Cursor CEOが、自社製品に「砂上の楼閣」と書いた——商売道具を作る側が警告した日と、業界が出した5つの答え
Cursor CEO Michael Truellが2025年12月、自社の利用シーンを「shaky foundations(砂上の楼閣)」と評した。半年で業界はどう動いたか。Palo Alto SHIELDとGeorgia Tech CVE調査で、答え合わせをする。
この記事でわかること
- 本文に入る前に、まず押さえるべき結論
- 開発や実装の判断が、ここからどう変わるか
- 次に読むべき関連記事の入口
商売道具にケチをつけるCEOを、私は他に思いつかない。
Cursor CEOのMichael Truellが、バイブコーディングを「shaky foundations(砂上の楼閣)」と評した。自社製品の主要な使われ方として広がっている、その当のシーンに対しての言葉だ。発言の場はFortune Brainstorm AI 2025(2025年12月)。Fortuneが12月25日に「Cursor CEO warns vibe coding builds ‘shaky foundations’」として報じた。
何が砂上の楼閣なのか。Truellの言葉を訳すとこうなる。「目を閉じてコードを見ずに、AIに砂上の楼閣を建てさせる。階を1つ重ね、もう1つ、また1つ。やがて崩れる」。家を建てる比喩も使った。「壁を4枚と屋根を立てて、床下や配線がどうなっているか知らない状態」。Cursorはその家のクレーン側にいる会社だ。
CSの仕事を10年やってきて、自社製品の弱点をパブリックの場で、しかも修飾なしで言うCEOは滅多に見ない。普通は「今後の改善ポイント」「責任ある利用」みたいな言葉で柔らかく包む。Truellは包まなかった。
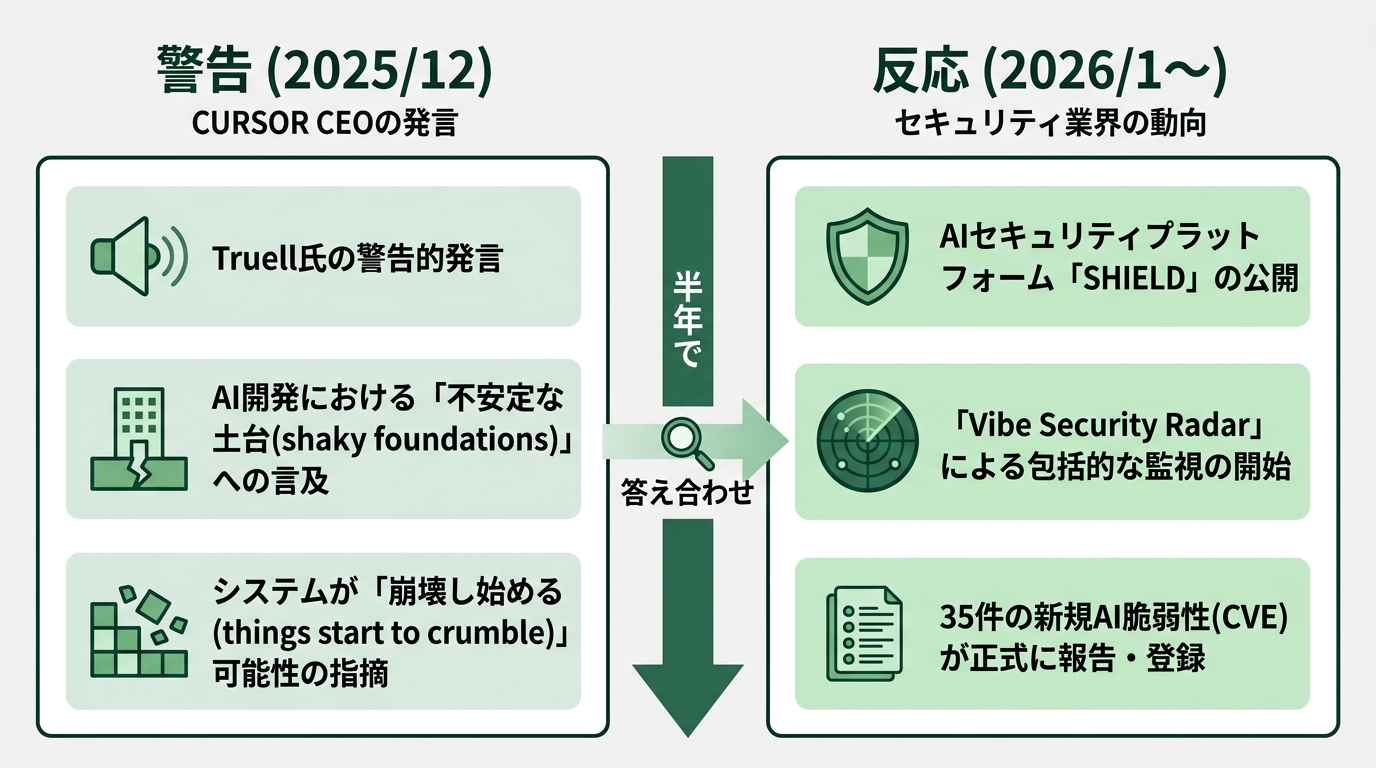
そしてそれから5ヶ月。業界に変化が出てきた。Palo Alto Networksから「SHIELD」という5文字のフレームワークが登場し、Georgia Techの研究者は「Vibe Security Radar」を立ち上げてAI生成コード由来のCVE件数を月次で追っている。1月6件、2月15件、3月35件。きれいな指数曲線になっている。
Truellの警告は、誇張ではなかった。半年で答え合わせが進んでいた。今日の記事は、その答え合わせを5つの実装ルールに翻訳する話だ。
商売道具を作る側が警告した、という事実の重さ
Truellの発言を、初めて読んだ時に違和感を覚えた。
普通、製品を売るCEOは「正しい使い方をすれば最高です」と言う。「ただし注意が必要」みたいな文脈は、たいてい記事の後半に小さく入る。Truellは違った。Cursor自身が利用シーンとして加速させているバイブコーディングを、本人が冒頭から「砂上の楼閣」と呼んだ。
なぜ、こう言わなければならなかったのか。理由は明白だ。バイブコーディングの利用拡大に伴い、事故が見えるところで起きていた。
私が三部作として書いてきた事案を振り返る。第1弾は2026年3月31日のLovable脆弱性報告。Lovableで生成されたアプリの10.3%にセキュリティ欠陥が確認された(過去記事はこちら)。第2弾は2026年5月5日のCursor本番DB削除事件。CursorとClaude Opusで作業していた企業エンジニアが、AIの提案コマンドの影響範囲を把握しないまま本番データベースを削除した(過去記事はこちら)。
事故が起きるたびに、開発者コミュニティから出た反応は2種類に分かれる。「ユーザー側の責任」と「ツール側の責任」だ。Truellの発言は、その分岐に対する答えだったように読める。「ツール側として警告は出している。あとは設計と運用の話だ」。
CS出身として痛感している論点がある。プロダクトを売る側が「お客様が気をつければいい」と言い続ける限り、問題の根本は解消しない。Truellはその構造を分かっている。だから自社製品の使われ方に向けて言葉を投げた。
ここで一段、見方を整理しておく。Truellは「Cursorを使うな」と言ったのではない。「目を閉じてコードを見ない使い方を続けるな」と言った。Cursorのプロダクト思想は「AIを編集環境に深く組み込み、コードベース全体の文脈で次の1行を予測する」ところにある。コードを見る人間と、AIの提案を統合する場所として設計されている。
つまり、警告の射程は「目を閉じる行為」であって「AIの利用」ではない。ここを混同すると、せっかくのCEO発言が「AI批判」として消費されてしまう。私は、そう読みたくない。
数字が裏付けた——CVEは6→15→35件の指数曲線
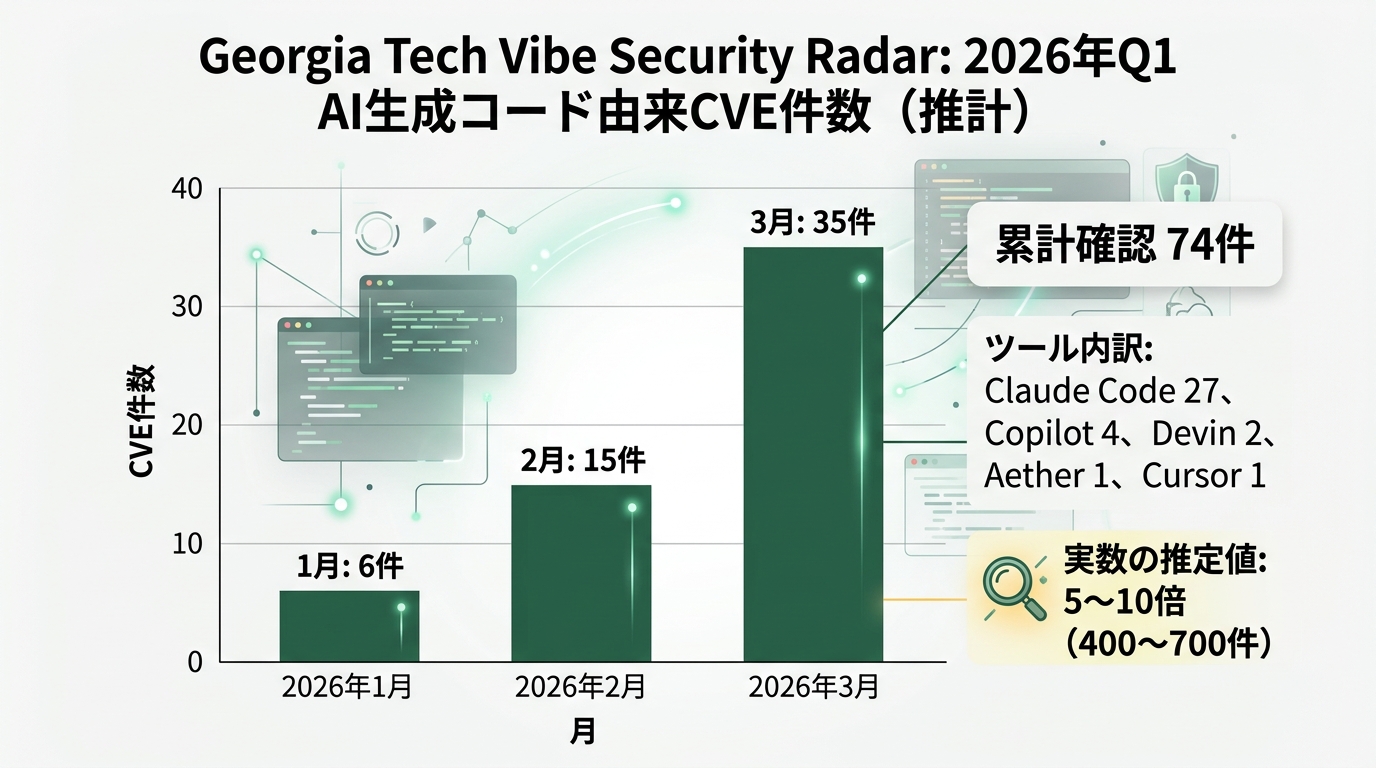
Truell発言の半年後、数字が出てきた。
Georgia Tech(ジョージア工科大学)のSystems Software & Security Lab(システムソフトウェア・セキュリティ研究室。略称SSLab)は2025年5月、「Vibe Security Radar」というプロジェクトを立ち上げている。AI生成コードに起因するCVE(Common Vulnerabilities and Exposures。共通脆弱性識別子。世界中のセキュリティ脆弱性に一意のIDを振って公開する仕組み)を月次で集計する取り組みだ。
この調査が示した数値は、こうなる。
- 2026年1月: 6件
- 2026年2月: 15件
- 2026年3月: 35件
3ヶ月で約6倍。Truellが警告した直後の四半期で、報告件数は指数的に増えた。
調査手法も興味深い。研究者たちは公開脆弱性データベースから対象案件を集め、修正コミットを特定し、そこから「最初にバグを混入させたコミット」を逆引きする。コミットにAIツールの署名(co-author tagやbotメールアドレス)が含まれていれば、AI生成コードに起因するCVEとしてフラグを立てる仕組みだ。
74件の確定済み事案を、ツール別に整理した。Claude Code 27件・GitHub Copilot 4件・Devin 2件。Aether 1件・Cursor 1件と続く。研究者の推定値はさらに大きい。「実数は5〜10倍。400〜700件のAI由来脆弱性が、まだ帰属未確定でOSSに残っている」。Infosecurity Magazine(2026年4月公開)が、この推定値を取材で引き出している。
ここで、私は身構えた。「Claude Code 27件」を見て、「やっぱりClaude Codeがダメか」と読みたくなる。違う。これは「使われている量に比例した結果」と読むのが正しい。
CSの現場で同じ構造を何度も見てきた。利用者が多い製品は、不具合報告も多い。利用者が少ない製品では、そもそも報告が上がらない。母数を補正せずに件数だけ並べると、誤った結論に着地する。Vibe Security Radarのデータも同じだ。「どのツールに課題があるか」より「AI生成コード全体としてどれだけCVEが増えているか」を見るべきグラフになっている。
増えている、という事実は揺らがない。Truellの「shaky foundations」発言は、この曲線を予言していた格好だ。
業界が出した5つの答え——Palo Alto Networks「SHIELD」フレームワーク
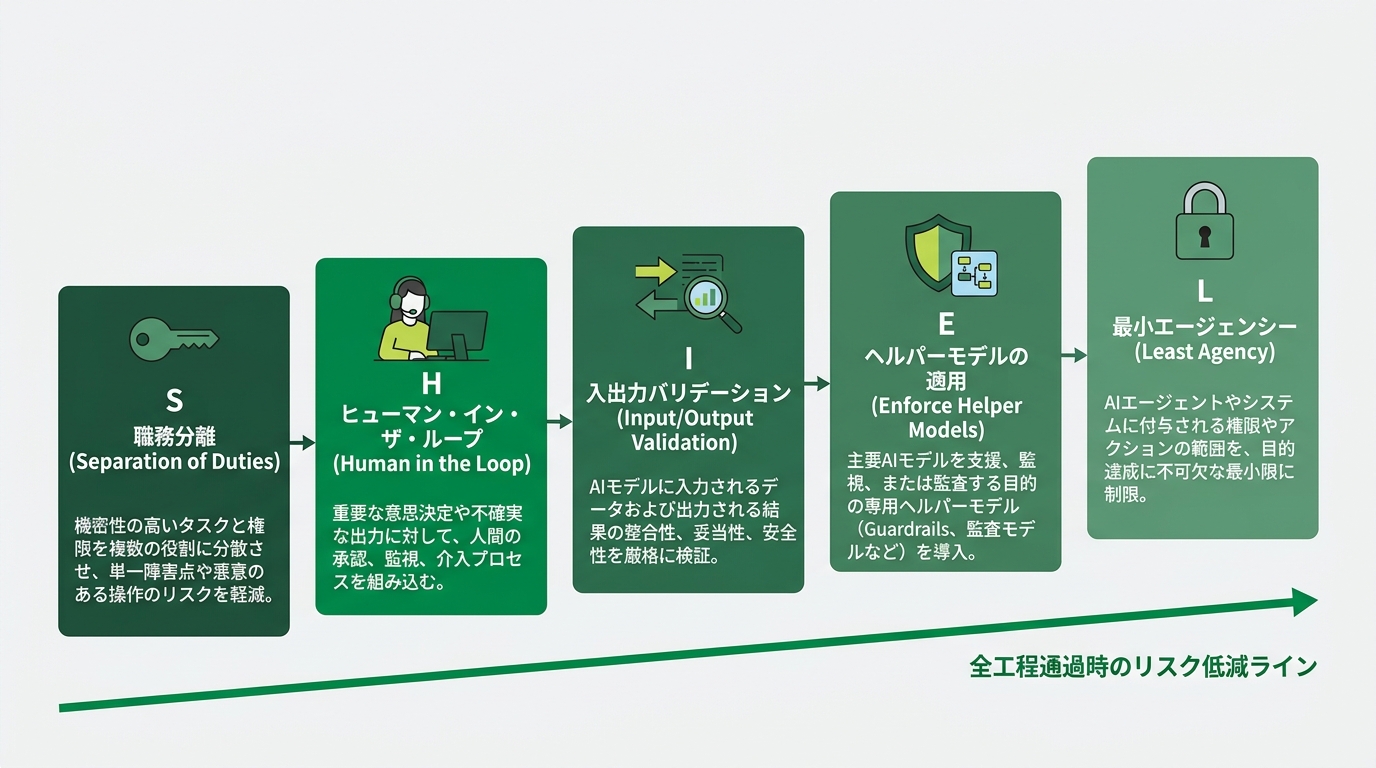
警告に対する業界の答えは、5文字で出てきた。
Palo Alto Networksの脅威研究部門Unit 42が、フレームワーク「SHIELD」を2026年1月に公開している。これがその答えだ。Infosecurity Magazineの「Palo Alto Networks Introduces New Vibe Coding Security Framework」で全容が紹介されている。Security Boulevard(2026年1月)にも詳報がある。
SHIELDの5要素を、ひとつずつ整理していく。
S: Separation of Duties(職務分掌)
AIエージェントは開発・テスト環境のみで動かす。本番環境(プロダクション。実際にユーザーが使う運用環境)への直接アクセスは禁止だ。バイブコーディングプラットフォームに組み込まれているAIエージェントが、本番DBやデプロイ権限に直接届かない設計が必要になる。Cursor本番DB削除事件は、この原則が運用されていない環境で起きた。
H: Human in the Loop(人間の関与必須)
クリティカルな機能に影響するコードでは、人間によるセキュアコードレビューを義務化する。コードマージ前のPR(プルリクエスト。コードを本流に取り込む前の確認手続き)承認は必須だ。「動いた」だけで本流に流す運用は禁止される。
I: Input/Output Validation(入出力検証)
プロンプトに「信頼された指示」と「信頼されないデータ」を混ぜない。ガードレール(守るべき境界線を強制する仕組み)が分離の役割を担う。AI自身にロジックチェックを実行させる。SASTツール(コードを動かさず脆弱性を見つける静的解析ツール。Static Application Security Testingの略)での検証もかける。
E: Enforce Security-Focused Helper Models(セキュリティ特化の補助モデル強制)
外部の独立したヘルパーモデルでSAST検証・シークレットスキャン(パスワードやAPIキーがコードに混入していないかの検査)・セキュリティ統制の確認を行う。脆弱性とハードコードされた秘密情報を、デプロイ前に検出する。
L: Least Agency(最小権限)
すべてのバイブコーディングプラットフォームとAIエージェントに対して、最小権限の原則を適用する。役割を果たすために必要な権限と能力だけが渡される。それ以外は閉じる。
5要素を見渡すと、Truellの「目を閉じるな」という警告が具体的な実装ガイドラインに翻訳されている構造が見える。Sは本番事故への備え。Hは「目を開けてレビューする」役割を人間に固定する。IとEは「目」自体を別のAIに肩代わりさせる仕組み。Lは万一の被害範囲を最小化する設計だ。
CEO発言から1ヶ月で、この具体度のフレームワークが出てきた。正直、感心している。「業界の答えは出ている」と書いた前回の記事(CodeGuard三部作・5/9)の延長線上に、SHIELDが綺麗に乗っかる。Cisco CodeGuardはツール側、SHIELDはガバナンス側。両輪で立ち上がっている。
三部作の答え合わせ——揃った道具と揃っていない運用

ここで一度、立ち止まる。三部作(Lovable脆弱性・Cursor本番DB削除・CodeGuard三部作)と本記事を通して、何が揃って、何が揃っていないか。
揃ったもの。
ツール側ではCisco CodeGuardが2025年10月にOSS公開され、2026年2月にCoSAI(Coalition for Secure AI。AI安全性のための業界連合体)に寄贈されている。AI生成コードの静的解析エンジンがオープンに利用できる状態になった。
ガバナンス側ではPalo Alto NetworksのSHIELDが2026年1月に登場した。職務分掌・人間レビュー必須・入出力検証・補助モデル強制・最小権限。実装ルールが文書化された。
データ側ではGeorgia TechのVibe Security Radarが月次でCVE件数を出し始めた。「肌感覚」だった問題が「定量化された曲線」になっている。
道具・ルール・データ。3つが揃った。これでバイブコーディング時代のセキュリティは「設計の話」になる。「気をつけよう」のキャンペーンではなくなる。
揃っていないもの。
採用率だ。CodeGuardが2025年10月に出たことを、私は2026年5月まで知らなかった。これは私の失敗だ。
警告だけならまだいい。ツールは出ている。ルールも文書化された。データも追跡が動いている。それでも事故が止まらない理由は、現場での採用が遅いからだ。
私自身のプロジェクトで、Lに該当する権限設計を見直したのが、つい最近だ。SとHは元々運用していたが、IとEはまだ自動化していない。「やった方がいい」と「やっている」の間に、まだ距離がある。
CSの仕事で同じパターンを何度も見てきた。良いツールが出ても、ユーザーの行動が変わるまでには時間がかかる。今回の差は、事故が見えるところで起きていることだ。Lovable脆弱性とCursor事件は、採用を急がせる役割を果たしている。皮肉だが、火事がスプリンクラー設置を加速させる構造になる。
個人開発者向け5アクション——SHIELDを今日できる粒度に翻訳する

SHIELDを企業向けに書かれたまま読むと、個人開発者には遠い話に見えてしまう。私自身、最初に読んだ時はそう感じた。だから5アクションに翻訳した。1週間で全部やれる粒度にしてある。
アクション①: 「.gitignoreに.envを書く」(5分・SとEの補完)
最も低コストで最大効果のアクションがこれだ。プロジェクトのルートに.gitignoreファイルを開いて、.envの行があるか確認する。なければ今すぐ追加だ。.envにはAPIキー・データベースのパスワード・認証トークンを入れて、コードからはprocess.env.XXXの形で参照する。
これだけで、シークレット情報の流出リスクは大半が消える。GitHubに誤ってプッシュした瞬間に世界中に公開されるパターンが、最も怖い。SHIELDのSとEを、個人レベルで先取りする位置づけだ。
# .gitignore に追記する1行
.envアクション②: 「PR前にAIに自己レビューさせる」(10分・Hの実装)
GitHubのPRを作る前に、AIに自分のコードをレビューさせる。プロンプトはシンプルでいい。
このコードのセキュリティ上の懸念を3つ挙げて。
SQLインジェクション・認証回避・機密情報のハードコードに重点を置いて。AIは自分が書いたコードのレビューが意外と冷静だ。「ここは入力検証が漏れている」「この権限は広すぎる」と教えてくれる。完璧ではないが、人間レビューの前段で30%の問題を潰せる。
SHIELDのHは「人間レビュー必須」だ。AIレビューはその代替ではないが、補助として機能する。1人開発で「人間レビュアーがいない」場合、AIが暫定の役を担えるのだ。
アクション③: 「危険コマンドはステージングで先に試す」(30分・Iの運用)
データベース操作・ファイル削除・権限変更——影響が大きいコマンドは、本番に直接打たない。ステージング環境(本番の複製として用意するテスト用環境)で先に動かす。
ステージングがない場合は、本番のスナップショットを別環境で再現する手順を1度作っておく。1度作れば、次からは「本番で試す」誘惑が減る。Cursor本番DB削除事件の最大の教訓は「本番で初めて試した」ところにあった。
AIへのプロンプトに、こう書き足す。
このコマンドを実行する前に、影響範囲とロールバック手順を先に教えて。
ステージング環境で先に試したい。アクション④: 「秘密情報スキャンを別AIに依頼」(15分・Eの実装)
コードを書いたAIと、レビューするAIを分ける。例えばClaude Codeで書いたコードを、別のClaudeセッションにコピペしてほしい。あるいはChatGPT・Geminiでも構わない。「このコードに秘密情報がハードコードされていないかチェックして」と聞く。
AIの「自己採点」は時々甘い。別モデルでクロスチェックすると、見落としが減る。SHIELDのEは「外部・独立した補助モデル」を要件にしている。個人レベルで近似する方法として、別セッション・別ベンダーのモデルを使うのが現実的だ。
アクション⑤: 「権限スコープを最小に絞る」(20分・Lの補強)
APIキーを発行する時、権限スコープを「全権限」ではなく「必要最小限」に絞る。読み取りだけで済む処理に書き込み権限を付与しない。データベースのユーザーロールも、SELECTだけで済むなら他は剥奪する。
AIに権限設計を聞く時、こう聞く。
このコードが動作するために必要な最低限の権限を、APIスコープ・DB権限・ファイル権限の3軸でリストアップして。
それぞれ「なぜ必要か」も説明して。「なぜ必要か」を説明させると、AIが冗長な権限を付けがちな癖が見えてくる。説明が弱い権限は、削っていい。
5アクションの優先順位はこう設計した。
- 今週末まで: アクション①(
.gitignore確認)。コスト5分、効果最大。 - 来週中: アクション②(PR前AIレビュー)とアクション⑤(権限スコープ最小化)。
- 今月中: アクション③(ステージング経由)とアクション④(別AIスキャン)。
3ヶ月後にはCVE件数が再度増えているはずだ。35件→次の節目をどう迎えるかは、今週の手当て次第になる。
まとめ——警告は読まれていない
Truellが2025年12月に発した警告を、私は2026年5月まで掘り下げて読んでいなかった。これは私の失敗だ。
警告だけならまだいい。ツールは出ている。ルールも文書化された。データも追跡が動いている。それでも事故が止まらない理由は、現場での採用が遅いからだ。
「業界の答えは既にある。問題は採用されていないこと」——前回の記事で書いたこの構造は、本記事でさらに鮮明になった。Cisco CodeGuard・Palo Alto SHIELD・Georgia Tech Vibe Security Radar。3つが揃って初めて、バイブコーディングは「気をつける問題」から「設計する問題」に格上げできる。
今日できることは、.gitignoreの確認から始まる。5分で終わる作業だ。アクション①だけでも、SとEの大半は補完できる。
CSの現場で何度もこのパターンを見てきた。効果が高いアクションほど、先延ばしにされる。今日5分の作業を、明日の事故と引き換えにしてはいけない。
かつてプロのエンジニアには敵わないと思った。AIを通じて、その技術が手の届く場所に来た。同じ構造で、凄腕セキュリティエンジニアが設計した5文字のフレームワークが、SHIELDという形で誰でも読める場所にある。読まないのは、もったいない。
CEOが警告した日から半年。次の半年で、私の手元のプロジェクトには5アクション全てを実装する。1つずつ進めていく。
出典・参照
- Cursor CEO Michael Truell発言: Fortune「Cursor CEO warns vibe coding builds ‘shaky foundations’」(2025年12月25日)
- Palo Alto Networks SHIELD: Infosecurity Magazine「Palo Alto Networks Introduces New Vibe Coding Security Framework」(2026年1月)
- Georgia Tech Vibe Security Radar: Infosecurity Magazine「How Security Leaders Can Safeguard Against Vibe Coding Security Risks」(2026年4月)
- Cisco Project CodeGuard: Cisco公式ブログ(2025年10月16日)
- バイブコーディング三部作 第1弾(Lovable脆弱性): 過去記事はこちら
- バイブコーディング三部作 第2弾(Cursor本番DB削除): 過去記事はこちら
- バイブコーディング三部作 第3弾(CodeGuard): 過去記事はこちら

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。