re the type of people who “can write code that makes our own work easier.” That small accumulation of code shaves three hours off the daily grind. That’s the indie developer’s winning lane, this former failed engineer believes.
Read China’s move one more time. 10 trillion yuan, 100 trillion yuan. Keep these two official figures in mind, and the Chinese AI news that comes out from next month onward will look like a “line” instead of “dots.” “Ah, this is movement toward that target in the Five-Year Plan.” Once you can read information on a map, you don’t get tossed around. That alone, I believe, makes reading this article this week worth it.

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。