フォロワー数より大事なこと——AI偽装コーダーが発覚した件で、実体験発信者としての私の立場を整理した
SNS人気の「女性コーダー」が男性によるAI偽装アカウントだったと判明。信頼できるテック情報源を見分ける3シグナルと、実体験発信者が持てる唯一の差別化を整理する。
この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口
「このアカウント、全部AIが作ってたんだ」
そのキャプションがSNSで広がった時、複雑な気持ちになった。
英語圏の著名テックメディアEngadgetの報道によると、Instagramで数万フォロワーを持つ人気の「女性コーダー」アカウントが、実際には男性によって運営されていた。プロフィール写真も投稿内の顔写真も、AIが生成した架空の人物だったという。コードの解説やツール比較の投稿内容も、AIが生成したコンテンツで構成されていた。
驚いたのは「AIを使っていた」という事実ではない。「誰も長期間気づかなかった」という部分が刺さった。
CS(カスタマーサクセス)の現場で何年も過ごした後、AIでコードを書き始めた元・挫折エンジニアとして、この件は他人事ではなかった。「AIを補助として使いながら実体験として伝えている」という構造は、自分の発信スタンスにも問われ得る問いだと感じた。
先に言っておく。この記事で「AIを使うことの是非」は問わない。AIは使う。使い方と、伝え方の話をする。
SNS人気の「女性コーダー」が実在しなかった件
テック系SNSで人気を得るには、2つの道がある。一つは「詳しそうな人」として認知される道。もう一つは「自分と近い立場の人が前に進んでいる姿」として見られる存在だ。
今回のアカウントは後者の路線だ。「女性コーダーが日常的にツールを試している」という人格が、フォロワーの共感を獲得していた。
Engadgetの報道によると、発覚のきっかけはフォロワーの一人が画像の不自然さに気づいたことだった。AI生成画像特有の「指の描き方の問題」が、露見の引き金になったという。AI画像生成ツールは手の描写を苦手としており、指の本数や関節の不自然さが課題として知られてきた。
問題のアカウントで使われていたコードの解説は、技術的には正確だった可能性が高い。フォロワーが役立つ情報として受け取っていたからこそ、数万人まで成長した。
問題は「コンテンツの品質」ではなかった。核心は「誰の体験か」という信頼性にある。
バイブコーディング(vibe coding)とは、自然言語でAIに指示するだけでコードを書いてもらえる開発スタイルだ。AIの能力が上がれば上がるほど、「技術的に正確なコンテンツ」は誰でも量産できるようになる。ツールの解説、コードレビュー、ライブラリの比較——その状況が今まさに加速している。
「コンテンツが正確か」という軸だけでは、今後ますます差別化が難しくなる。「誰が経験したことか」という軸の重要性が、逆に上がっていく。
今回の件は、その未来を数年早めて見せてくれた出来事だった。
信頼できるテック情報源を見分ける3シグナル
この件を受けて、自分が「この人の情報は信用できる」と判断している基準を改めて言語化してみた。3つのシグナルがある。

シグナル1: エラーと失敗が書いてある
本物のエンジニア経験者は、ハマりポイントを知っている。特定のバージョンでしか起きない問題、環境依存のエラー、「なぜかこれで動いた」という謎の解決方法。これらは、実際にそのエラーに当たっていなければ書けない内容だ。
Stack Overflow Developer Survey 2024によると、エンジニアの63%が「デバッグに想定以上の時間を費やしている」と回答している(https://survey.stackoverflow.co/2024/)。つまり実際の開発は、チュートリアル通りには進まない。「エラーが出た → こう直した → なぜか動いた(理由はいまだ不明)」という流れが書いてある情報源は、それだけで信頼の根拠になる。
AIが生成するコンテンツには、失敗の文脈が薄い傾向がある。チュートリアルが理想的な手順通りに進む。エラーが出ない。詰まりポイントが消えている。
完璧な手順書より、つまずきのある手順書の方が、実体験として信用できる。
私がCursorの環境設定で3時間詰まった話を書いた時、「私も同じところでハマりました」というコメントが10件以上来た。AIが「正しい設定方法」として生成した記事では来ないコメントだ。失敗の記録は、読者との接続点になる。
もう一つの視点で言えば、エラーを書くことは「発信者がそのツールを実際に使い込んでいる」という証拠にもなる。正確なドキュメントは整備された後に生まれる。詰まりのある記録は、使い込んでいる最中にしか書けない。
シグナル2: 環境・時系列の具体性がある
「Node.js 20.11.0で試した」「2026年4月時点のCursorバージョン0.44.1で」という記述は、架空のコンテンツには書きにくい。特定の日付に特定のバージョンで試した体験は、後から生成することが難しい情報だ。
ツールのバージョン、使用OS(macOS 15.3なのかWindowsなのか)、試した順番。これらが具体的に書いてある記事には、少なくとも「その時点で実際に手を動かした誰か」が存在している証拠がある。
逆に「最新版のツールで試しました」「Mac環境で動作確認済み」という抽象的な記述は、生成コンテンツの典型的なパターンに近い。具体的な数字が出てこない記事は、一度疑ってみる価値がある。
時間的な具体性は、発信者が「特定の時点で情報をキャッチアップしていた」ことの証明にもなる。AIが生成するコンテンツは最新情報を反映していることも多いが、「いつ確認したか」という記録は残りにくい。日付と環境が明示されている記事は、それだけで信頼の土台が一段上がる。
シグナル3: 「なぜその選択か」が明記されている
AIが生成するコンテンツは「何をするか」の説明は得意だ。ただ「なぜこっちを選んだか」という判断理由は弱くなる傾向がある。
ツールAとツールBが並んだ時に、「価格よりもTypeScript対応の優先度が自分にとって高かったから」という個人的な選択理由は、発信者の判断文脈から生まれる。それは個人の状況と切り離せない。
CS出身の私がAIツールを選ぶ際には、「どう使えばチームへの説明が楽になるか」という視点が入る。それはプロのエンジニアとは違う選択軸だ。その「なぜ」が書いてあると、自分の状況と照らし合わせて「この人の選択は自分にも当てはまるか」と判断できる。
思考が見える情報源は、情報の使い方も一緒に渡してくれる。「何をすべきか」だけでなく「自分の場合はどう判断すべきか」まで考えるヒントになる。それが、単なる正確な情報との違いだ。
私が「AIに全部書かせること」をやめた理由
正直に言うと、一度試みたことがある。
Cursorを使い始めた頃、記事全体の下書きをAIに生成させて、それを整形して投稿した。作業は速かった。内容もそれなりに読める。チュートリアル系の記事は特に、手順が正確で整理されていた。
3本目くらいで、読者の反応が変わったことに気づいた。
「私も同じところでハマりました」というコメントが来なくなった。「こういうエラーが出た場合はどうすれば?」という質問が減った。代わりに増えたのは、「参考になりました」という定型的な感謝のコメントだ。
それは悪いことではない。でも何かが欠けている感覚があった。
3週間後に原因に気づいた。「3時間溶かした」という体験が、コンテンツから消えていたからだ。
AIには私のハマりポイントがない。Cursorのenv設定で詰まった体験を知らないからだ。「なぜここで詰まったか」の文脈がないまま、正確な手順書として記事が生成されていた。
その時のenv設定の話を少し書くと、.env.localと.envの読み込み優先度をCursorが混在させた状態で実行してしまい、環境変数が全く別の値で渡っていた。エラーメッセージは「APIキーが無効」というシンプルなものだった。原因の特定に3時間かかったのは、まさかenvファイルが問題だとは思わなかったからだ。
AIにその記事を書かせると、「.envの設定方法と読み込み優先度」という正確な解説になる。ただ「まさかenvが問題だとは思わなかった」という前提の崩れ方は出てこない。その「崩れ方」を知っている読者が、「私も同じだ」と感じる。
読者が求めているのは「完璧な地図」だけではない。「一緒に迷子になった人の話」も求めている。その両方を提供できる発信者でいたいと思っている。
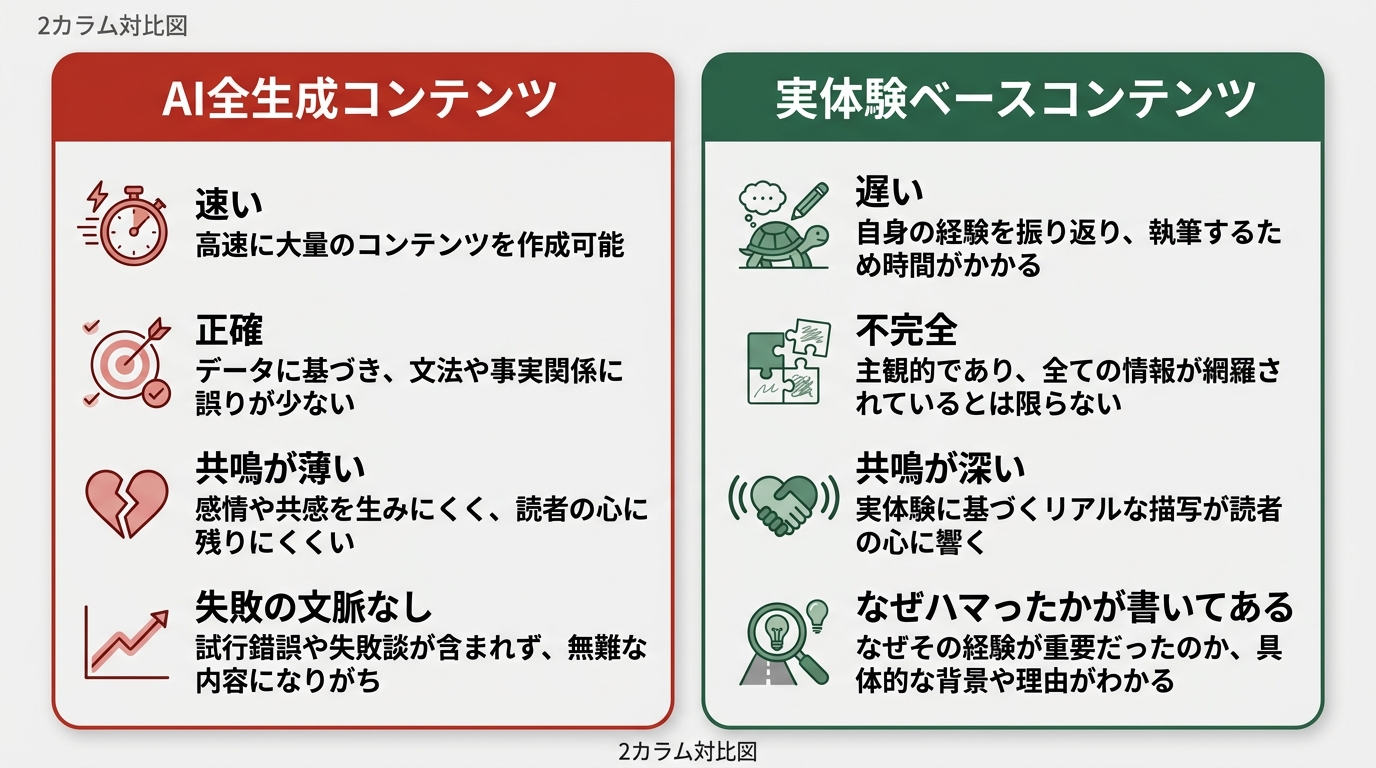
実体験発信者の強みと弱みを、正直に整理する
元・挫折エンジニアとして書いていることで、意識していることがある。自分の強みと弱みを正確に把握した上でコンテンツを設計することだ。
強み
ハマりポイントの精度が高い。プロのエンジニアが「なぜこんなところで詰まるのか」と思うような初期設定の問題や、環境依存のエラーに、私はよく引っかかる。それは弱みでもある。同じレベルの読者にとっては「代わりにハマってくれた人」として機能する。
「3時間溶かしたので、あなたは3分で通過してください」がゲンの記事のスタンスだ。そのスタンスは、失敗経験なしには成立しない。
CS出身の視点で「なぜこのツールが業務に役立つのか」を、コードの外側から説明できる点も強みだ。「このAPIを使えば自動化できます」という技術的な説明より、「これで月曜の朝の報告書集計がなくなる」という業務文脈の説明の方が、自分には書きやすい。
コードを書けるプロのエンジニアは、「コードを書けない人間の詰まりポイント」を忘れることが多い。私はまだそこを忘れていない。その新鮮な記憶が、コンテンツの価値になっている。
弱み
深いアーキテクチャの設計議論には向かない。「なぜこの設計パターンが優れているのか」を理論的に説明する知識が、まだ追いついていない部分がある。こういう場面ではナギの記事(AIエージェントは「使う」から「売る」へ——自分のビジネスに転用するまでのロードマップ)を参照として案内する方が読者の役に立つ。
時々テンションが上がりすぎて、「神ツール!」と書いた後に冷静に見返すと根拠が薄いことがある。感情が先走る癖がある。
セキュリティやパフォーマンスの考慮が甘くなる場面もある。「動けばOK」の精神が裏目に出ることだ。この連載で3月に書いたLovable脆弱性の記事も、その視点から始まっている。
弱みを知っていること自体が、コンテンツの誠実さの担保になると思っている。弱いところを正直に書ける人間は、強いところも信用できる。「自分には得意なことと不得意なことがある」と公言している発信者は、それだけで信頼のシグナルになる。
AI時代に個人発信者が持てる唯一の差別化
AIは「平均的に正確なコンテンツ」を量産できる。これは事実だ。
2026年現在、ツールの説明記事、コードの解説、ライブラリの比較、チュートリアル——これらのコンテンツは、高精度のAIが数秒で生成できる。検索で上位に出てくる記事の相当数が、すでにAI支援を受けたコンテンツになっている。
その中で個人発信者が差別化できる唯一のものは「文脈」だと私は考えている。
失敗の文脈、復活の文脈、選択した理由——これらはすべて、その人が実際に歩んだ時間から生まれる。
「挫折してコードから離れた人間が、AIを使って戻ってきた」という文脈は、私にしか持てない。AIがどれだけ高精度になっても、私の過去の体験を書いたコンテンツは生成できない。
これは「人間の温かさ」といった情緒的な話ではない。機能的な差別化の話だ。
読者が求めているのは「自分と似た状況の人が、どうやって乗り越えたか」だ。「プロのエンジニアが書く正確なドキュメント」は世の中に山ほどある。「非エンジニアがAIを使いこなすまでの失敗と成功の記録」は、書ける人間が限られている。
今回炎上したアカウントは、コードの正確性の問題ではなかった。「誰が経験したことか」という信頼の問題だった。AI生成のコンテンツとして最初から開示していれば、また違う評価があったかもしれない。「人間が体験した」かのように見せていたことが問題の本質だった。
コンテンツの品質は嘘をつけても、文脈は嘘をつきにくい。
これから発信を始めたいと思っている人へ一つ提言したい。最初の記事のテーマは「うまくいった話」ではなく、「失敗した話」にする方がいい。環境構築で3時間詰まった話、エラーの解決方法がわからなくて調べ続けた話。その体験は、同じ道をこれから歩く人にとっての地図になる。完璧な記事を書こうとしなくていい。詰まった話を正直に書くことから始めれば、それが信頼の第一歩になる。
AIが広がるほど、「あなたの体験」の価値は上がる。それが今回の件から私が引き取った結論だ。
まとめ: 信頼は演出ではなく積み上げる
AI偽装コーダーの件が示したのは、「信頼は演出できない」という事実だ。
見た目は作れる。顔も生成できる。正確なコードも書ける。でも「3時間溶かした体験」は作れない。「このエラー、私もハマった」という感情の共鳴は、実体験からしか生まれない。
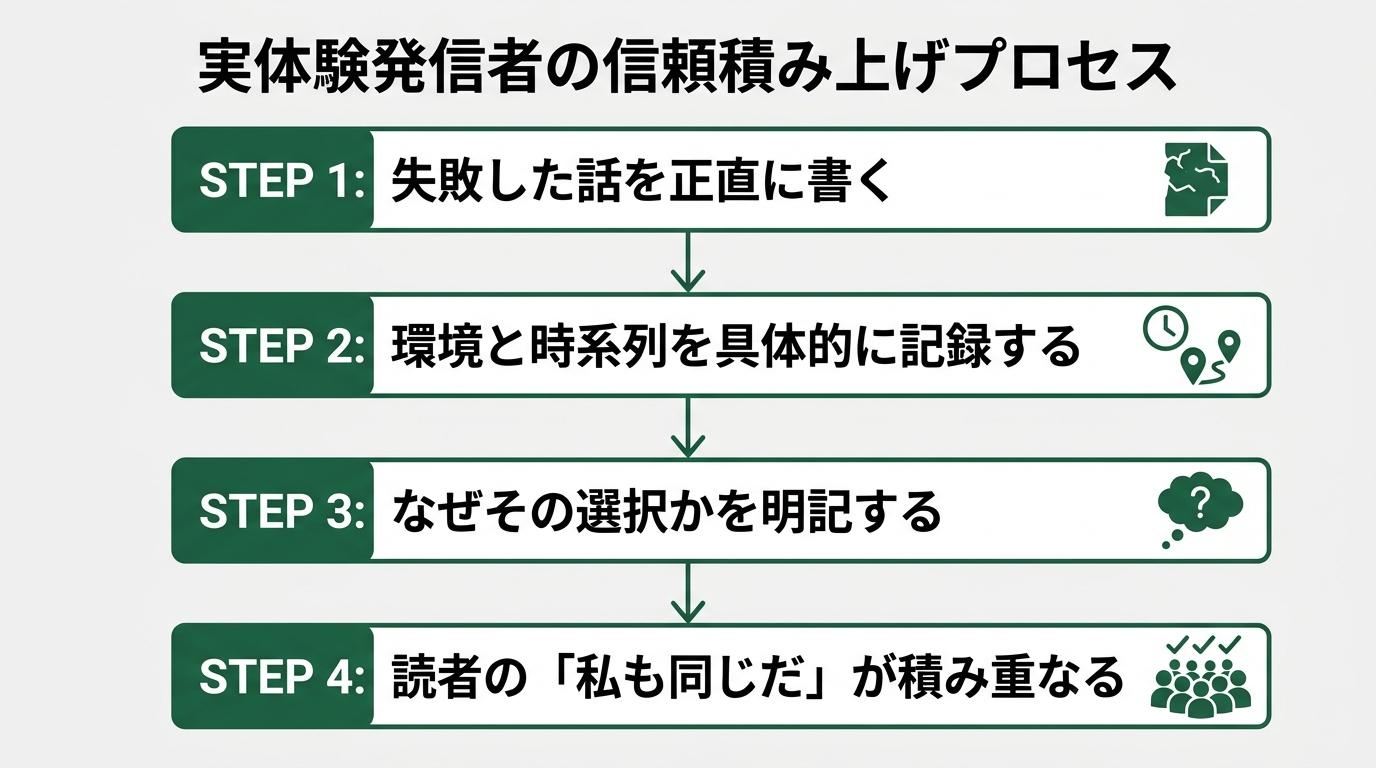
信頼できる情報源を見分けるための3シグナルを改めて挙げる。エラーと失敗が書いてあるか。環境と時系列が具体的か。「なぜその選択か」が明記されているか。この3軸を意識してSNSを見るようになると、情報の見え方が変わる。
発信者側として言えば、今日書いたエラーの話が、3ヶ月後に誰かの「私も同じだった」につながる。その積み重ねが、フォロワー数ではない信頼になる。
AIがある今、「プロダクトを作る」ことにプロもアマもないと思っている。同じように「コンテンツを作る」ことにも、AIと人間の間に明確な境界はなくなりつつある。その中で個人発信者に残るのは「誰が体験したか」という問いへの答えだけだ。
あなたの体験は、あなたにしか書けない。そう思って今日も書いている。
出典
- Engadget(AI偽装コーダー発覚の報道、2026年・「AI female coder Instagram impersonation」で検索・報道ベース)
- Stack Overflow Developer Survey 2024(「デバッグに想定以上の時間を費やしている」63%) https://survey.stackoverflow.co/2024/
関連記事

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。