What Matters More Than Follower Count—How an AI-Faked Coder Scandal Made Me Rethink My Position as a Real-Experience Creator
A popular 'female coder' on social media turned out to be an AI-faked account run by a man. Here are 3 signals for spotting trustworthy tech information sources, and the one differentiator real-experience creators can hold.
What you'll learn in this article
- The key point to grasp before reading the full article
- How the issue changes the way developers should work next
- Which follow-up article is worth opening next
“This whole account was made by AI.”
When that caption spread across social media, I felt something complicated.
According to a report by Engadget, a major English-language tech outlet, a popular “female coder” Instagram account with tens of thousands of followers was actually being run by a man. Both the profile photo and the face shots in posts were AI-generated fictional people. The code explanations and tool comparisons posted there were also AI-generated content.
What surprised me wasn’t the fact that “they were using AI.” What hit me was the part where “no one noticed for a long time.”
As a former failed engineer who spent years in CS (Customer Success) before starting to write code with AI, this story didn’t feel like someone else’s problem. The structure of “using AI as a helper while communicating from real experience” is something my own posting stance could be questioned on.
Let me say this upfront. This article is not about whether using AI is right or wrong. I use AI. This is about how to use it, and how to communicate it.
The Popular “Female Coder” on Social Media Who Didn’t Actually Exist
There are two paths to gaining popularity on tech social media. One is being recognized as “someone who knows their stuff.” The other is being seen as “someone in a similar position to me, moving forward.”
The account in question took the second path. The persona of “a female coder trying out tools day to day” earned empathy from her followers.
According to Engadget’s report, the trigger for exposure was a follower noticing something unnatural in the images. The “finger rendering problem” that’s characteristic of AI-generated images set off the unmasking. AI image generators have struggled with depicting hands, and the awkwardness of finger counts and joints has been a known issue.
The code explanations used in the problematic account were likely technically accurate. That’s exactly why the account grew to tens of thousands of followers—the followers were receiving it as useful information.
The problem wasn’t “content quality.” The core issue was the trustworthiness of “whose experience is this?”
Vibe coding is a development style where you instruct AI in natural language and have it write the code for you. The more capable AI gets, the more anyone can mass-produce “technically accurate content.” Tool walkthroughs, code reviews, library comparisons—that situation is accelerating right now.
On the axis of “is the content accurate,” differentiation is going to get harder and harder. The importance of the axis “whose experience is this” will go up in inverse proportion.
This incident showed us that future a few years early.
3 Signals for Spotting Trustworthy Tech Information Sources
Prompted by this incident, I tried to put into words the criteria I use to judge “this person’s information is trustworthy.” There are three signals.

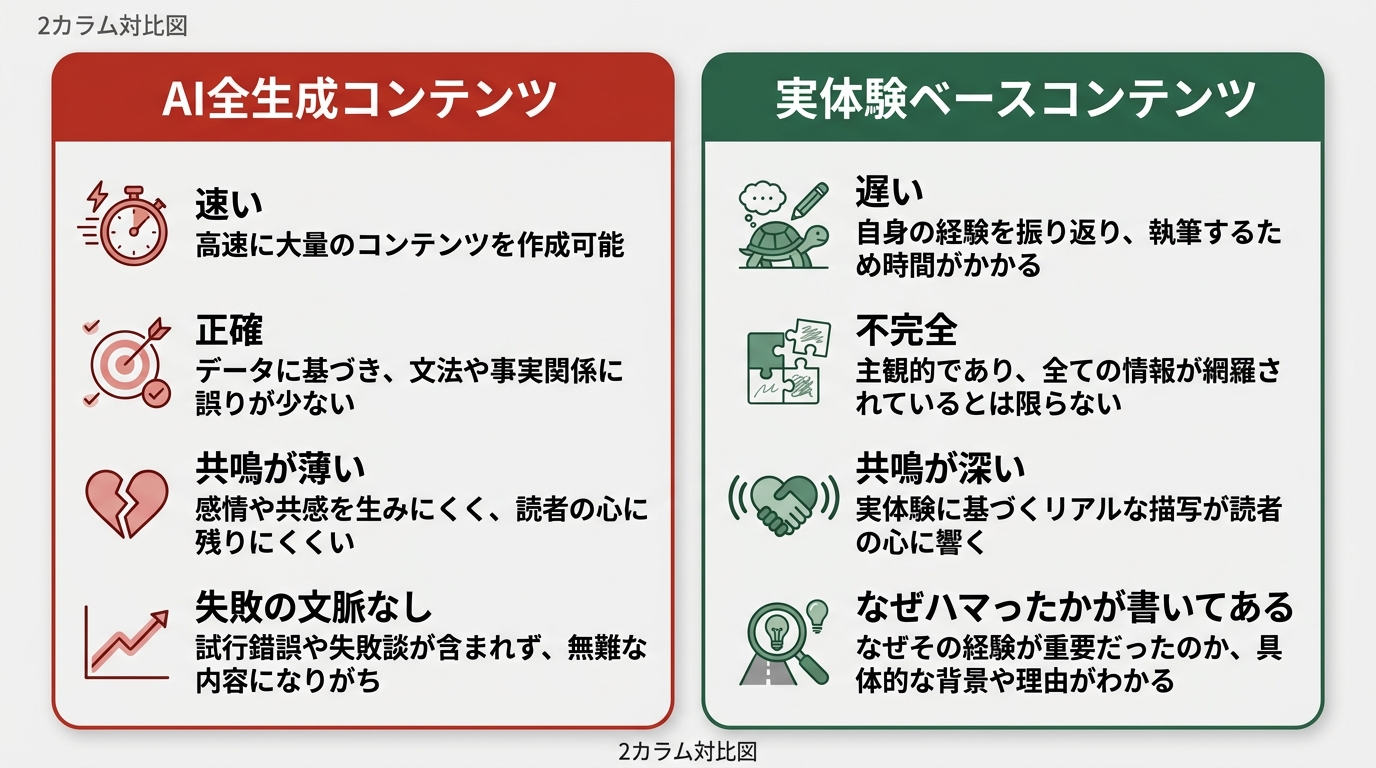
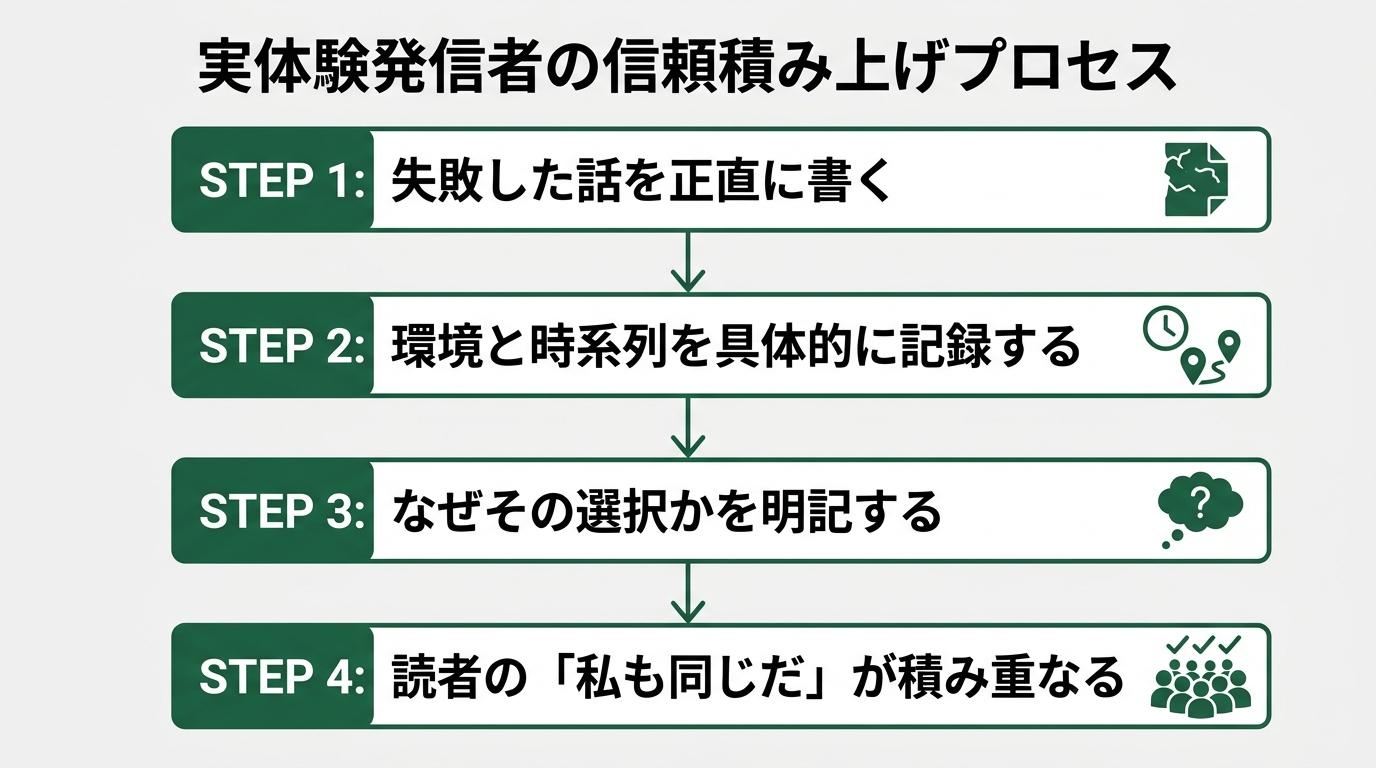
Signal 1: Errors and failures are documented
People with real engineer experience know the gotchas. Problems that only happen in specific versions, environment-dependent errors, mysterious fixes where “for some reason this made it work.” This is content you can’t write unless you’ve actually hit those errors.
According to the Stack Overflow Developer Survey 2024, 63% of engineers responded that they “spend more time debugging than expected” (https://survey.stackoverflow.co/2024/). In other words, real development doesn’t proceed the way tutorials suggest. Information sources with the flow “got an error → fixed it like this → for some reason it works (still don’t know why)” are, by themselves, grounds for trust.
AI-generated content tends to be thin on failure context. Tutorials proceed through ideal steps. No errors come up. The sticking points are gone.
A guide with stumbles is more credible as real experience than a flawless one.
When I wrote about getting stuck for 3 hours on Cursor’s environment setup, I got over 10 comments saying “I got stuck in the same place.” Those comments don’t come for an article that AI generated as “the correct setup method.” A record of failure becomes a connection point with readers.
From another angle, writing about errors is also evidence that “the creator has actually used this tool extensively.” Accurate documentation is born after things have been polished. A record with stumbles can only be written while you’re actively using something.
Signal 2: Environment and timeline specifics are present
Statements like “tested on Node.js 20.11.0” or “with Cursor version 0.44.1 as of April 2026” are hard to write into fictional content. The experience of trying something on a specific date with a specific version is information that’s hard to generate after the fact.
Tool versions, the OS used (whether macOS 15.3 or Windows), the order things were tried in. An article that writes these things concretely is, at minimum, evidence that “someone actually moved their hands at that point in time” exists.
Conversely, abstract statements like “I tried with the latest version of the tool” or “verified on a Mac environment” are close to typical patterns of generated content. An article without specific numbers is worth questioning at least once.
Temporal specificity also serves as proof that the creator was “catching up on information at a specific point in time.” AI-generated content often reflects the latest information, but the record of “when this was verified” tends not to remain. An article that explicitly states the date and environment gains a step in trust foundation just by that.
Signal 3: “Why this choice” is explicitly stated
AI-generated content is good at explaining “what to do.” But the reasoning behind “why I chose this one” tends to be weaker.
When Tool A and Tool B are placed side by side, a personal reason for selection like “the priority on TypeScript support was higher for me than price” is born from the creator’s judgment context. That’s inseparable from individual circumstances.
When I, with my CS background, choose AI tools, the perspective of “how can I use this in a way that makes explaining to the team easier?” comes in. That’s a different selection axis from a professional engineer’s. When that “why” is written, you can compare it against your own situation and judge “does this person’s choice apply to me too?”
An information source where the thinking is visible hands you the way to use the information along with it. It becomes a hint not just for “what to do” but also “how should I judge in my own case.” That’s the difference from merely accurate information.
Why I Stopped Letting AI Write Everything
Honestly, I tried it once.
When I started using Cursor, I had AI generate full drafts of articles, then formatted them and posted. The work was fast. The content read decently. Tutorial-style articles in particular had accurate, organized steps.
Around the third article, I noticed reader reactions had changed.
Comments saying “I got stuck in the same place” stopped coming. Questions like “what should I do when this kind of error comes up?” decreased. What increased instead were boilerplate appreciation comments saying “this was helpful.”
That’s not a bad thing. But there was a sense that something was missing.
Three weeks later, I figured out the cause. The experience of “spending 3 hours on this” had vanished from the content.
AI doesn’t have my gotchas. It doesn’t know the experience of getting stuck on Cursor’s env setup. The articles were being generated as accurate guides without the context of “why I got stuck here.”
Talking briefly about that env setup story, Cursor ended up running with .env.local and .env load priority mixed up, and environment variables were being passed with completely different values. The error message was a simple “API key invalid.” It took 3 hours to identify the cause because I never imagined the env file was the problem.
If I have AI write an article about that, it becomes an accurate explanation of “how to set up .env and its load priority.” But the way the assumption breaks down—“I never imagined env was the problem”—doesn’t come out. Readers who know that “way of breaking down” are the ones who feel “I’m in the same spot.”
What readers are looking for isn’t just “a perfect map.” They’re also looking for “the story of someone who got lost together with them.” I want to be a creator who can offer both.
Honestly Sorting Out the Strengths and Weaknesses of a Real-Experience Creator
As I write as a former failed engineer, there’s something I’m conscious of. Designing content with an accurate grasp of my own strengths and weaknesses.
Strengths
The precision of my gotchas is high. Initial setup problems and environment-dependent errors that professional engineers would think “why are you stuck on something like that?”—I get caught on those a lot. That’s also a weakness. For readers at a similar level, I function as “the person who got stuck on your behalf.”
“I burned 3 hours on it, so you can pass through in 3 minutes” is the stance of Gen’s articles. That stance can’t be established without failure experience.
Being able to explain “why this tool helps with work” from outside the code, with my CS background, is another strength. Rather than the technical explanation “you can automate with this API,” I find it easier to write the work-context explanation “this gets rid of Monday morning report tabulations.”
Professional engineers who can write code often forget “the gotchas of people who can’t write code.” I haven’t forgotten them yet. That fresh memory becomes the value of my content.
Weaknesses
I’m not suited for deep architecture design discussions. The knowledge to theoretically explain “why this design pattern is superior” hasn’t quite caught up yet. In situations like that, it’s more useful to readers if I point them to Nagi’s article (AI Agents: From “Using” to “Selling”—A Roadmap to Repurposing for Your Own Business).
Sometimes my excitement runs too high, and after writing “amazing tool!” I look back calmly and find the basis is thin. I have a habit of letting emotion run ahead.
There are scenes where security and performance considerations get loose. The “if it works, OK” spirit backfiring. The Lovable vulnerability article I wrote in this series in March also started from that perspective.
Knowing my weaknesses is itself, I think, a guarantee of content sincerity. A person who can honestly write about their weak spots can also be trusted on their strong spots. A creator who openly states “I have things I’m good at and things I’m not” becomes a trust signal just by that.
The One Differentiator Individual Creators Can Hold in the AI Era
AI can mass-produce “averagely accurate content.” That’s a fact.
As of 2026, articles explaining tools, code walkthroughs, library comparisons, tutorials—these contents can be generated by high-precision AI in seconds. A considerable share of articles ranking high in search results is already AI-assisted content.
Within that, the only thing individual creators can differentiate on, in my view, is “context.”
Context of failure, context of recovery, the reasons for choices—all of these are born from the time the person actually walked.
The context “a person who got discouraged and left coding came back using AI” is something only I can hold. No matter how high-precision AI gets, content written about my past experience cannot be generated.
This isn’t an emotional argument about “human warmth.” It’s a story about functional differentiation.
What readers are looking for is “how someone in a situation similar to mine got over it.” There are mountains of “accurate documentation written by professional engineers” in the world. “Records of failures and successes by a non-engineer mastering AI” are something only a limited number of people can write.
The account that flared up this time wasn’t an issue of code accuracy. It was an issue of trust around “whose experience is this?” If they had disclosed from the start that it was AI-generated content, the evaluation might have been different. What was being shown as if “a human had experienced it” was the essence of the problem.
Content quality can be faked, but context is hard to fake.
I’d like to make one suggestion to people thinking about starting to post. The theme of your first article should be, instead of “a story that went well,” “a story of failure.” A story of getting stuck for 3 hours on environment setup. A story of not knowing how to solve an error and continuing to look it up. That experience becomes a map for people about to walk the same road. You don’t have to try to write a perfect article. If you start by honestly writing about getting stuck, that becomes the first step of trust.
The more AI spreads, the more the value of “your experience” rises. That’s the conclusion I took away from this incident.
Summary: Trust Isn’t Performed, It’s Accumulated
What the AI-faked coder incident showed us is the fact that “trust cannot be performed.”
You can manufacture appearance. You can generate a face. You can write accurate code. But you can’t manufacture “the experience of burning 3 hours.” The emotional resonance of “I got stuck on this error too” is born only from real experience.
Let me restate the 3 signals for spotting trustworthy information sources. Are errors and failures documented? Are environment and timeline concrete? Is “why this choice” explicitly stated? Once you start watching social media with these three axes in mind, the way information looks changes.
From the creator side, the error story I wrote today connects to someone’s “I was the same” three months later. That accumulation becomes trust that isn’t follower count.
With AI here now, I think there’s no pro and amateur in “making products.” Similarly, in “making content,” the clear boundary between AI and humans is fading. Within that, what remains for individual creators is only the answer to the question “whose experience is this?”
Your experience can only be written by you. That’s the thought I keep writing with today, too.
Sources
- Engadget (Reporting on AI-faked coder exposure, 2026, based on coverage searchable via “AI female coder Instagram impersonation”)
- Stack Overflow Developer Survey 2024 (63% “spending more time debugging than expected”) https://survey.stackoverflow.co/2024/
Related Articles

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。