The Company That Warned You About Vibe Coding Just Launched a 10x Cheaper Tool for It. Here's the 3-Layer Economic Logic.
Cursor's CEO called vibe coding 'shaky foundations' at Fortune Brainstorm AI. Three months later, the same company launched Composer 2 at ~10x cheaper than Claude Opus 4.6. Price, compaction RL, and cache economics: here's why the apparent contradiction holds together — and what to watch.
What you'll learn in this article
- The key point to grasp before reading the full article
- How the issue changes the way developers should work next
- Which follow-up article is worth opening next
Some combinations look like contradictions.
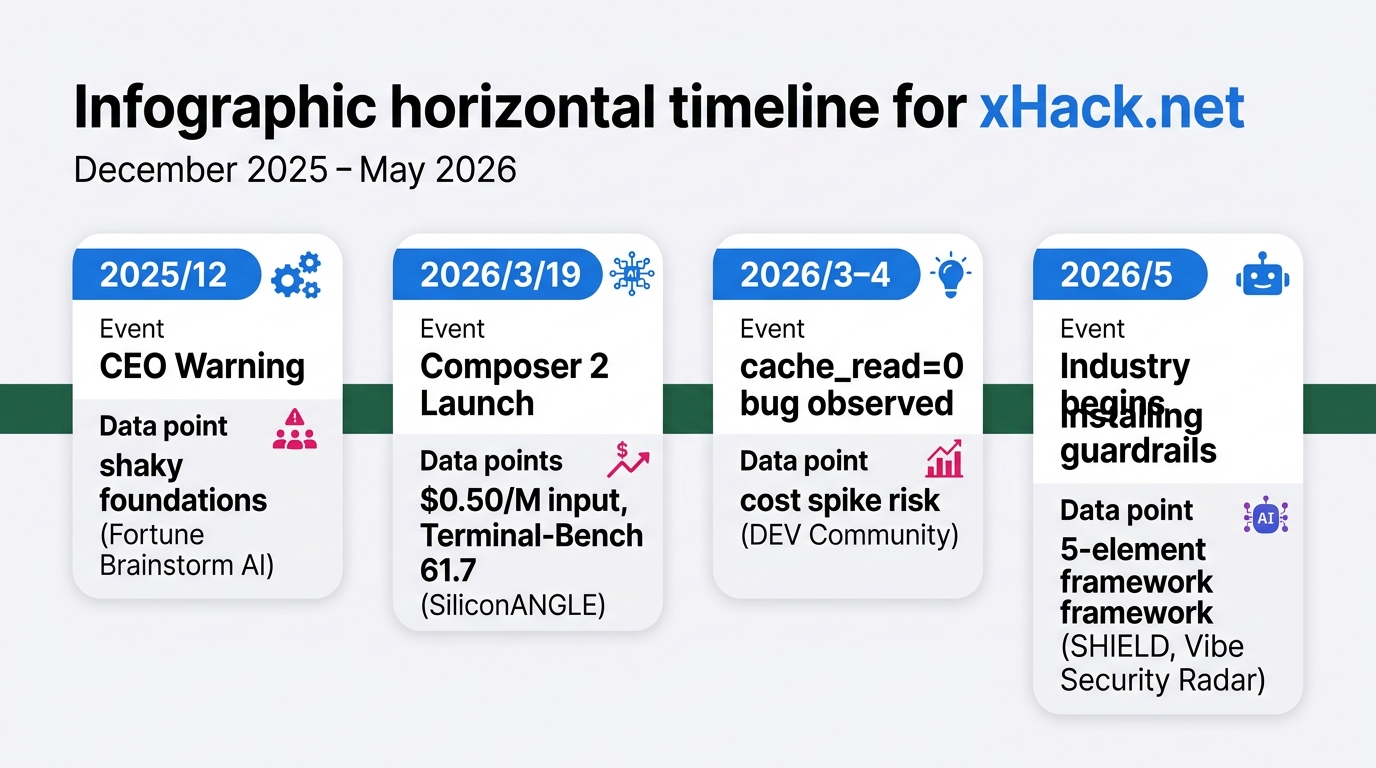
Yesterday, I wrote about Cursor CEO Michael Truell calling vibe coding “shaky foundations” at Fortune Brainstorm AI in December 2025 (previous article here). “Close your eyes, don’t read the code, let AI build you a house of cards. It’ll collapse eventually.” A rare case of a CEO publicly warning against the primary use case of his own product.
Then on March 19, 2026, that same Cursor announced “Composer 2” — a coding model priced at $0.50/M input tokens and $2.50/M output tokens. Roughly 10x cheaper than Claude Opus 4.6. An 86% price cut from Composer 1.5 ($3.50/$17.50). The man who issued the warning just handed out the accelerator.
Three months passed between the warning and the announcement. Today, in May 2026, the industry is starting to build guardrails. Palo Alto Networks published the SHIELD governance framework with five components. Georgia Tech launched the Vibe Security Radar, tracking CVEs: 18 in the second half of 2025, 56 in Q1 2026, 35 in March alone — a sharply rising curve by quarter. That’s the context in which Composer 2 arrived.
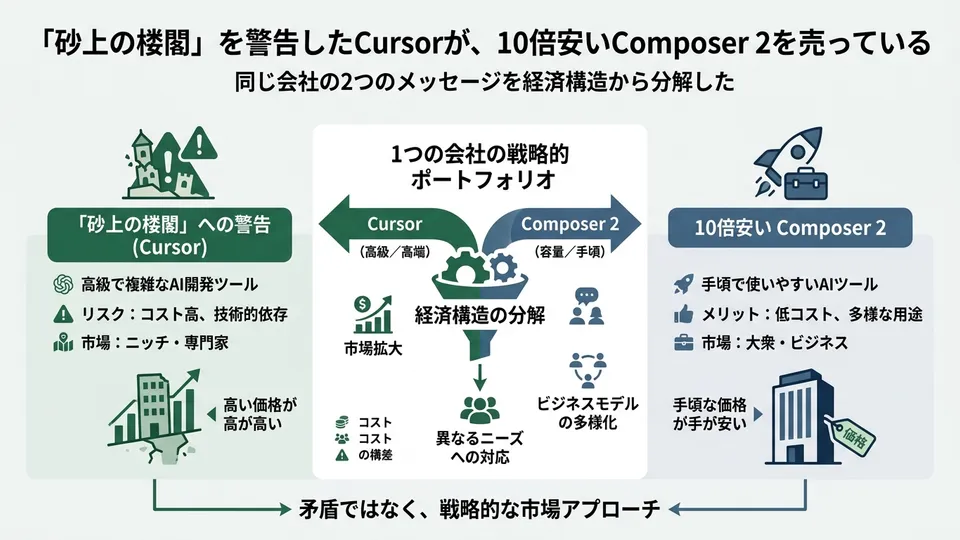
Is this a contradiction, or a coherent strategy? After reading both pieces closely, I landed on: coherent — with conditions attached. Today’s article breaks Composer 2 into three layers — price, technology, and risk — and reads it from there.
What Does “10x Cheaper” Actually Mean? Three Numbers in Parallel
“10x cheaper” alone doesn’t make a business case. You need to look at what got cheaper and what didn’t.
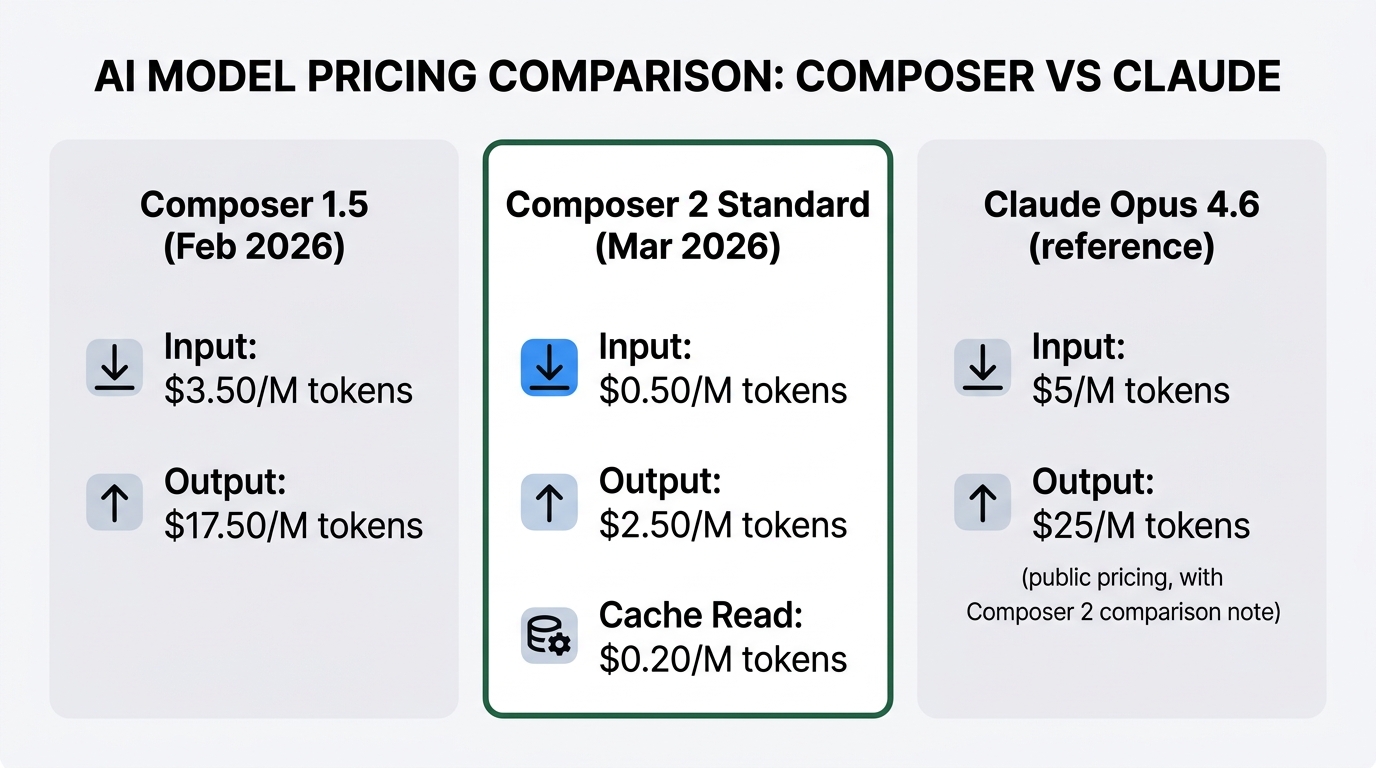
Composer 2 Standard is priced at $0.50/M input and $2.50/M output. The previous generation, Composer 1.5, was $3.50/M input and $17.50/M output — an 86% cut inside a single company in under a month. That kind of price compression is rare.
To broaden the comparison: stacked against Anthropic’s public Claude Opus 4.6 pricing, Composer 2’s input tokens come in at roughly one-tenth. VentureBeat’s coverage used the same ratio. Output tokens follow similar proportion. The vendor pitch is: benchmark scores above Opus 4.6 on SWE-bench Multilingual and Terminal-Bench 2.0, at one-tenth the price.
Let’s look at the benchmarks more carefully. On Terminal-Bench 2.0, Composer 2 scores 61.7 versus Claude Opus 4.6’s 58.0 — but GPT-5.4 is at 75.1, so it’s not leading the field. SWE-bench Multilingual: 73.7. CursorBench (Cursor’s own benchmark): 61.3. Worth noting — CursorBench is designed by Cursor itself, which creates a potential home-team advantage. I weight the external SWE-bench and Terminal-Bench numbers more heavily.
Third number: context window. Composer 2 handles 200K tokens — on par with Claude Opus 4.6 and at the current standard for serious coding agents. “Cheaper, beats Opus on external benchmarks, same context length” — that’s the surface pitch.
Three caveats, though. First: Composer 2 is built on Kimi K2.5 (Moonshot AI’s open model) with continued pretraining and reinforcement learning. It’s not a fully proprietary model — it’s an open model with added training on top. Second: benchmark wins and production wins are different things. Third: the cache mechanism I’ll describe next makes “effective cost” swing substantially. Cursor’s “10x cheaper” is a nominal figure that assumes cache is working correctly.
Compaction-in-the-Loop RL: The Technology Behind the Price
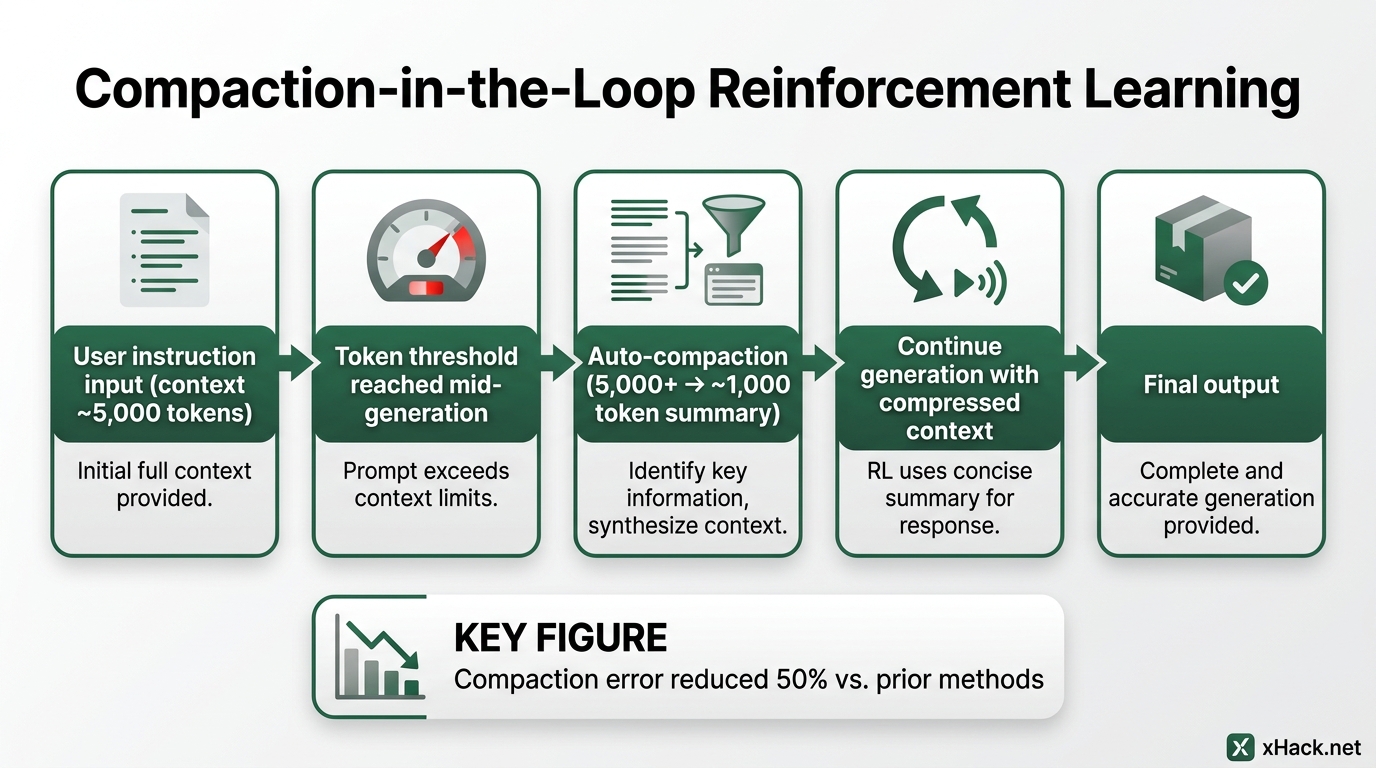
There’s one technology inside the “cheaper” that’s worth pulling out.
In Cursor’s official blog post (cursor.com/blog/composer-2), they describe a training method called “compaction-in-the-loop reinforcement learning” — reinforcement learning with context compression baked into the loop itself.
What problem does it solve? In agentic coding, context balloons over long tasks. Opening files, running tests, absorbing error logs, trying fixes — a single session can easily exceed 5,000 tokens. Most agents handle this by summarizing before continuing, but every summary degrades the information. This is called compaction error.
Cursor addressed this at training time. When a generation sequence hits a token length threshold, the model itself compresses its own context down to roughly 1,000 tokens and continues generating from that compressed state. The three-step cycle of “compress, continue, evaluate” is embedded in the training loop. Result: Cursor claims a 50% reduction in compaction error versus prior methods (source: Cursor official blog).
My read: this is the mechanism that makes “run long tasks cheaply” viable. If context inflates to 100K tokens but the model internally operates on 1K compressed states, compute costs don’t scale linearly. This is part of the economic foundation that makes the 10x price cut possible.
One failure mode to know in advance: Compaction-in-the-Loop assumes it can compress well. On tasks that genuinely require the full long-form document — think: writing code while referencing a 50-page spec, or diagnosing a massive log file paragraph by paragraph — compression can become the bottleneck. “200K token context support” and “effective context quality” are different claims.
From a CS perspective: this technical choice is the backstage work that enables the headline price drop. Reading the price sheet as “they just lowered prices” misses how tightly technology and pricing are linked here.
The Cache Economics Trap — What the cache_read=0 Bug Reveals
From here I’m mixing what Cursor has officially published with observations from the developer community. I’ll separate the two explicitly at the end of the section.
Composer 2’s “10x cheaper” is premised on caching working correctly. Like Anthropic and others, Composer 2 has a cheaper cache-read tier: $0.20/M input on Standard, $0.35/M on Fast. For work that sends the same context repeatedly — like continuous editing inside a coding session — costs drop sharply after the first pass.
The problem is what happens when that cache breaks.
A developer known as toyama0919 on DEV Community reported an observation from late March to early April 2026: “cache_read counts of zero” on Composer 2 Standard. The implication was that a backend bug caused requests that should have been cache hits to be counted as fresh input and charged at full rate. Instead of $0.20/M for cache reads, those calls would have billed at $0.50/M — for an extended window of time.
Here’s the cost math. In a continuous session where the same context is referenced 10 times: normally, the first pass is $0.50/M and the remaining nine are $0.20/M, giving an effective rate around $0.23/M. Under the bug scenario, all 10 passes bill at $0.50/M — more than doubling the effective rate. Users running long agentic sessions may have received higher-than-expected bills during this period.
[Scope of verification] The cache_read=0 incident above is sourced primarily from toyama0919’s community observation on DEV Community. I was unable to find a corresponding incident record on Cursor’s official status or incident page. Treat the “bug existed” claim as community-sourced information. That said, the cost impact mechanism — what happens to billing when cache reads get counted as new input — holds as a matter of how the pricing structure works. The case for monitoring doesn’t change regardless.
If you’re running Composer 2 in production, build in a habit of checking cache_read figures in your billing log weekly. This isn’t “don’t use Cursor.” It’s: if you’re designing operations around “10x cheaper,” monitoring cache behavior needs to be part of the design.
Holding Warning and Acceleration Together — Cursor’s Two-Front Strategy
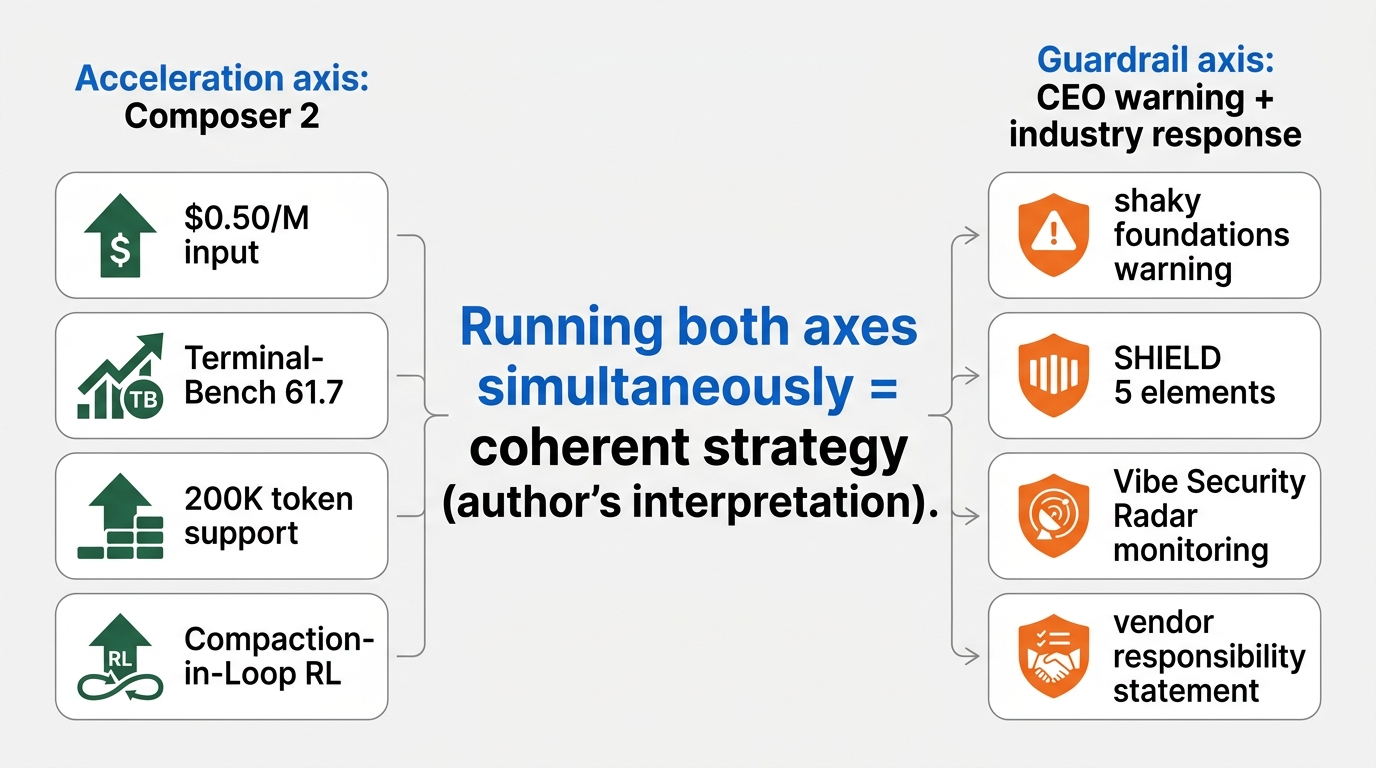
Now I can connect the three layers — price, technology, cache — back to the original question.
“Is it a contradiction for the person who warned you to then release the accelerator?” My answer: coherent, with conditions. Everything that follows is my interpretation.
[Confirmed facts] Cursor officially announced Composer 2 on March 19, 2026 (SiliconANGLE coverage). Truell publicly called vibe coding “shaky foundations” at Fortune Brainstorm AI in December 2025 (Fortune reporting). These are from primary sources. Cursor’s ~$2B ARR and ~$29.3B valuation are figures from press reporting (Fortune, December 2025) — not official disclosures.
[Author’s interpretation] The following three reasons are my analysis built on the above facts.
Why I read this as coherent — three reasons.
First: Cursor’s strategy, as I read it, isn’t “restrict how people use the tool.” It’s “accelerate the product, and let the guardrails get built by a separate channel.” SHIELD-type governance, Vibe Security Radar-type monitoring — these can’t be built by Cursor alone. Truell’s warning can be read as a message to the industry: “You all need to build the guardrails, because we’re not slowing down.”
Second: Composer 2’s technical design — compaction-in-the-loop — is built to run long tasks cheaply. At its core, I see this as designed for users who read their code while using it. A user who doesn’t read code and uses Composer 2 can now build a larger, faster house of cards. The brake isn’t in the technology; it lives in operations and education. Cursor went all-in on the price cut, and delegated the brake to the outside.
Third: competition. Claude Opus 4.6, GPT-5.4, Devin, Aether — the coding agent market is fierce as of 2026. The option of “warn but don’t release the accelerator” means losing market share within six months. My read: “accelerate, and keep issuing warnings” is a two-front strategy.
That said: this coherence is conditional. The condition is that the guardrail side gets built in time. The Vibe Security Radar CVE count — 56 in Q1 2026, 35 in March alone — suggests it might not be. Cursor is betting on the pace of guardrail development.
From a CS perspective: this is the classic structure of “profit from the product, solve the industry problem with collective intelligence.” Not a moral judgment — a realistic business call. What matters for us as practitioners is recognizing that we’re currently on one side of that bet.
Three Moves for Individual Developers This Week — Cost Measurement, Cache Monitoring, Switch-Cost Estimation

For anyone who’s read this far — three practical moves you can make this week. You don’t have to do all three. Just ① is enough to reduce the chance of billing shock six months from now.
① Check cache_read figures in your billing log weekly (5 minutes)
Pull up Cursor’s admin panel or API usage logs and look at cache_read-related numbers. Do a visual check weekly. If you see zeros running for several consecutive weeks, or an unusually low week, it may mean the backend cache counting is broken. For pricing models that are “cache-dependent,” this monitoring is the highest-leverage protection you can add. As the community observation above shows, users can potentially detect anomalies before the vendor does.
② Run the same task through Composer 2 and another model in parallel (30 minutes)
Pick one coding task you use regularly and run the same prompt through both Composer 2 and Claude Opus 4.6 (or your comparison of choice). Record three dimensions: time, output token count, and output quality. Even one measurement gives you a real number to hold against the vendor’s “10x cheaper” claim in your actual workload. In my experience, benchmark values and real-workload costs can diverge by 2x or more.
③ Estimate switch cost: can you move to another model in 1 hour? (60 minutes)
This one is insurance. If you build operations tightly around Composer 2, a price change or spec change from Cursor can lock you in. Now, before that happens: spend an hour mapping what you’d need to switch to another model (Claude, GPT, Devin, etc.). Prompt structure compatibility, context management differences, billing recalculation. You won’t have a complete migration plan in one hour — but having the sense that “I can move if I need to” changes your decision-making posture.
Priority order: ① first, then ②, then ③. ① takes 5 minutes but has the highest ROI. ② is an investment in real data. ③ is a preventive measure before lock-in deepens.
Summary
- Cursor CEO Michael Truell warned at Fortune Brainstorm AI (December 2025) that vibe coders were “building on shaky foundations.” The same Cursor launched Composer 2 on March 19, 2026, pricing it at roughly 10x cheaper than Claude Opus 4.6.
- Composer 2’s “10x cheaper” holds across three layers: list pricing ($0.50/M input, $2.50/M output), embedded technology (compaction-in-the-loop RL, 50% reduction in compaction error — per Cursor official blog), and cache economics.
- The cache_read=0 incident from late March–early April is sourced from community observation (DEV Community, toyama0919) — not confirmed via Cursor’s official incident log. That said, the cost impact mechanism (effective rate doubling when cache reads bill as fresh input) holds as a property of the pricing structure.
- Three reasons I read “warning plus acceleration” as coherent (market constraint; technical design; competitive landscape) are my interpretations. That coherence is conditional on “the guardrail side getting built in time.”
- Three moves for individual developers this week: ① weekly billing log cache_read check (5 min), ② Composer 2 vs. another model parallel measurement (30 min), ③ switch cost estimation (60 min). Start with ①.
Coming from a CS background, when I call a seemingly contradictory strategy “coherent,” I always check the conditions. Cursor’s coherence is conditional on the guardrails keeping pace. As long as you’re monitoring on your end, riding this bet is rational. Watching from the sidelines is equally rational.
The difference comes down to one thing: whether you have real measurement data on your own workload. If you do, you can decide fast. If you don’t — start with ①. Five minutes this week.
References
- Fortune “Michael Truell at Brainstorm AI 2025: vibe coders are building on shaky foundations” (2025-12): primary URL in previous article /en/blog/g2026051000015301/
- SiliconANGLE “Vibe coding startup Cursor launches programming-optimized Composer 2 model” (2026-03-19): https://siliconangle.com/2026/03/19/vibe-coding-startup-cursor-launches-programming-optimized-composer-2-model/
- Cursor official blog “Introducing Composer 2”: https://cursor.com/blog/composer-2
- DEV Community (toyama0919) “Cursor Composer 2: The Cache Economy Behind a 10x Cheaper Coding Agent” (community observation): https://dev.to/toyama0919/cursor-composer-2-the-cache-economy-behind-a-10x-cheaper-coding-agent-15cj
- VentureBeat “Cursor’s new coding model Composer 2 is here: It beats Claude Opus 4.6 but still trails GPT-5.4”: https://venturebeat.com/technology/cursors-new-coding-model-composer-2-is-here-it-beats-claude-opus-4-6-but
- The New Stack “Cursor’s Composer 2 beats Opus 4.6 on coding benchmarks at a fraction of the price”: https://thenewstack.io/cursors-composer-2-beats-opus-46-on-coding-benchmarks-at-a-fraction-of-the-price/
- DataCamp “Composer 2: Benchmarks, Pricing, and How It Compares”: https://www.datacamp.com/blog/composer-2
- Cursor ARR ~$2B, valuation ~$29.3B: Fortune (2025-12) and industry press reporting (not official company disclosures)
- Cursor Technical Report “Composer 2 Technical Report” (Kimi K2.5 base, compaction-in-loop RL details): https://cursor.com/blog/composer-2-technical-report
※ Palo Alto Networks SHIELD and Georgia Tech Vibe Security Radar primary sources are in the previous article /en/blog/g2026051000015301/.

正直、一度エンジニアは諦めました。新卒で入った開発会社でバケモノみたいに優秀な人たちに囲まれて、「あ、私はこっち側じゃないな」って悟ったんです。その後はカスタマーサクセスに転向して10年。でもCursorとClaude Codeに出会って、全部変わりました。完璧なコードじゃなくていい。自分の仕事を自分で楽にするコードが書ければ、それでいいんですよ。週末はサウナで整いながら次に作るツールのこと考えてます。