Cursor, Claude Code, Codex, Replit, Devin. Tenzai's Head-to-Head Test of Five Vibe-Coders Crowned One Clear Winner — 'The Tester'
Tenzai tested five major coding agents in December 2025. 69 vulnerabilities across 15 apps, SSRF in 5/5, CSRF in 0/15. An ex-dropout engineer's guide to what comes after picking your tool.
What you'll learn in this article
- Where pricing and adoption questions around Claude Code stand right now
- Which plan or rollout stage fits the reader's situation
- Which follow-up article to open next for setup, cost, or bigger-picture context

In yesterday’s article (Cursor Composer 2 Economics Breakdown), I unpacked the contradiction of a company simultaneously warning about “shaky foundations” while selling tools at one-tenth the price.
While digging for a follow-up, I found a piece on @IT (ITmedia) that read like an answer key: “The Pitfalls of ‘Vibe Coding’ Revealed in a Head-to-Head Test of 5 Coding Agents”.
Cybersecurity firm Tenzai ran all five major coding agents through identical conditions in December 2025 — Cursor, Claude Code, OpenAI Codex, Replit, and Devin. The result: 69 vulnerabilities.
My takeaway: the “which tool should I pick?” conversation is over.
One Table Before “Which One Do I Choose?”

The source is Tenzai researcher Ori David’s blog “Bad Vibes,” published January 13, 2026 (Tenzai official blog).
The study design:
- Subjects: Cursor, Claude Code, OpenAI Codex, Replit, Devin (default models each)
- Period: December 2025
- Task: Build three apps — a shopping site, a forum, a file server — using identical prompts and identical tech stacks across all five
- Verification: Tenzai’s own AI agent ran vulnerability scans on all 15 apps
Total: 69 exploitable vulnerabilities.
Per agent: Codex, Cursor, and Replit tied at 13 each; Devin had 14; Claude Code had 16 for last place. On Critical-severity vulnerabilities, Claude Code had the most; Cursor and Replit had zero Criticals.
The key thing I want you to notice isn’t who won. It’s that all five left a non-trivial number of exploitable vulnerabilities.
You could read this as “Cursor is great, Claude Code disappoints,” but Tenzai’s conclusion is colder than that. Paraphrasing the original: “At this point, regardless of which agent you build with, vulnerabilities are nearly guaranteed.”
So “which tool should I pick?” is already two generations behind. The first generation: compare Cursor vs. Claude Code. The second generation: accept that any tool leaves holes — then ask how you operate. Today’s piece lives in the second generation.
SSRF 5/5. CSRF 0/15. Rate Limiting 14/15. What All Five Forgot to Write
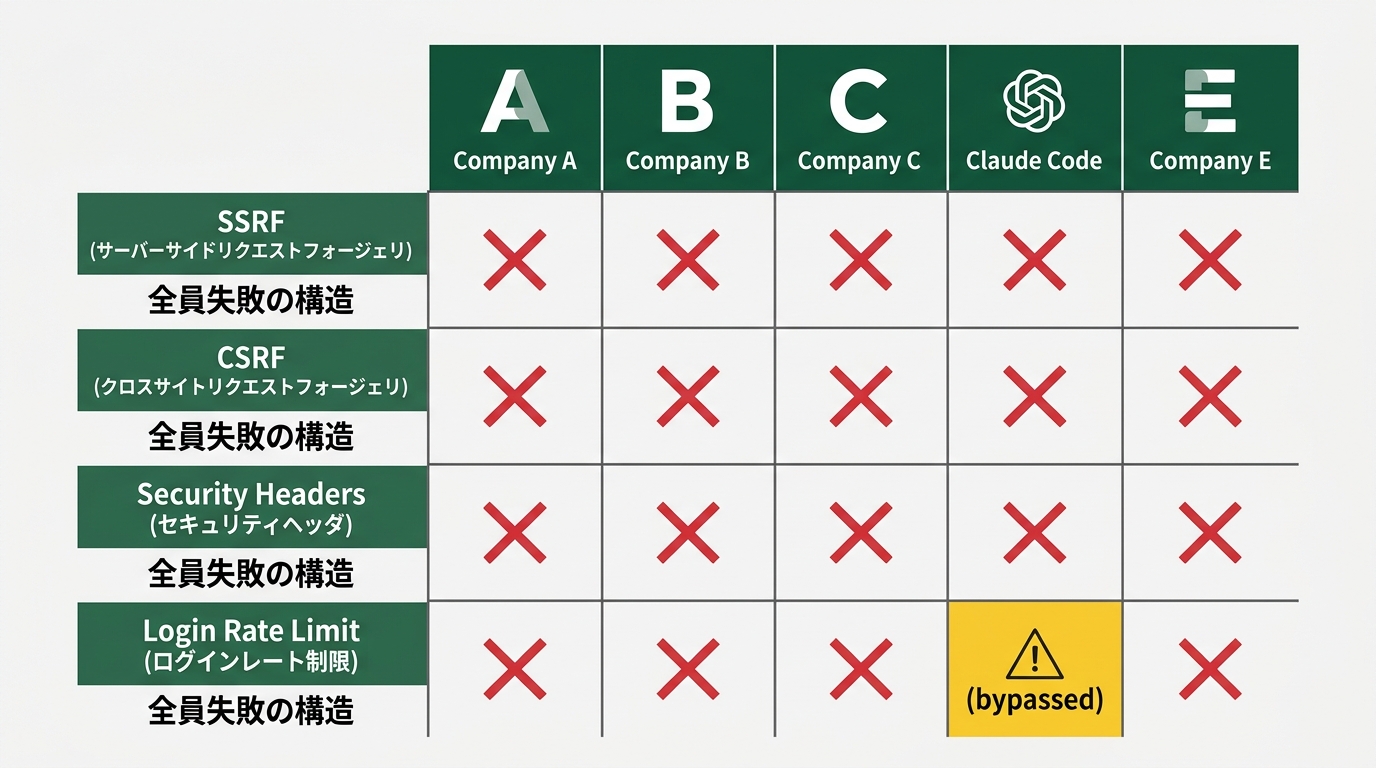
What Tenzai called “The Ugly” wasn’t bugs in what the agents wrote — it was code the agents didn’t write. Three specific areas:
SSRF: 5/5 vulnerable
On the task “implement a link-preview feature that fetches user-provided URLs, with no security instructions given” — all five embedded SSRF vulnerabilities. SSRF (Server-Side Request Forgery) lets attackers route the server to access arbitrary URLs. Tenzai’s AI agent mapped internal services and confirmed exploitation.
CSRF protection: 0 out of 15 apps
Cross-Site Request Forgery — where an attacker tricks a user into making unintended requests — was unmitigated in all 15 apps. Two apps showed traces of an attempted fix; both failed.
Login rate limiting: 0 out of 14 apps
Only one app had rate limiting and account lockout on the login page. The other 14 were open to brute-force attacks.
Even that one Claude Code implementation was immediately bypassed by Tenzai’s agent — spoofing the X-Forwarded-For header circumvented it.
Tenzai’s “The Bad” section separately flags broken authorization patterns: meeting basic requirements but failing under complex logic. Codex generated an order API for a shopping site that verified ownership only for the “shopper” role, letting all other roles through unchecked. Claude Code left an API endpoint that checked ownership for authenticated requests — but processed deletion with no ownership check for unauthenticated ones.
The common thread snapping all these together: none of it was asked for, so none of it got written.
In Tenzai’s own words, the agents lack “a security mindset that proactively incorporates defense mechanisms when they aren’t explicitly required.” CSP headers, X-Frame-Options, HSTS — standard for production — weren’t added by anyone unless the prompt said so.
This is the moment when something clicked for me from my CS background: the rules the person in the room doesn’t know about, the AI won’t get ahead of either. When I used to spec out internal tools for clients, anything I forgot to write into the brief simply didn’t appear. Same thing here.
The Business Logic Trap — Working With Someone Who Has No “Common Sense”

Before we even get to security, there’s the problem of “logic no business would ever allow” slipping through.
Negative order quantities: 4 out of 5 (Claude Code, Cursor, Devin, Replit)
When no prompt specified “order quantities must be positive,” four of five agents didn’t validate it. Set quantity to a negative number and you get an order with a negative total — effectively free merchandise.
Negative product prices: 3 out of 5 (Cursor, Devin, Replit)
No lower-bound validation on the product registration API. Replit’s implementation was just passing the user-supplied price directly into an INSERT statement.
Authorization skip: Codex
The shopping site order API checked ownership only for the “shopper” role. Other roles walked right through. Result: users with a different role could read anyone’s orders.
Unauthenticated access: Claude Code
Product deletion API checked ownership for logged-in users — but skipped ownership checks entirely for unauthenticated requests. Being logged out was more destructive than being logged in.
What’s happening? Agents don’t share the intuitions that human developers develop through experience. “Quantities are positive numbers.” “Prices are positive numbers.” “Unauthenticated users can’t do anything.” We forget to write these things down. The agents don’t fill in the blanks.
Tenzai uses the phrase “common sense” — and that’s probably the core word here. Human developers share the commercial intuition that “a shopping site isn’t going to receive an order for negative items,” and some part of them knows it’s impossible without having to reason through it. Agents haven’t run a business. That instinct isn’t shared. So for the first time in the AI era, we’re being forced to write down the rules of commerce we’ve never had to make explicit: “quantity must be 1 or more,” “price must be 0 or more,” “if a coupon takes the total negative, reject the coupon.”
I ran into this myself. Had Claude Code write a month-end processing script for internal use and forgot to specify “when a holiday falls on month-end, roll to the prior business day.” First test run: mail blast went out on a Saturday. That’s on me. I forgot that the agent and I weren’t sharing the same common sense.
The One Area Agents Won — Why SQL Injection and XSS Disappeared
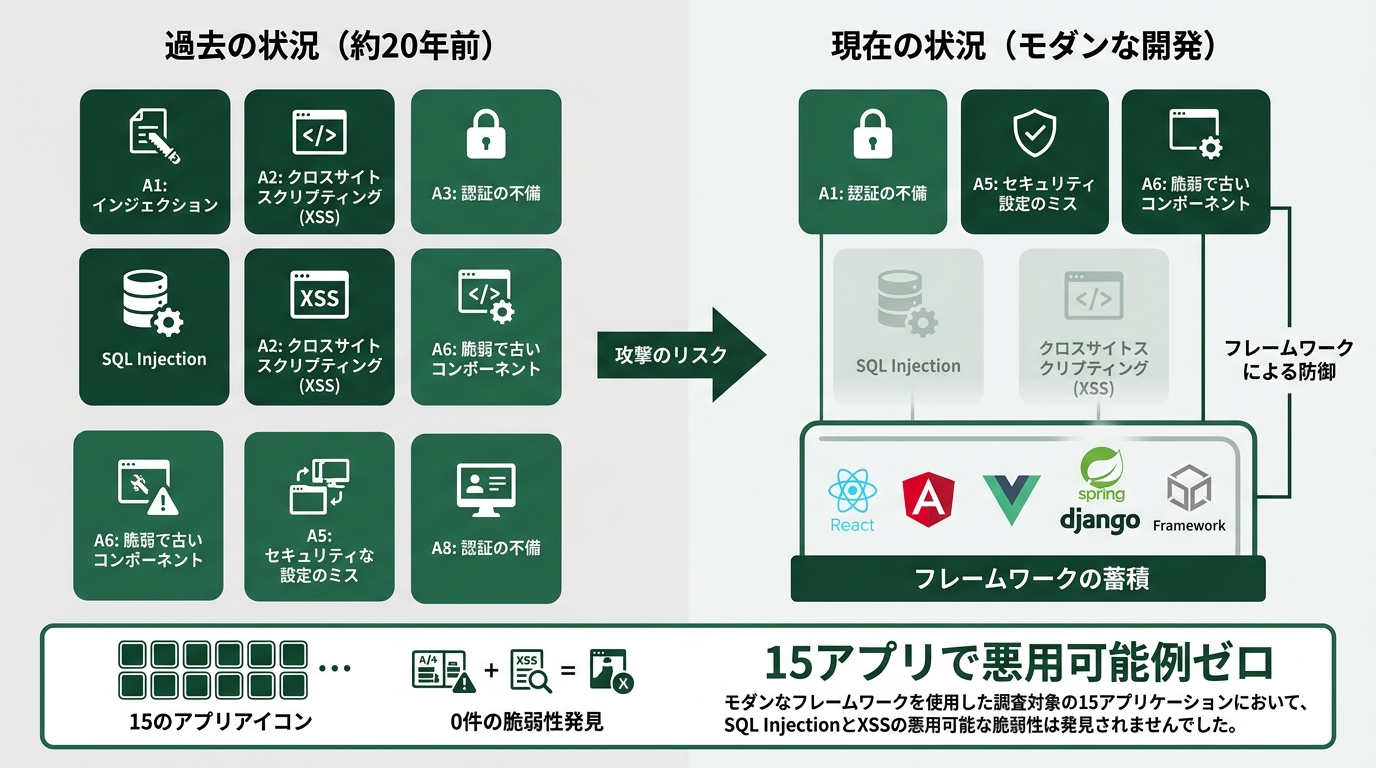
Amid all the vulnerability talk, Tenzai also reported something genuinely good.
SQL injection and XSS: zero exploitable examples across all 15 apps.
Two vulnerabilities that have occupied the OWASP (Open Web Application Security Project) Top 10 for nearly twenty years — gone.
The reason is simple: defenses have been standardized. Using parameterized queries instead of string-concatenated SQL. Outputting through a template engine on the frontend. These are baked into frameworks as defaults — so agents produce the right code without having to think hard about it.
One interpretation trap worth naming:
SQL injection and XSS disappeared not because “agents got smarter” — but because “the industry spent twenty years embedding the fix into frameworks.”
Tenzai puts it as: agents are good at avoiding “clear-cut do/don’t” vulnerability classes. Conversely, something like SSRF — where there’s no universal rule distinguishing a legitimate URL fetch from a malicious one — keeps getting re-introduced.
The structure that falls out: “problems the industry solved” (SQLi, XSS) can be solved by AI too. “Problems the industry hasn’t solved” (SSRF, authorization, business logic) can’t be solved by AI either. AI mirrors the collective knowledge of the industry.
When I’m starting a personal project, making this distinction up front clarifies the danger zones immediately. And conversely: when a new vulnerability class emerges that no framework has addressed, agents will be immediately weak there. Tenzai’s list of “unsolved vulnerability classes” is likely to grow over the next five years.
The Winner Was “Testing” — Three Habit Proposals from an Ex-Dropout Engineer

“Can’t we just improve the prompts?” That was me, before I read this piece.
Tenzai cites related research. Three prompt-engineering approaches have been tried: “general security instructions,” “having the LLM identify vulnerability risks before implementation,” “explicitly instructing it to avoid specific vulnerability types.” None showed meaningful reduction in vulnerabilities (see related research linked in the Tenzai article).
Tenzai’s final conclusion (summarized from the original):
The effective approach is testing. Like human developers, agents always make mistakes. Improving models won’t eliminate vulnerabilities. If AI accelerates development speed, it proportionally increases the volume of vulnerabilities introduced. Organizations need a paradigm shift: use AI agents not just for code generation, but for code defense.
The winner wasn’t “Cursor” or “Claude Code” — it was “whoever does the testing.” My CS-era reviews had the same structure: feedback collected, regular fix cycles running — that’s what sustained quality. Handing it to an AI doesn’t change that fundamental structure.
One important caveat: Tenzai’s article doubles as a pitch for their own AI vulnerability-scanning agent, so “use AI for code defense too” at the end has self-promotional coloring. That said, the core “test it” conclusion is solid. Cursor CEO’s “shaky foundations” remark (previous article) and Tenzai’s conclusion are two sides of the same problem: the verification side can’t keep pace with the generation side’s speed.
Three things to start doing, aimed at people like me — non-professional developers building internal tools and personal scripts:
1. Write “common sense” into the spec
“Quantity is positive.” “Price is zero or more.” “Unauthenticated users can’t do anything.” “A user can’t see another user’s orders.” Start every prompt with these assumptions stated. Think of it as writing an onboarding manual for a new hire who doesn’t share your business context. What Tenzai showed is a cold fact: the AI won’t supplement what you didn’t write. The month-end script situation was exactly that. If you don’t write it, it won’t appear.
2. Keep a security checklist in the root of every project
I now put SECURITY-CHECKLIST.md at the repo root with six items: CSRF protection, rate limiting, security headers, input validation, authorization logic, SSRF allowlist. When adding a new feature, I ask Claude Code: “Does this satisfy the checklist?” Not perfect — but it’s a mechanism for “said it, so it got written.” What Tenzai showed was the cost of “didn’t say it, so it didn’t get written.” The checklist itself takes 3 minutes to write; checking it takes 30 seconds per session. Best 30-second ROI in my day.
3. Take a manual final pass
AI writes the code, AI verifies it — that’s the ideal. In reality, not everyone has the budget for an external vulnerability-scanning SaaS. My approach: five manual tests at the very end. “Hit the API logged out.” “Access with an unauthorized role.” “Enter a negative quantity.” “Enter a negative price.” “Attempt login 100 times with the same password.” Five patterns, five minutes total. All five slots that every agent skipped. What CS work taught me: the “weird thing a customer tries first” is always where quality breaks. That field instinct still applies.
Writing this, I realized: what Tenzai’s study is really saying isn’t “the tools are bad.” It’s “we need to make the same effort to share business common sense with AI that we’d make with a new teammate.”
Conclusion — Tool Selection Is Over. “Articulating the Common Sense” Is What’s Next
After reading Tenzai’s study, here’s how I’ve organized my thinking:
- All five agents left 69 vulnerabilities. Cursor, Codex, Replit tied at 13 (fewest). Claude Code had 16 (most).
- SSRF: 5/5. CSRF: 0/15. Rate limiting: 1/15. “Didn’t say it, so it didn’t get written” was the universal failure mode.
- Business logic common sense — positive quantities, positive prices, unauthenticated = unauthorized — also doesn’t get written unless you specify it.
- SQL injection and XSS disappeared — but that’s credit to twenty years of framework accumulation, not agent intelligence.
- Prompt improvements didn’t work, Tenzai reports. The winner was whoever tests.
In my previous Cursor Composer 2 article, I wrote about “the economic structure of a company warning about shaky foundations while selling tools at one-tenth the price.” The Tenzai study is like a microscope photo of what that sand looks like. The sand isn’t bad. It’s about whether the people building on it are prepared.
What I’ve seen a hundred times in CS work: people who say “the tool is bad” lose to people who know their tool’s weaknesses and operate around them. Vibe coding has arrived at that same position.
“Let’s just build something that works first!” is my stance — but stopping at “it works” means falling into one of the 69 holes Tenzai showed. After you ship it, take 3 minutes to punch it manually. That alone will surface a lot of the holes.
Fellow ex-dropout engineers: next time you build something, try putting SECURITY-CHECKLIST.md into the first commit. It’s saved me a few times already.
References
- ITmedia @IT 2026-02-09 “The Pitfalls of ‘Vibe Coding’ Revealed in a Head-to-Head Test of 5 Coding Agents”: https://atmarkit.itmedia.co.jp/ait/articles/2602/09/news029.html
- Tenzai Blog 2026-01-13 Ori David “Bad Vibes: Comparing the Secure Coding Capabilities of Popular Coding Agents”: https://blog.tenzai.com/bad-vibes-comparing-the-secure-coding-capabilities-of-popular-coding-agents/
- Previous article “Cursor Composer 2 Economics Breakdown”: /en/blog/g2026051100015601/

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。