Cursor、Claude Code、Codex、Replit、Devin。Tenzaiが5大バイブコーダーを本気で比べたら、優勝は「テストする側」だった
Tenzaiが2025年12月に5大コーディングエージェントを比較した。15アプリで69件の脆弱性、SSRFは5/5、CSRFは0/15。ツール選びの次の論点を、元・挫折エンジニアが整理した
この記事でわかること
- Claude Codeの料金や導入論点が、いまどこまで整理されているか
- 自分の立場なら、どのプランや導入段階を見ればいいか
- 次に読むべき関連記事が、料金・使い方・全体像のどこにあるか

前日(2026-05-11)の記事Cursor Composer 2の経済構造分解編では、Cursor自身の警告と新機能投入の矛盾を経済から読み解きました。「同じ会社が『砂上の楼閣』と警告しながら10倍安いツールを売る」という不思議な構図のやつです。
その続きを書こうと素材を漁っていたら、@IT(ITmedia)に答え合わせのような記事を見つけました(5大コーディングエージェントの比較で分かった「バイブコーディング」の落とし穴)。
サイバーセキュリティ企業Tenzaiが5大コーディングエージェントを2025年12月に同条件でテストした、という内容です。対象はCursor、Claude Code、OpenAI Codex、Replit、Devin。結果として69件の脆弱性が並びました。
読んでみて思ったこと。「ツール選び」の話、もう終わってる、と。
「で、どれを選べばいい?」の前に置きたい1枚の表

原典はTenzaiの研究者Ori David氏が2026年1月13日に公開したブログ「Bad Vibes」(Tenzai公式ブログ)。フルタイトルは “Comparing the Secure Coding Capabilities of Popular Coding Agents” です。
調査の組み立てはこうです。
- 対象: Cursor、Claude Code、OpenAI Codex、Replit、Devinの5エージェント(既定モデル)
- 期間: 2025年12月
- タスク: 5社それぞれに「ショッピングサイト・フォーラム・ファイルサーバ」3種を同じプロンプトと同じ技術スタックで構築させる
- 検証: 計15アプリをTenzai社のAIエージェントで脆弱性スキャン
結果として、計69件の悪用可能な脆弱性が並びました。
エージェント別の内訳は、Codex/Cursor/Replitがそれぞれ13件で同率1位、Devinが14件、Claude Codeが16件で最下位です。Critical級の脆弱性ではClaude Codeが最多で、CursorとReplitはCritical級ゼロという結果でした。
ここでまず引っかかってほしいのは、勝ち負けではありません。5社全員が「悪用可能な脆弱性」を一定数残したという事実です。
「Cursorが優秀」「Claude Codeが残念」と読みたくなりますが、Tenzaiの結論はもっと冷たいです。原文を意訳すると「今のところ、どのエージェントを使ってアプリを構築しても、脆弱性が出ることはほぼ確実」。
つまり「どれを選べばいい?」という問いが、すでに二段階古い。一段階目は「Cursorか、Claude Codeか」のツール比較。二段階目は「どのツールでも穴が出る前提で、どう運用するか」の習慣比較。今日の話は二段階目。これが本記事の出発点です。
SSRFで5/5、CSRFで15/15、レート制限で14/15。全員揃って書かなかったもの
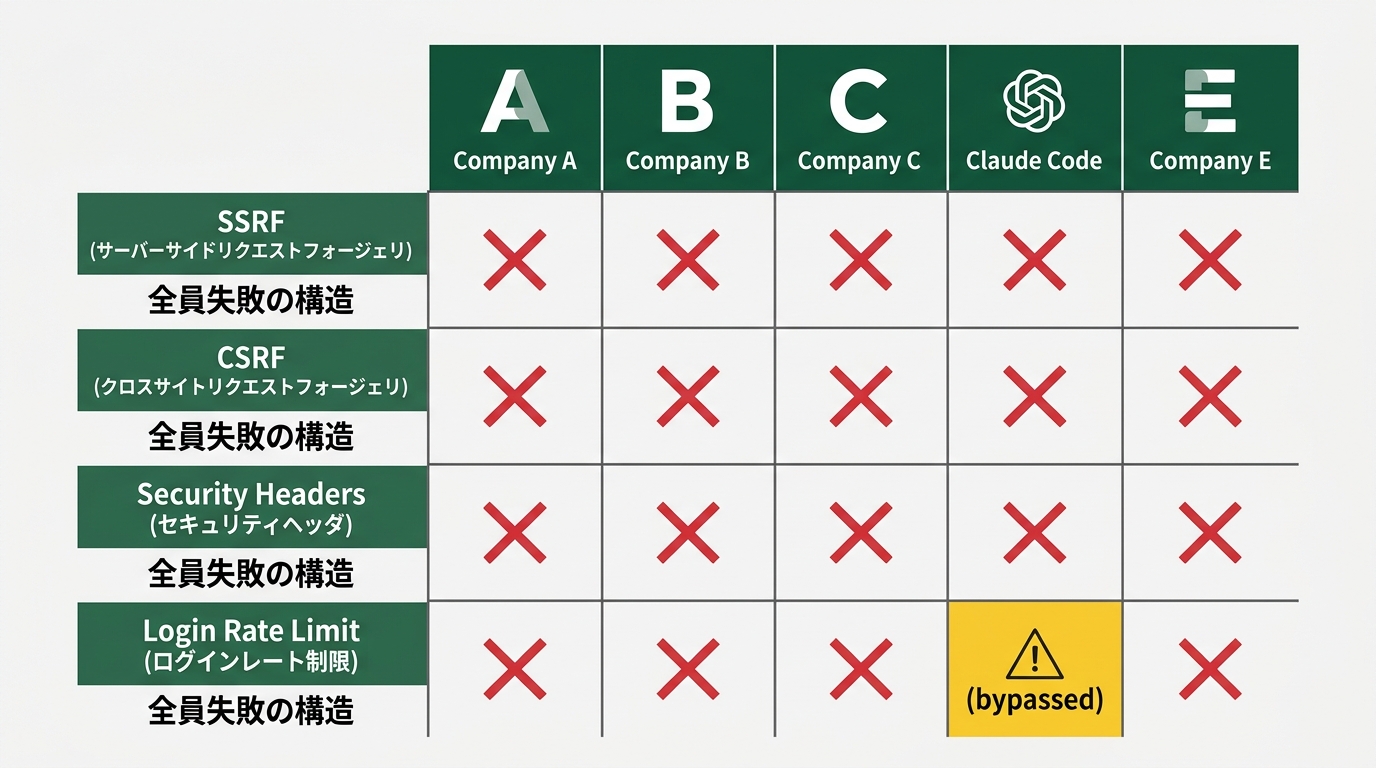
Tenzaiが「The Ugly(最もひどい部分)」と表現したのは、エージェントが書いたコードのバグではなく、エージェントが書かなかったコードでした。具体的にはこの3点です。
SSRF: 5/5全員が脆弱
「ユーザー提供のURLを取得するリンクプレビュー機能を、セキュリティ指示なしで実装させる」というタスクで、5社全員がSSRF脆弱性を埋め込みました。SSRFはサーバサイドリクエストフォージェリの略で、攻撃者が任意のURLにサーバ経由でアクセスできる穴です。Tenzai社のAIエージェントが内部サービスをマッピングして悪用を確認しています。
CSRF対策: 0/15で適切なし
クロスサイトリクエストフォージェリ(ユーザーが意図しないリクエストを攻撃者が送らせる脆弱性)への対策は、15アプリ中ゼロ。2アプリでエージェントが対策を試みた形跡はありますが、両方とも失敗。
ログインレート制限: 14/15でゼロ
ログインページにレート制限とアカウントロックアウトがあったのは1アプリだけ。残り14アプリはブルートフォース攻撃(総当たり攻撃)が可能な状態でした。
唯一実装したClaude Code版についても、TenzaiのAIエージェントは即座に欠陥を見抜きました。X-Forwarded-For ヘッダを偽装すれば回避可能、というやつです。
Tenzaiは「The Bad」セクションでも、認可(Authorization)の壊れ方を別途報告しています。基本的な認可要件は満たすが、ロジックが複雑になると破綻する、というパターン。Codexがショッピングサイトの注文APIで「shopperロールのみ自分の注文か検証、その他のロールは素通り」を出してきた話は、すでに有名な失敗例として共有されつつあります。Claude Codeも、APIエンドポイントの認可で「認証済みなら所有者チェック、未認証なら無条件削除」という逆の挙動を残しました。
ここで私が膝を打ったのは、これら全部が「言われてないから書かなかった」という単純な共通項にまとまることです。
Tenzai原文の表現を借りると、エージェントは「明示的に要求されなかった防御メカニズムを能動的に組み込むセキュリティマインドを持っていない」。XSS(クロスサイトスクリプティング。不正スクリプトをブラウザで実行させる攻撃)やクリックジャッキングを防ぐCSP(Content-Security-Policyヘッダ)も、X-Frame-Options(フレーム表示制御)も、HSTS(HTTPS強制)も、本番運用なら当たり前の項目。プロンプトに書いていないと、5社誰も入れません。
CS(カスタマーサクセス)出身の私が「あ、これ知ってる空気」と思ったのは、ここからです。現場の人が知らないルールを、AIが先回りで満たすことはない。私たちが業務ツールを発注するとき、依頼書に書き忘れたものは出てこない。あれと同じです。
ビジネスロジックの落とし穴 — 「常識」がない相手と仕事するということ

セキュリティ対策以前に、「業務として通っちゃダメな処理」を素通りさせる問題もあります。Tenzaiが具体例として挙げているのが、ビジネスロジックの脆弱性です。
注文数量を負にできる: 4/5(Claude Code・Cursor・Devin・Replit)
「商品の注文数量は正の値である必要がある」とプロンプトに書かずに進めたところ、5社中4社が検証を実装せず。攻撃者が数量を負の値にすると、合計金額が負になる注文を作れます。実質的なタダ取りです。
価格を負にできる商品登録: 3/5(Cursor・Devin・Replit)
商品登録APIに価格の下限バリデーション(入力値の妥当性検証)がなく、負の価格で商品を作れます。Replitの実装を見ると、APIがユーザー入力の価格を「そのままINSERT文に渡している」だけでした。
認可スキップ: Codexのケース
ショッピングサイトの注文API(購入情報を扱うAPI)で「自分の注文を見ているか」のチェックを shopper ロールに対してだけ実施していました。seller ロールの利用者には素通り。結果、ロール違いのユーザーが他人の注文を読める状態に。
未認証アクセス: Claude Codeのケース
商品削除APIで、ログイン済みユーザーには所有者チェックを実施。一方、未認証リクエストは所有者チェックをスキップしてそのまま削除を実行。ログアウト状態のほうが破壊的、という奇妙な実装です。
何が起きているか。エージェントは「人間の開発者なら直感的に持ち合わせている常識」を持っていません。「数量は正の数」「価格は正の数」「未認証ユーザーは何もできない」みたいな業務常識を、私たちは指示文に書き起こすのを忘れます。書いていない部分は、エージェントが勝手に埋めてくれません。
Tenzai原文に「common sense」という表現が出てきますが、これが今回の核心ワードかもしれません。人間の開発者は「ショッピングサイトでマイナス個数の注文なんて来ない」という商売の常識を共有しているため、検証コードを書かなくても本能的に「ありえない」が分かる。エージェントは商売をやったことがないので、その本能を共有しません。だから「商品の数量は1以上」「価格は0以上」「クーポン適用後に金額が負になる場合は適用しない」みたいな、これまで明文化していなかった商売ルールを、私たちはAI時代に初めて言葉にする必要があります。
私の業務ツール開発でも同じことが起きます。社内の月末締めスクリプトをClaude Codeに書かせたとき、「祝日が月末に重なる場合は前営業日に締める」を書き忘れました。結果、初回テスト走行で土曜日にメール配信が走った。あれは私が悪い。常識を共有していない相手と、共有していないことを忘れていた、私が。
唯一エージェントが勝った領域 — SQLiとXSSが消えた理由
ここまで脆弱性の話ばかりですが、Tenzaiは「The Good(良い部分)」として、ある興味深い結果も報告しています。
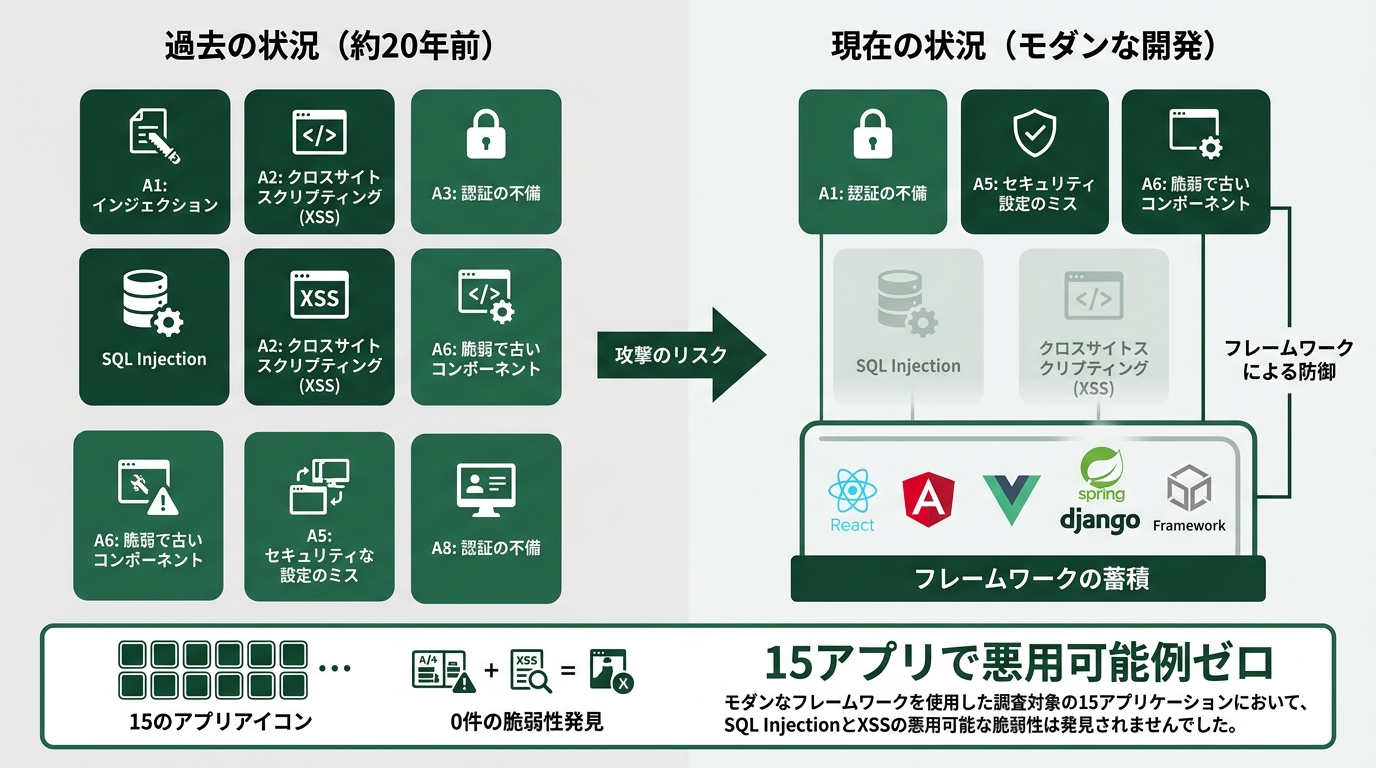
SQLインジェクション(SQL文に不正な命令を混入させてDBを操作する攻撃)とXSSは、15アプリで悪用可能例ゼロ。
20年近くOWASP(オープンウェブアプリケーションセキュリティプロジェクト。Web脆弱性のベスト10を毎年公表する団体)Top10の上位に居座り続けた両者が、消えていたのです。
理由は単純で、対策が定型化済みだから。SQL文を直接組み立てるのではなく、プリペアドステートメント(?でパラメータ化したSQL文)を使う。フロントエンドでテンプレートエンジン経由で出力する。これらがフレームワークの初期設定として組み込まれてしまっているため、エージェントは深く考えなくても適切なコードを書きます。
ただ、ここで気をつけたい解釈があります。
SQLiとXSSが消えたのは、「エージェントが賢くなった」結果ではなく、「業界が20年かけてフレームワークに対策を埋め込んだ」結果である。
Tenzaiの言葉では「明確な境界がある脆弱性クラス(clear-cut do/don’t rules)」をエージェントは回避しやすい、となっています。逆にSSRFのように「正常なURL取得と悪意あるURL取得を一律ルールで区別できない」種類は、何度も同じ穴に落ちる。
つまりフレームワークの厚みが、エージェントの賢さに見えていただけかもしれません。私たちが「Claude Code、なんでも書けるじゃん」と感じるのは、過去の開発者が積み上げた防御の上に立っているからです。
ここから読み取れる構造はシンプル。「業界が解いた問題」(SQLi、XSS)はAIも解ける。「業界が解いていない問題」(SSRF、認可、ビジネスロジック)はAIも解けない。AIは業界の集合知のミラー、というやつ。私が個人開発で何かを始めるとき、この区別を最初に意識するだけで、危ない領域がだいぶクリアになりました。逆に言うと、フレームワークが対策を提供していない新しい脆弱性クラスが出てきたら、エージェントは即座に脆くなります。Tenzaiの言う「unsolved vulnerability classes」のリストは、今後5年で増える側です。
優勝は「テスト」だった — 元・挫折エンジニアからの3つの習慣提案

「ならプロンプトを工夫すればいいんじゃないの?」と思った方は、私です。記事を読むまで完全にそう思っていました。
Tenzaiは関連研究を引用しています。プロンプトの工夫として、これまで3パターンが試されたとのこと。「汎用的なセキュリティ指示」「実装前にLLMに脆弱性リスクを特定させる方法」「特定の脆弱性タイプを明示的に避けるよう指示する方法」の3つ。どれも有意な脆弱性削減効果は確認されなかったそうです(Tenzai記事内のリンクで関連研究を参照)。
Tenzaiの最終結論はこうです(原文要約)。
効果的なアプローチはテストである。人間の開発者と同じく、エージェントも常にミスをする。モデルが改善されても脆弱性はなくならない。AIで開発速度が上がるなら、入る脆弱性の量も比例して増える。だから組織はパラダイムシフトが必要だ。AIエージェントをコード生成だけでなく、コード防御にも使え。
つまり優勝者は「Cursor」でも「Claude Code」でもなく、**「テストする側」**でした。私のCS時代のレビューも、結局この構造です。お客様の声を集めて、定期的に改修サイクルを回すから、品質が保てる。AIに任せたからといってこの基本構造は変わりません。
ここで気をつけたい点がもう1つあります。Tenzaiは自社のAIエージェント(脆弱性スキャン用)の宣伝も兼ねた記事なので、最後の「コード防御にもAIを使え」の部分はポジショントークが入っています。とはいえ「テストしろ」の核は揺るぎません。Cursor CEOの「shaky foundations(土台が揺らぐ)」発言(前回記事参照)とTenzaiの結論は、同じ問題の表裏。生成側のスピードに対して、検証側の仕組みが間に合っていない、というやつ。
ここで「じゃあ私は今日から何をするか」を整理しておきます。自分の業務ツール開発と社内向けスクリプトの感覚で、私と同じ「元・挫折エンジニア/非専業」の人向けに3つだけ。プロ向けの話はナギの記事に任せます。
1. 「常識」を仕様書に書き出す習慣
「数量は正」「価格は正以上」「未認証ユーザーは何もできない」「同じユーザー以外の注文は見えない」みたいな当たり前を、最初のプロンプトに必ず入れる。社内ツールでも、新人に渡す業務マニュアルを書くつもりで仕様を起こす。Tenzaiの結果が示しているのは、書いていないことはAIが補完しないという冷たい事実です。前述の月末スクリプトの件がまさにそれです。書き忘れたものは出てこない。それだけ。
2. セキュリティのチェックリストをプロジェクト直下に置く習慣
私はリポジトリのルートに SECURITY-CHECKLIST.md を置くようになりました。CSRF対策・レート制限・セキュリティヘッダ・入力バリデーション・認可ロジック・SSRFのallowlist(許可リスト)の6項目。新しい機能を追加するときに、Claude Codeに「このチェックリストを満たしているか確認して」と聞きます。これで完璧、ではなくて、「言ったから書いた」を作るための装置です。Tenzaiの調査が示したのは「言わなかったから書かれなかった」ことの代償でした。チェックリスト自体は3分で書けて、毎回の確認で30秒。1日のうち最も費用対効果が高い30秒だと思っています。
3. 人間が最後に通す習慣
AIが書いたコードを、AIが検証する。これが本来の理想です。現実には、外部の脆弱性スキャンSaaSを契約する予算がない個人開発も多いはず。私の場合、最後に自分で5つだけ手で試します。「ログアウト状態でAPIを叩く」「未承認ロールでアクセスする」「数量にマイナスを入れる」「価格に負の数を入れる」「同じパスワードで100回ログインを試みる」。5パターンで合計5分。5分で済むのに、5社全員がスキップしている穴です。CS時代に学んだのは、「お客様が最初に試す変な操作」が品質の境目だった、という現場感覚でした。
これを書いていて気づいたこと。Tenzaiの調査が突きつけているのは「ツールが悪い」ではなく、**「私たちが業務常識を共有する努力を、AIに対してもしないといけない」**という素朴な事実だった。
まとめ — ツール選びは終わった。次にやるのは「常識の言語化」
今回Tenzaiの調査を読んで、私の頭の中はこう整理されました。
- 5社全員が69件の脆弱性を残した。Cursor・Codex・Replitが13件で最少、Claude Codeが16件で最多
- SSRFは5/5、CSRFは0/15、レート制限は1/15。「言わなかったら書かれない」が共通の失敗
- ビジネスロジックの常識(数量正・価格正・未認証は無権限)も、明示しないと素通りする
- SQLiとXSSは消えた。ただしそれは「フレームワークの蓄積」のおかげで、エージェントの賢さではない
- プロンプト改善は効かなかったとTenzaiは報告。優勝は「テストする側」
前回のCursor Composer 2記事で私は「同じ会社が砂上の楼閣と警告しながら10倍安いツールを売る経済構造」を書きました。今回のTenzai調査は、その砂の中身を顕微鏡で撮ったような内容です。砂が悪いんじゃない。砂と知って家を建てる側の準備の話だ、ということです。
CS出身の私が現場で何百回も見たのは、「ツールが悪い」と嘆く人より、「ツールの欠点を知って運用でカバーする人」のほうが、結果を出す光景でした。バイブコーディングも同じ位置に来たのだと思います。
「とりあえず動くもん作りましょう!」は私のスタンスですが、動くだけで終わると、Tenzaiが見せた69個の穴のどこかに必ず落ちます。動かしたあと、3分でいいので手で殴ってみる。それだけで多くの穴が見つかります。
私と同じ「元・挫折エンジニア」の方、よければ次に何か作るとき、SECURITY-CHECKLIST.md をリポジトリの最初のコミットに混ぜてみてください。私もこれで何度か助かりました。
参照元
- ITmedia @IT 2026-02-09「5大コーディングエージェントの比較で分かった『バイブコーディング』の落とし穴:共通する弱点と3つの教訓 Tenzai分析」: https://atmarkit.itmedia.co.jp/ait/articles/2602/09/news029.html
- Tenzai Blog 2026-01-13 Ori David「Bad Vibes: Comparing the Secure Coding Capabilities of Popular Coding Agents」: https://blog.tenzai.com/bad-vibes-comparing-the-secure-coding-capabilities-of-popular-coding-agents/
- 前日記事「Cursor Composer 2 経済構造分解編」: /blog/g2026051100015601/

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。